The Evolving Landscape of Large Language Models: A 2023 Survey
Introduction
The field of artificial intelligence has witnessed remarkable growth since the release of GPT-3 in 2020, with Large Language Models (LLMs) emerging as powerful tools capable of generating human-like text, solving complex problems, and assisting in various tasks. This explosion in LLM development has created a diverse ecosystem of models with varying architectures, capabilities, and specializations.
This article surveys notable recent models and datasets, examining their unique contributions to the AI landscape and what they reveal about the future direction of language model development. From open-source alternatives challenging proprietary giants to specialized models pushing the boundaries of what AI can accomplish in specific domains, we’ll explore how the LLM ecosystem continues to evolve at a breathtaking pace.

General-Purpose Foundation Models
Falcon 40B
Developer: Technology Innovation Institute (TII)
Architecture: Causal decoder-only
Falcon 40B represents one of the largest openly released foundation models with 40 billion parameters. What makes Falcon particularly noteworthy is its focus on efficient training and inference—achieving performance comparable to larger models while requiring fewer computational resources.
The emergence of Falcon demonstrates that well-funded research institutions outside of Big Tech companies can create large-scale, high-performing open models. This democratization of AI development suggests a future where state-of-the-art capabilities aren’t limited to a handful of tech giants.

LLaMA Family and Derivatives
Meta’s LLaMA models have become the foundation for numerous derivative models, creating their own thriving ecosystem:

Vicuna-13B
Built on LLaMA, Vicuna-13B was fine-tuned on user-shared dialogues filtered from ShareGPT. It emerged as one of the first widely recognized “chat finetunes” of the LLaMA family, demonstrating near-GPT-4 level conversational abilities despite having only 13 billion parameters. This highlighted how targeted fine-tuning on high-quality conversation data could dramatically improve a model’s practical utility.
The fine-tuning process can be represented mathematically as:

Where: –  represents the original LLaMA parameters –
represents the original LLaMA parameters –  is the learning rate –
is the learning rate –  is the loss function –
is the loss function –  is the ShareGPT dataset
is the ShareGPT dataset
White Rabbit Neo
Referenced as a “Llama2 hacking contribution,” White Rabbit Neo exemplifies the rapid emergence of Llama 2 derivatives and specialized modifications expanding the base model’s capabilities. This points to a growing trend of community-driven innovation in the open-source LLM space.
Specialized and Domain-Specific Models
BloombergGPT
Domain Focus: Financial tasks and analysis
BloombergGPT demonstrates the value of domain specialization in language models. By focusing specifically on financial tasks such as analyzing stock movements and interpreting financial language, it outperforms general-purpose models within its domain while predictably lagging behind on broader knowledge tasks.
This model highlights an important trend: as the LLM landscape matures, we’re likely to see more purpose-built models optimized for specific industries or use cases rather than one-size-fits-all solutions.
Meta Math QA
Meta Math QA features an expanded mathematics dataset designed specifically for improving LLMs’ quantitative reasoning capabilities. This specialized dataset addresses one of the persistent challenges in language model development: performing reliable mathematical operations and complex problem-solving.
The development of dedicated mathematical datasets points to a growing recognition that certain domains require specialized training approaches beyond general language modeling. Models fine-tuned on such datasets show significant improvements in solving mathematical problems, handling quantitative reasoning tasks, and providing more accurate numerical responses.
The mathematical reasoning process in LLMs can be formalized as:

Where: –  is the input problem –
is the input problem –  is the step-by-step solution –
is the step-by-step solution –  represents previous tokens in the solution
represents previous tokens in the solution
Efficiency and Distillation Approaches
Orca by Microsoft
Orca represents an innovative imitation-learning approach in which a smaller “student” model is trained using step-by-step “explanations” or “reasoning traces” generated by larger “teacher” foundation models.
This “chain-of-thought distillation” technique enables the smaller model to learn not just answers but also the reasoning methodology behind them. This approach addresses a critical challenge in AI development: how to create more efficient models that maintain the reasoning capabilities of their larger counterparts without the enormous computational requirements.

The knowledge distillation objective can be expressed as:

Where: –  is the cross-entropy loss –
is the cross-entropy loss –  is the student model output –
is the student model output –  is the teacher model output –
is the teacher model output –  is the ground truth – is a weighting parameter
is the ground truth – is a weighting parameter
Multimodal Models
FireLLaMA → VLM
FireLLaMA extends Llama-based models to Visual Language Modeling (VLM), enabling these models to process and understand images alongside text inputs. This multimodal capability represents an important evolution in language models, moving beyond pure text to incorporate visual information.
The development of VLM capabilities in the LLaMA family demonstrates how foundation models are increasingly crossing modality boundaries, creating systems that more closely resemble human-like understanding of the world through multiple sensory inputs.
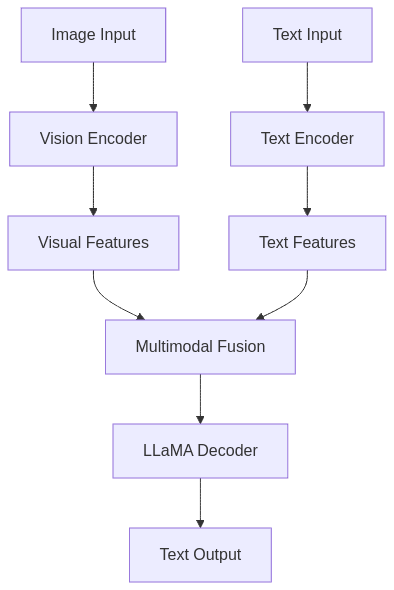
SeamlessM4T
Developer: Meta
Focus: Speech translation and cross-lingual tasks
SeamlessM4T represents a significant step forward in multimodal and multilingual AI. As a “foundational multimodal model” supporting a wide variety of languages, it provides a single end-to-end system for speech recognition, translation, text generation, and more.
The integration of speech, text, and translation capabilities into a unified model points to a future where AI systems seamlessly bridge linguistic divides across multiple modalities, making cross-language communication more natural and accessible.

Tool Integration and Agent Frameworks
TORA (Tool Integrated Roaming Agent)
TORA represents another approach in the growing field of agent-based AI systems. Similar in concept to the ReAct framework, TORA integrates external tools within an agent loop, allowing the model to “roam” through different tool APIs, calling them as needed to accomplish tasks.
This capability to leverage external tools significantly expands what language models can accomplish by connecting them to databases, search engines, code execution environments, and other resources beyond their internal knowledge. The development of such frameworks points to a future where LLMs serve as the reasoning core of more complex systems rather than standalone applications.
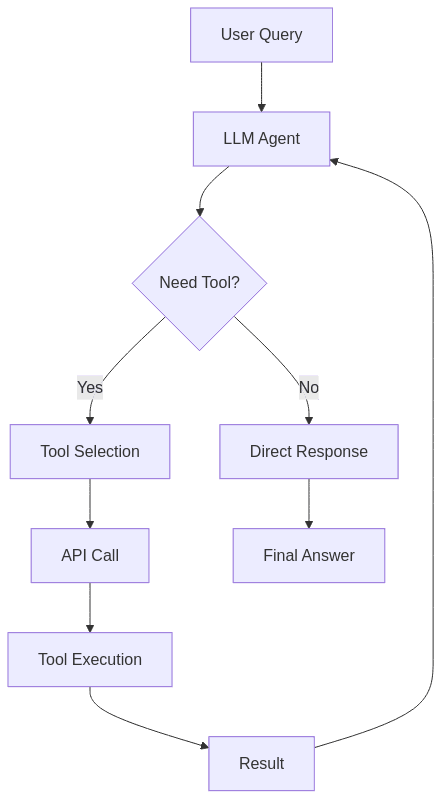
Open Data Initiatives
Red Pajama & Associated Datasets
The Red Pajama project represents a collaborative effort to create high-quality, transparent pretraining data for language models. This initiative encompasses several important datasets:
| Dataset | Description | Size | Primary Use |
|---|---|---|---|
| C4 | Filtered web crawl dataset originally used by T5 | 750GB | General pretraining |
| Dolma | Curated web-scale dataset | 3TB | High-quality pretraining |
| Refined Web | Web data with improved filtering | 5TB | Diverse knowledge capture |
| Common Crawl | Massive repository of web crawls | >100TB | Large-scale pretraining |
The goal of Red Pajama is to provide a fully open-source data pipeline, enabling researchers to train and reproduce large language models with transparent data sources. This addresses one of the persistent challenges in AI development: access to high-quality training data without proprietary restrictions.

Emerging Trends and Future Directions
The survey of these models reveals several important trends in LLM development:
-
Democratization: With models like Falcon 40B and the LLaMA family, state-of-the-art capabilities are increasingly available outside of Big Tech companies.
-
Specialization: Domain-specific models like BloombergGPT demonstrate how targeted training can produce superior results for specific applications.
-
Efficiency innovation: Approaches like Orca’s distillation techniques are making advanced capabilities available in smaller, more efficient models.
-
Multimodal integration: Models like SeamlessM4T and FireLLaMA are breaking down barriers between text, speech, and visual understanding.
-
Tool integration: Frameworks like TORA are extending LLMs’ capabilities by connecting them to external resources and tools.
-
Data transparency: Initiatives like Red Pajama are promoting open, reproducible approaches to model training.
As the field continues to evolve, we can expect further innovation in these areas, along with increased focus on responsible AI development, including safety, bias mitigation, and alignment with human values.
Conclusion
The rapid proliferation of large language models represents one of the most dynamic areas in artificial intelligence research. From open-source alternatives challenging commercial offerings to specialized models pushing the boundaries in specific domains, the LLM landscape continues to evolve at a remarkable pace.
For organizations and researchers looking to leverage these technologies, understanding the strengths, limitations, and unique characteristics of different models becomes increasingly important. As we move forward, the ability to select the right model—or combination of models—for specific use cases will be a key differentiator in successful AI implementation.