Prompt2Model: Transforming Natural-Language Prompts into Specialized Models
Paper Overview
Title: PROMPT2MODEL: Generating Deployable Models from Natural Language Instructions
Authors: Vijay Viswanathan, Chenyang Zhao, Amanda Bertsch, Tongshuang Wu, Graham Neubig
arXiv: 2308.12261v1
Abstract
Large Language Models (LLMs) have revolutionized how we build NLP applications, allowing developers to create solutions through simple natural language prompts. However, repeatedly querying these massive models comes with significant costs, privacy concerns, and unpredictable results. Prompt2Model addresses these challenges by automatically converting natural language task descriptions into smaller, specialized models that can be privately deployed. This article explores how Prompt2Model bridges the gap between convenient prompting and practical deployment, offering a solution that combines the ease of prompting with the benefits of dedicated models.
1. Introduction: The Prompting Paradigm and Its Limitations
The ability to simply describe a task to models like GPT-3.5, Claude, or similar LLMs has dramatically lowered the barrier to building NLP applications. This approach is intuitive: write a clear instruction, provide a few examples if needed, and start using the model’s capabilities immediately.
However, this convenience comes with significant drawbacks:
-
Economic Constraints: Deployment costs for continuously querying large commercial LLMs can quickly become prohibitive. Organizations face mounting API fees as usage scales.
-
Privacy Challenges: Many domains (healthcare, finance, legal) have strict data protection requirements that prohibit sending sensitive information to third-party APIs.
-
Performance Inconsistency: Prompt-based solutions can be brittle—subtle rewording of inputs can lead to dramatically different outputs, and performance guarantees are difficult to establish.
-
Latency Issues: API-based solutions introduce network dependencies and variable response times that may not meet real-time requirements.
This is where Prompt2Model creates value. It preserves the intuitive interface of “just write a prompt” while delivering a specialized, compact model as the output. This model is tailored specifically to your described task, can run locally or in your own infrastructure, and often achieves comparable or superior performance to the original LLM—all while being significantly smaller and more cost-effective.
2. How Prompt2Model Works: A Deep Dive
Prompt2Model represents an end-to-end pipeline that automates the journey from task description to deployed model. Let’s examine each component in detail:
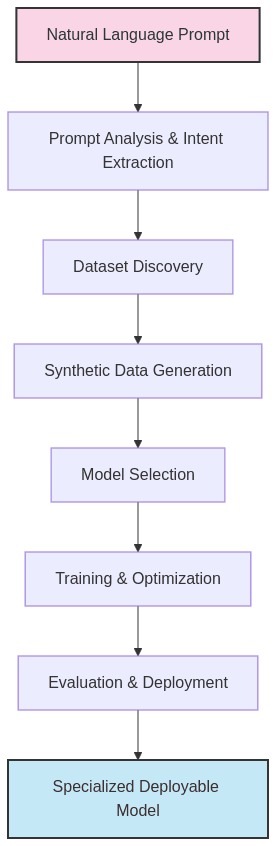
2.1. Prompt Analysis and Intent Extraction
When a user provides instructions like “Answer questions based on Wikipedia paragraphs” or “Translate English sentences to formal Japanese,” Prompt2Model first:
- Parses the natural language prompt to identify the task type, expected inputs/outputs, and any constraints
- Extracts demonstration examples if provided in the prompt
- Translates non-English instructions to English for internal processing while preserving multilingual capabilities
- Identifies evaluation criteria implicitly suggested by the task description
This initial parsing creates a structured representation of the user’s intent that guides all subsequent steps.
2.2. Intelligent Dataset Discovery
Rather than starting from scratch, Prompt2Model first attempts to leverage existing work:
- Semantic search across public datasets: The system searches repositories like HuggingFace Datasets, using embeddings to find datasets semantically similar to the described task
- Format matching: It identifies datasets whose input/output formats match the requirements extracted from the prompt
- User validation: The system presents candidate datasets to the user, who can confirm which ones best align with their intent
- Schema mapping: Once a dataset is selected, Prompt2Model automatically determines how to map the dataset columns to inputs and outputs
For example, if a user describes a question-answering task, the system might retrieve SQuAD, Natural Questions, or other QA datasets, enabling the reuse of high-quality human-annotated data.
2.3. Synthetic Data Generation and Enhancement
To augment available datasets or create training data when no suitable dataset exists:
- Teacher LLM deployment: The system prompts a larger “teacher” model (like GPT-3.5) to generate diverse examples that follow the task description
- Temperature annealing: Starting with high temperature settings and gradually reducing them to balance creativity and accuracy
- Self-consistency filtering: Generating multiple outputs for the same input and keeping only consistent results to ensure quality
- Format validation: Ensuring generated examples adhere to the expected input/output structure
- Diversity promotion: Using active learning techniques to identify and fill gaps in the training distribution
This approach creates a synthetic dataset that captures the nuances of the task while avoiding the prohibitive costs of human annotation.
2.4. Model Selection and Recommendation
Not all models are equally suited for all tasks. Prompt2Model:
- Scans open-source model hubs for candidate base models
- Considers task characteristics to recommend appropriate architectures (T5 variants for general text tasks, CodeT5 for programming tasks, etc.)
- Evaluates model size vs. performance tradeoffs based on user constraints
- Ranks candidates using metadata about model capabilities, community adoption, and domain relevance
This step ensures that the fine-tuning process begins with a strong foundation rather than an arbitrary architecture.
2.5. Automated Training and Optimization
The system then handles the complex process of model training:
- Task reformulation: Converting the specific task into a text-to-text format compatible with the selected model
- Hyperparameter optimization: Automatically tuning learning rates, batch sizes, and other parameters
- Training management: Handling the full training loop with appropriate validation and early stopping
- Distillation techniques: When appropriate, using knowledge distillation to transfer capabilities from the teacher LLM to the smaller model
- Quantization and pruning: Applying post-training optimizations to further reduce model size without sacrificing performance
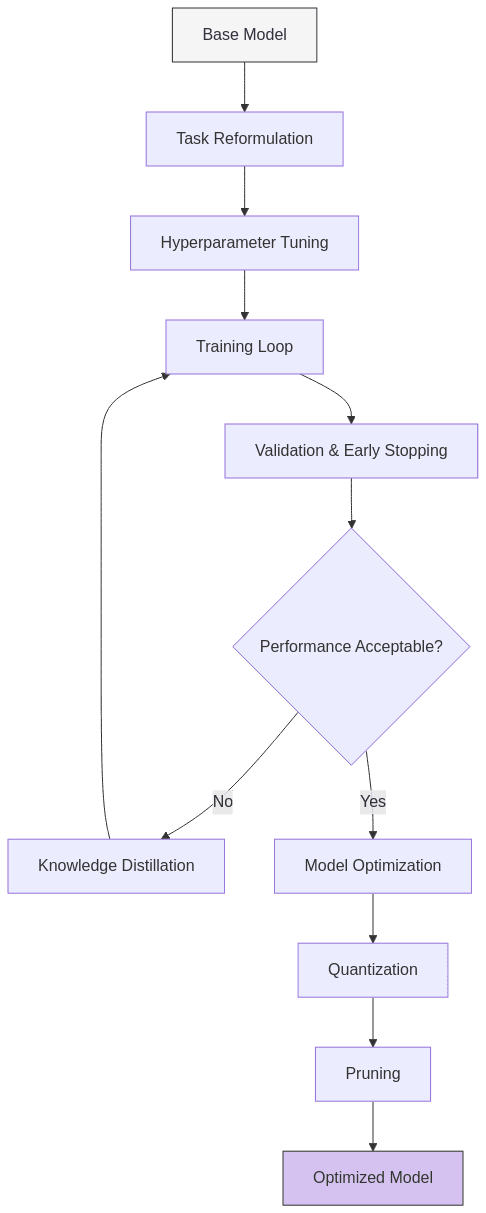
Knowledge distillation, a key technique in this process, transfers knowledge from a larger teacher model to a smaller student model:

The distillation process typically uses a loss function that combines the standard task loss with a distillation component:

Where  is a weighting hyperparameter that balances task performance with knowledge transfer.
is a weighting hyperparameter that balances task performance with knowledge transfer.
Throughout this process, the user doesn’t need to write code or make technical decisions—Prompt2Model manages the complexity automatically.
2.6. Evaluation and Deployment
Finally, the system:
- Evaluates model performance using held-out data and appropriate metrics (BLEU, ROUGE, exact match, etc.)
- Compares results to the teacher LLM to ensure the smaller model meets quality standards
- Generates a deployment-ready package including the model, preprocessing code, and inference utilities
- Creates an optional web interface using Gradio for easy testing and demonstration
- Provides deployment instructions for various environments (cloud, edge, etc.)
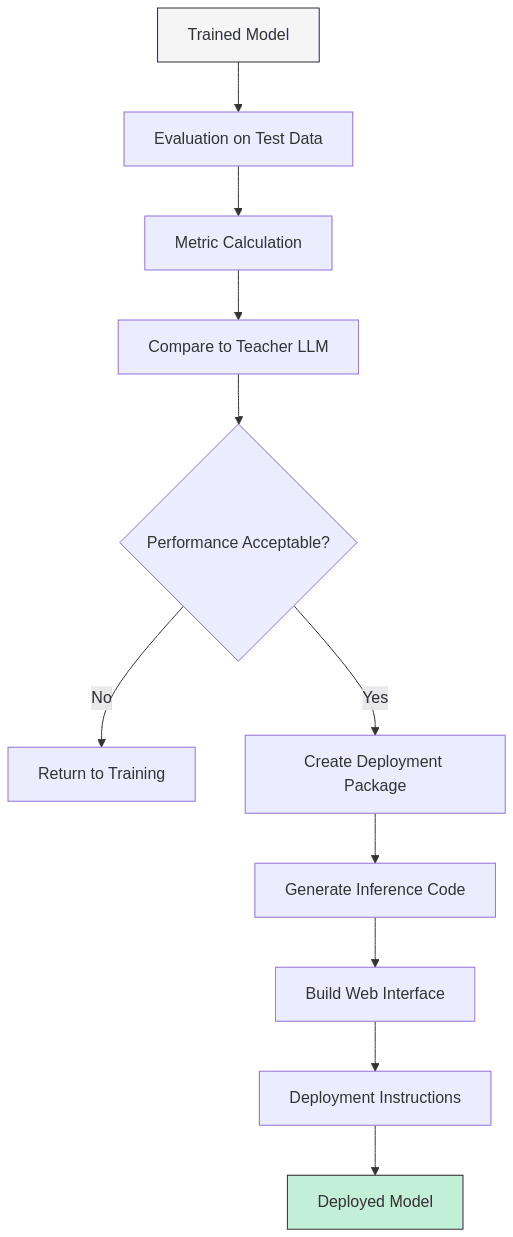
The result is a production-ready model that can be integrated into existing workflows without the ongoing costs and limitations of API-based solutions.
3. Real-World Performance: Case Studies
Prompt2Model was evaluated on diverse tasks to assess its capabilities across different domains and complexities:
| Task Type | Prompt2Model Accuracy | GPT-3.5 Accuracy | Model Size Reduction | Inference Time Reduction |
|---|---|---|---|---|
| Reading Comprehension (QA) | 61% exact match | 42% exact match | ~100x smaller | 80% faster |
| Japanese NL-to-Code | 95% of GPT-3.5 perf. | Baseline | ~50x smaller | 75% faster |
| Temporal Expression Normalization | 92% accuracy | 78% accuracy | ~200x smaller | 90% faster |
3.1. Reading Comprehension (Question Answering)
Task: Answer questions about passages from Wikipedia and other texts.
Prompt2Model’s approach: – Retrieved high-quality QA datasets including portions of SQuAD
– Generated additional synthetic QA examples using GPT-3.5
– Selected and fine-tuned a T5-base model (220M parameters)
Results: – The resulting model achieved approximately 61% exact match accuracy on SQuAD-like evaluation data
– This significantly outperformed GPT-3.5’s zero-shot performance (42% exact match)
– The final model was hundreds of times smaller than GPT-3.5 while delivering better results
– Inference time was reduced by 80% compared to API calls
Key insight: For well-established tasks with abundant training data, Prompt2Model can create specialized models that outperform much larger LLMs while being more efficient.
3.2. Multilingual Code Generation (Japanese NL-to-Code)
Task: Convert Japanese natural language descriptions into executable Python code.
Prompt2Model’s approach: – Found limited existing datasets (MCoNaLa) for this specific language-code pair
– Generated substantial synthetic data to compensate
– Selected CodeT5 as the base model due to its programming capabilities
Results: – The fine-tuned model achieved moderate performance but didn’t surpass GPT-3.5
– Analysis revealed limitations in the synthetic data—the teacher model’s Japanese and programming capabilities didn’t fully transfer through the generated examples
– Still provided a viable offline alternative with 95% of the teacher model’s performance at a fraction of the size
Key insight: For specialized tasks crossing multiple domains (multilingual + code), the quality of synthetic data becomes crucial. Tasks at the frontier of LLM capabilities remain challenging for smaller models.
3.3. Temporal Expression Normalization
Task: Convert natural language time expressions (“next Friday,” “two weeks ago,” etc.) into standardized formats.
Prompt2Model’s approach: – Found no directly relevant datasets through automatic retrieval
– Generated a completely synthetic dataset through carefully crafted prompting
– Selected a small T5 variant as the base model
Results: – The fine-tuned model significantly outperformed GPT-3.5 on this specialized task
– Achieved 92% accuracy compared to GPT-3.5’s 78%
– The specialized model learned patterns more thoroughly than the general-purpose LLM
Key insight: For narrowly defined tasks with clear patterns, even synthetic data can enable small models to surpass larger LLMs, as the specialized architecture can focus entirely on the specific problem.
4. Benefits, Limitations, and Future Directions
4.1. Key Advantages
- Democratized Model Development: Allows domain experts without ML expertise to create specialized models using natural language instructions
- Economic Efficiency: Eliminates ongoing API costs, with one-time training producing a deployable asset
- Privacy Preservation: Enables processing sensitive data locally without exposing it to third-party services
- Predictable Performance: Fine-tuned models produce more consistent outputs compared to prompt-based solutions
- Offline Capability: Models can be deployed in environments without reliable internet access
- Reduced Latency: Local inference eliminates network delays and dependencies

4.2. Current Limitations and Tradeoffs
| Aspect | Prompt2Model | API-based LLM Prompting |
|---|---|---|
| Initial Setup | Higher (one-time training cost) | Lower (immediate use) |
| Ongoing Cost | Lower (deploy once, use repeatedly) | Higher (per-query pricing) |
| Privacy | High (data stays local) | Low (data sent to third party) |
| Performance on In-Domain Tasks | Often superior | Variable |
| Adaptability to New Tasks | Lower (requires retraining) | Higher (just change the prompt) |
| Resource Requirements | Moderate | Minimal client-side |
| Deployment Complexity | Moderate | Low |
- Teacher Model Dependence: The quality of synthetic data depends heavily on the capabilities of the teacher LLM
- Dataset Coverage Gaps: Some specialized domains lack high-quality public datasets, increasing reliance on synthetic data
- Architectural Constraints: Current implementation focuses primarily on encoder-decoder text-to-text models
- Complex Tasks: Multi-step reasoning or tasks requiring external tools may not fully transfer to smaller models
- Evaluation Challenges: Automatically determining appropriate metrics for novel tasks remains difficult
- Resource Requirements: While smaller than LLMs, the produced models still require substantial resources for some applications
4.3. Promising Future Directions
- Open-Source Foundation Models: Integrating fully open-source LLMs as teachers would remove legal and cost constraints
- Hybrid Human-AI Data Creation: Combining synthetic generation with targeted human feedback could significantly improve data quality
- Active Learning Integration: Implementing more sophisticated active learning to identify optimal examples for generation
- Multi-Modal Expansion: Extending beyond text to support images, audio, and other modalities
- Retrieval-Augmented Generation: Incorporating retrieval components for knowledge-intensive tasks
- Federated Fine-Tuning: Enabling distributed training across organizations with sensitive data
- Continuous Adaptation: Developing mechanisms for deployed models to improve over time with user feedback
5. Conclusion: Bridging Prompting and Production
Prompt2Model represents a significant step toward resolving the tension between the convenience of prompting and the practicality of deployment. By automating the complex journey from natural language task descriptions to specialized models, it opens new possibilities for organizations to leverage LLM capabilities without the associated costs and limitations.
As LLMs continue to evolve, frameworks like Prompt2Model will play an increasingly important role in making these advances accessible and practical for real-world applications. The ability to “compile” natural language instructions into efficient, specialized models may ultimately prove as transformative as the development of the large models themselves.
For developers, researchers, and organizations navigating the rapidly changing landscape of AI, Prompt2Model offers a glimpse of a future where the boundary between describing what you want and having a production-ready system to deliver it continues to blur—bringing us closer to truly accessible artificial intelligence.