Beyond GPT: Exploring The Frontier of Large Language Models
Introduction
While OpenAI’s GPT models have dominated headlines and captured public imagination, they represent just one approach in the rapidly evolving landscape of large language models (LLMs). Several other groundbreaking architectures have emerged from leading AI research labs, each with unique capabilities and design philosophies. This article explores three significant alternatives to GPT—PaLM, Turing NLG, and UL2—and examines how innovations like Program-Aided Language Models are pushing the boundaries of what’s possible in natural language processing.
The Diverse Ecosystem of Large Language Models
Modern LLMs can be categorized by their architecture (encoder-only, decoder-only, or encoder-decoder), training objectives, and specialized capabilities. While GPT models follow a decoder-only architecture optimized for text generation, other approaches offer complementary strengths for different use cases.
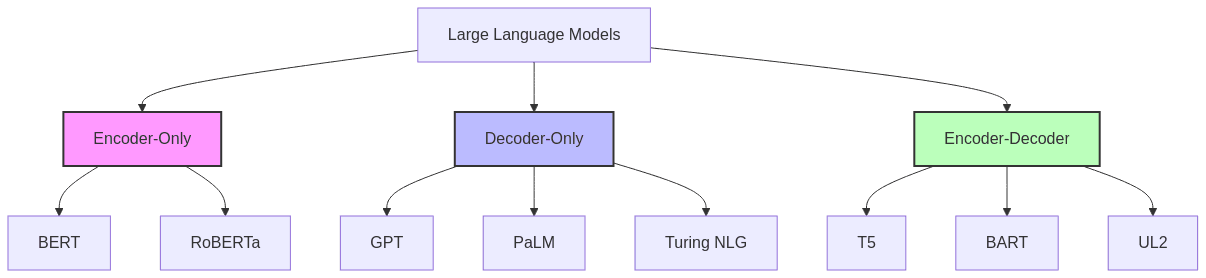
PaLM: Google’s Pathways Language Model
Architecture and Scale
- Developed by Google using their Pathways distributed training system
- A decoder-only architecture optimized for text generation
- Scales to massive parameter counts (540B parameters in its largest version)
- Uses a dense, full-parameter architecture rather than a sparse mixture-of-experts approach (unlike models such as Switch Transformer or GLaM)
Key Innovations
- Trained on a diverse, multilingual corpus spanning hundreds of languages
- Designed with capabilities that can later be extended to multimodal inputs through adapters
- Implements a novel approach to training that improves computational efficiency
- Uses a technique called “chain-of-thought prompting” that dramatically improves reasoning capabilities
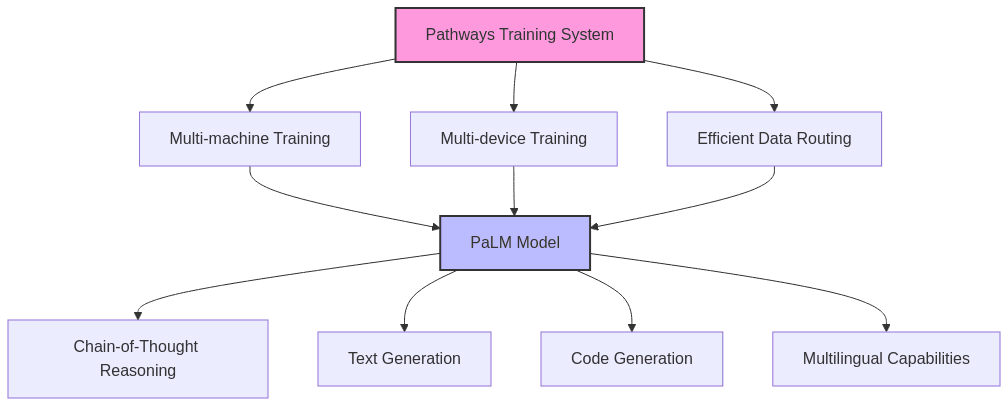
Real-World Applications
- Powers complex reasoning tasks in Google’s AI systems
- Enables more nuanced translation between languages
- Supports creative text generation with higher coherence over long outputs
- Forms the foundation for domain-specific adaptations in scientific research and coding assistance
Turing NLG: Microsoft’s Language Generation Powerhouse
Architecture and Approach
- Developed by Microsoft Research
- Uses a decoder-only architecture similar to GPT
- Scaled to 17B parameters in its initial release (2020)
- Optimized specifically for natural language generation tasks
Distinctive Features
- Incorporates techniques for improving factual accuracy
- Trained on Microsoft’s diverse corpus of academic papers, websites, and books
- Implements improved context handling for longer document generation
- Specialized in maintaining coherence across extended text generations
Practical Impact
- Forms part of Microsoft’s AI infrastructure for enterprise solutions
- Powers enhanced features in Microsoft’s productivity software
- Enables more natural interactions in customer service applications
- Provides capabilities for content generation and summarization at scale
UL2: Google’s Unified Language Learning Paradigm
Revolutionary Training Approach
- Developed by Google Research as a unified framework for language model training
- Combines supervised, self-supervised, and unsupervised learning objectives
- Employs a “mixture of denoisers” training approach that handles multiple objectives simultaneously
- Designed specifically to excel at both short and long-context tasks
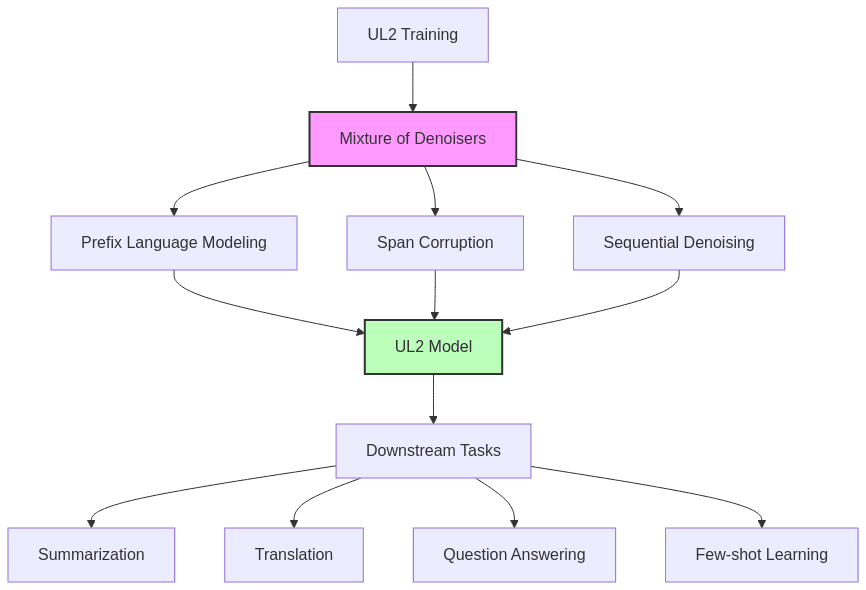
Technical Innovations
- Introduces “pseudo-masked language modeling” that varies the span lengths of masked tokens
- Implements specialized objectives for different sequence lengths
- Achieves strong performance with fewer parameters through more efficient training
- Creates a single model capable of handling diverse tasks without task-specific fine-tuning
The masked language modeling objective in UL2 can be represented mathematically as:
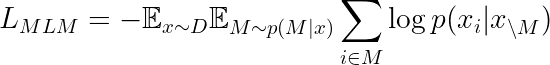
Where: –  is a sequence from the dataset
is a sequence from the dataset 
– 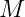 is a mask pattern
is a mask pattern
– 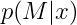 is the distribution of mask patterns
is the distribution of mask patterns
– 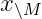 represents the sequence with masked tokens
represents the sequence with masked tokens
Performance and Capabilities
- Demonstrates superior few-shot learning capabilities
- Excels at long-sequence tasks (documents spanning thousands of tokens)
- Shows improved performance in knowledge-intensive applications
- Maintains strong performance across multiple languages and domains
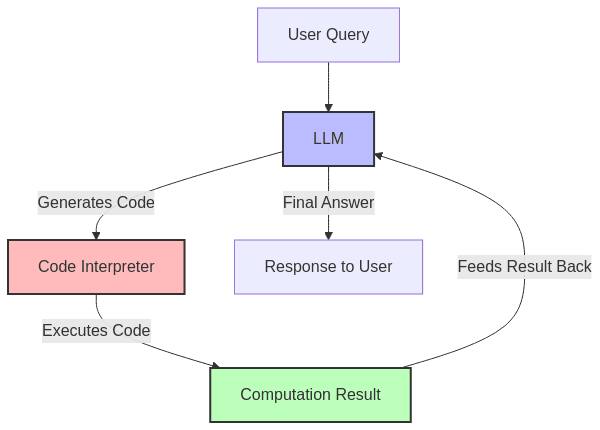
Program-Aided Language Models: Augmenting Language with Computation
Concept and Implementation
- Augments language models by offloading complex computations to external programs
- Enables precise calculation and logical operations through code generation
- Combines natural language understanding with programmatic execution
- Creates a feedback loop between language generation and computational results
Key Benefits
- Improves accuracy on mathematical reasoning by 10–40% across various problem types
- Enhances logical reasoning through systematic computational steps
- Provides verifiable results for complex queries
- Bridges the gap between natural language understanding and algorithmic execution
The improvement in reasoning accuracy can be formalized as:
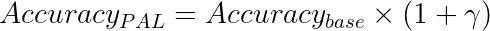
Where: – 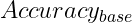 is the base accuracy of the language model –
is the base accuracy of the language model – 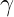 represents the improvement factor (typically 0.1 to 0.4) –
represents the improvement factor (typically 0.1 to 0.4) – 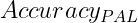 is the resulting accuracy with Program-Aided Learning
is the resulting accuracy with Program-Aided Learning
Notable Examples
- OpenAI’s Codex (and models like code-davinci-002) demonstrate this approach
- Systems like Microsoft’s Copilot leverage similar techniques
- Research frameworks exploring automated reasoning through code execution
- Emerging applications in scientific computing and data analysis
Comparing Approaches: Strengths and Specializations
| Model | Architecture | Parameter Count | Specialized Capabilities | Key Differentiator |
|---|---|---|---|---|
| GPT-4 | Decoder-only | Undisclosed (est. > 1T) | Text generation, instruction following | Alignment with human preferences |
| PaLM | Decoder-only | 540B | Multilingual processing, reasoning | Pathways training system |
| Turing NLG | Decoder-only | 17B | Long-form text generation | Enterprise integration |
| UL2 | Encoder-decoder | 20B | Unified learning across objectives | Mixture of denoisers approach |
Future Directions and Research Frontiers
As these diverse approaches to language modeling continue to evolve, several promising research directions are emerging:
- Further integration of multimodal capabilities across different architectures
- More efficient training methods that reduce computational requirements
- Enhanced reasoning capabilities through improved architectures and training objectives
- Better methods for incorporating external knowledge and factual verification
- Specialized models optimized for specific domains like healthcare, science, and law
Conclusion
The landscape beyond GPT reveals a rich ecosystem of innovative approaches to language modeling. PaLM, Turing NLG, UL2, and Program-Aided Language Models each represent distinctive paradigms with unique strengths. As research continues to advance, we can expect further diversification of architectures and training methods, leading to increasingly capable AI systems that blend the boundaries between language understanding, reasoning, and computation.
Rather than a single dominant approach, the future of AI likely lies in leveraging these complementary strengths to build systems that combine the best elements of each paradigm—producing more capable, efficient, and versatile language models that can better serve human needs across a wide range of applications.