Executive Summary
Large Language Models (LLMs) have metastasized across the digital landscape, bringing uncanny abilities alongside crushing computational demands. The sheer scale is breathtaking, and often, prohibitive. Enter Wanda, a pruning technique remarkable not for its Byzantine complexity, but for its almost unsettling simplicity. It proposes carving out 50% of an LLM’s parameters—with negligible performance loss—and crucially, without any costly retraining. Forget the old prayers of magnitude pruning; Wanda takes a harder look, considering not just weight size but the pulse of activations, identifying the connections that actually matter in these silicon behemoths.

1. The Crushing Weight of LLM Scale
We’re witnessing a silicon arms race. Models swell from mere hundreds of millions to baroque constructions boasting hundreds of billions, even trillions, of parameters:
- GPT-4: Whispered to be ~1.7 trillion parameters
- LLaMA-2-70B: A hefty 70 billion parameters
- PaLM: Tipping the scales at 540 billion parameters
This relentless expansion unlocks startling emergent properties, sure. But it also imposes a brutal reality:
- Compute Hunger: Training and inference require server farms that drink electricity.
- Memory Gluttony: Just loading these beasts demands stacks of high-end GPUs.
- Environmental Toll: The carbon footprint isn’t trivial when deployed globally.
- The Access Divide: Let’s be blunt: most organizations are priced out of this game.
For decades, we’ve known about neural network pruning—snipping away less critical weights to slim models down. But applying the old playbook to LLMs? That’s where the conventional wisdom hits a wall.

2. Why the Old Pruning Tricks Fail on LLMs
Applying established pruning methods to models with billions of parameters reveals their limitations, often catastrophically. Three failure modes dominate:
2.1 The Retraining Cost Nightmare
Many classic pruning strategies follow a painful cycle:
- Train the damn thing (expensive).
- Snip weights deemed ‘unimportant’.
- Retrain the wounded model to claw back lost accuracy (also expensive).
Rinse and repeat. For LLMs where a single training run can incinerate hundreds of thousands of dollars, this iterative loop is economically insane.
2.2 The Crushing Weight of Sophistication
Fancier methods, like Optimal Brain Surgeon (OBS), leverage second-order information (Hessians) or intricate weight reconstruction schemes. They sound impressive. They can work well on smaller networks. But on LLMs:
- Computing and storing Hessian matrices? Forget it. We’re talking petabytes.
- Memory needs often scale quadratically with model size. Good luck.
- These algorithms simply choke and die at the scale of billions of parameters. Computationally infeasible.
2.3 Naive Magnitude Pruning: Simple, Elegant, Wrong
The most intuitive approach: kill the smallest weights (those closest to zero). It’s simple, fast, and works surprisingly well for many traditional networks. On LLMs, however, it utterly breaks down:
At 50% sparsity using simple magnitude pruning:
- Small CNN (CIFAR-10): Maybe a ~1% accuracy dip. Tolerable.
- LLaMA-7B: Perplexity skyrockets from ~7 to ~17-20. The model becomes incoherent garbage.
This stark failure isn’t a minor calibration issue. It signals that for LLMs, the absolute size of a weight is a poor, often misleading, proxy for its actual importance. Something fundamental is missing.
3. Wanda: The Elegant Hack
Wanda’s power stems from a simple, yet crucial, observation about how LLMs actually work: activations across their hidden dimensions are wildly uneven.
3.1 The Outlier Enigma
Deep within these transformer behemoths, some hidden features (“dimensions”) light up like fireworks, their activation magnitudes dwarfing others by 100x or more. This “outlier feature” phenomenon changes the game:
- A tiny weight connected to a dimension that always fires might be indispensable.
- A massive weight linked to a dimension that rarely activates could be dead wood.
Naive magnitude pruning is blind to this. It hacks away without understanding the context, hence its catastrophic failure.

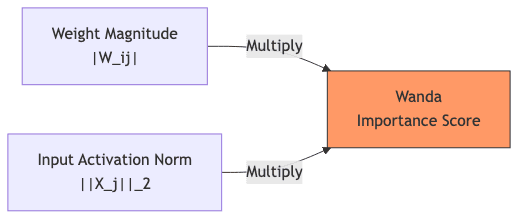
3.2 The Wanda Score: Weight × Activation
Wanda introduces an almost insultingly simple metric that captures this interplay:
Where:
is a specific weight.
is the vector of activations observed across the
-th input dimension during a brief calibration run.
is simply the L2 norm (magnitude) of those activations – a measure of how “loud” that input dimension tends to be.
It elegantly fuses two signals:
- The weight’s own magnitude (
).
- The typical activity level of its input source (
3.3 The Wanda Algorithm: Almost Too Easy
Implementing Wanda is refreshingly straightforward:
- Feed it snacks: Grab a small, diverse set of text samples (e.g., 128 sequences).
- One forward pass: Run these samples through the model once to calculate the activation norm
- Calculate scores: Compute the Wanda Importance score for every single weight
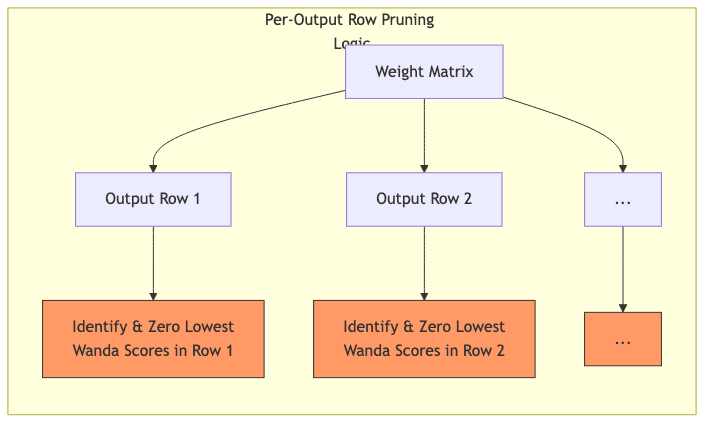
- Prune per-output: This is key. Instead of globally axing the lowest N% scores, prune within each output neuron’s incoming connections. Remove the lowest-scoring weights for that specific output, preserving a target sparsity row by row.
This per-output pruning strategy seems to maintain functional balance across the network much better than global or layer-wise approaches.

3.4 The Sound of Silence: No Retraining
Let’s reiterate the most disruptive part: Wanda skips the retraining nightmare entirely. Pruned weights are zeroed out. Everything else stays put. No fine-tuning, no complex adjustments. It’s brutal, efficient, and surprisingly effective.
4. Does This Simple Hack Actually Work? The Evidence
The paper puts Wanda through its paces on LLaMA models (7B to 70B parameters), evaluating standard benchmarks. The results are compelling.
4.1 Zero-Shot Performance: Holding the Line
At 50% sparsity (half the model gone):
| Model | Magnitude Pruning | Wanda | Original Dense |
|---|---|---|---|
| LLaMA-7B | Utterly broken | ~92% of original perf. | 100% |
| LLaMA-13B | Utterly broken | ~95% of original perf. | 100% |
Wanda holds performance remarkably well, while naive magnitude pruning causes catastrophic collapse.
4.2 Language Modeling Perplexity: Keeping Coherence
Perplexity tests raw prediction ability (lower is better). How does Wanda stack up against the original and a more complex method like SparseGPT?
| Model | Original | Magnitude Pruning (50%) | Wanda (50%) | SparseGPT (50%) |
|---|---|---|---|---|
| LLaMA-7B | ~7 | ~17-20 (Garbage) | ~7-8 | ~7-8 |
| LLaMA-13B | ~6 | ~15-18 (Garbage) | ~6-7 | ~6-7 |
Wanda essentially matches the performance of SparseGPT, a far more computationally intensive technique, while requiring orders of magnitude less work.
4.3 Structured Sparsity: Playing Nice with Hardware
Wanda isn’t just for unstructured, random-looking sparsity. It can be adapted to create patterns that hardware accelerators like NVIDIA GPUs actually understand, like N:M sparsity (keeping N weights for every M consecutive ones).
- 2:4 sparsity pattern: Wanda maintains ~98% of its unstructured performance.
- 4:8 sparsity pattern: Similar resilience, enabling use of hardware sparse tensor cores.
This shows Wanda is indeed practically adaptable.

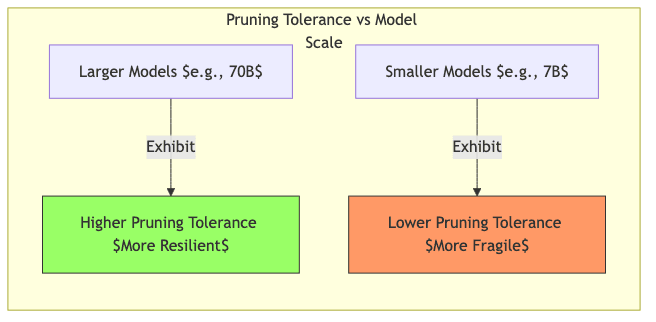
4.4 The Bloat Paradox: Bigger Models Prune Better
Counter-intuitively, the researchers found that larger models are more resilient to Wanda pruning:
- LLaMA-7B starts to degrade significantly past 60% sparsity.
- LLaMA-70B holds up well even at 60-70% sparsity.
This suggests that as LLMs scale, they accumulate even more redundancy. They aren’t just bigger; they might be proportionally more bloated, making techniques like Wanda even more impactful.
5. Practical Reality: What Wanda Enables
5.1 Speed Demon: Why Simplicity Wins
Wanda’s lack of complexity translates directly into speed:
- Reportedly 100-300 times faster than methods needing complex weight updates.
- Pruning a multi-billion parameter model takes minutes, not the hours or days required by heavier algorithms.
- Memory overhead is negligible – just stash those activation norms.
5.2 Implementation: No PhD Required
Actually implementing Wanda is almost anticlimactic:
- Run one forward pass with a small calibration batch.
- Calculate L2 norms for input activations.
- Compute importance scores:
abs(weight) * activation_norm. - For each output row in a weight matrix, find the weights with the lowest scores and zero them out until you hit your target sparsity. Done.
5.3 Where Wanda Makes a Difference
This kind of efficiency unlocks real-world possibilities:
- Edge Deployment: Squeezing models onto devices with limited memory/power.
- Faster Inference: If sparse matrix operations are optimized, pruned models can run faster.
- Cheaper Cloud Bills: Less RAM usage translates directly to lower hosting costs.
- Compression Stacking: Use Wanda as a first step before quantization for even greater size reduction.
6. The Catch? Limitations and What’s Next
Wanda is impressive, but not magic. Let’s be clear about its limits:
6.1 Current Boundaries
- High Sparsity Wall: Push past 70-80% sparsity, and performance still tanks. There’s a limit.
- Calibration Needed: It needs some representative data, even if just a little.
- Sparse Kernels: Getting actual speedups requires efficient sparse matrix libraries, which aren’t always available or optimized.
6.2 Obvious Next Steps
The path forward seems clear:
- A Touch of Fine-Tuning: Maybe a very brief fine-tuning phase post-Wanda could patch up remaining holes?
- Prune then Quantize: Systematically combining Wanda with quantization seems essential.
- Hardware Co-Design: Tailoring Wanda’s patterns more explicitly for specific silicon.
- Smarter Calibration: Can we automatically find the best few samples for calibration?
- Beyond Weights: Can similar activation-aware logic be applied to prune entire neurons or attention heads?
7. Conclusion: Elegance in the Face of Complexity
In a field often drowning in its own complexity, Wanda is a breath of fresh air. It’s a potent reminder that sometimes, a clever insight packaged into a simple heuristic can outperform elaborate, computationally monstrous approaches. By acknowledging the peculiar activation dynamics of LLMs, Wanda finds a straightforward path to significant model compression without the usual pain of retraining.
For anyone wrestling with the practical deployment of LLMs, Wanda offers a tangible way to make these powerful tools lighter, faster, and cheaper. Halving model size with minimal impact is the kind of pragmatic gain that determines whether a project ships or stays confined to the lab.
As LLMs continue their seemingly inexorable march towards greater scale, hacks like Wanda—elegant, efficient, and grounded in observation—will be indispensable. It turns out you don’t always need a sledgehammer; sometimes, a well-aimed scalpel, guided by the right insight, does the job far better.