The AI Tooling Landscape: A Comprehensive Guide for Practitioners
Introduction
The rapid advancement of artificial intelligence has spawned a diverse ecosystem of tools that empower developers, researchers, and organizations to build, deploy, and evaluate AI systems with unprecedented efficiency. From optimizing large language models to run on consumer hardware to orchestrating complex agent workflows, today’s AI tooling addresses every phase of the machine learning lifecycle.
This article offers a curated exploration of the most impactful tools across the AI development spectrum. Whether you’re a researcher pushing the boundaries of what’s possible, an engineer implementing production systems, or a technical leader making strategic decisions about AI infrastructure, understanding this landscape will help you navigate the expanding universe of AI capabilities.

1. On-Device Inference & Model Compression
The democratization of AI requires making powerful models accessible on everyday hardware. These tools focus on optimizing large models to run efficiently on resource-constrained devices.
1.1 llama.cpp & llama2.c
- What They Are
llama.cpp: A C++ implementation by Georgi Gerganov that enables efficient CPU-based inference for Meta’s LLaMA and Llama 2 models with minimal hardware requirements.llama2.c: A minimalist, experimental implementation by Andrej Karpathy that distills Llama 2 into a single C file for educational purposes and extreme portability.
- Key Capabilities
- Run billion-parameter language models on consumer laptops and desktops
- Support various quantization techniques (4-bit, 8-bit) to reduce memory footprint
- Optimize inference speed through SIMD instructions and other low-level optimizations
- Enable offline, private AI experiences without cloud dependencies
- Real-World Applications
- Privacy-first solutions: Process sensitive data locally without transmitting to third-party servers
- Offline environments: Deploy AI capabilities in areas with limited connectivity
- Edge computing: Embed intelligence directly in IoT devices, medical equipment, or field tools
- Cost-effective deployment: Reduce cloud computing expenses for inference-heavy workloads

1.2 Sharded or “Parted” Models
- Core Concept
- Large models (especially those exceeding 30B parameters) often cannot fit in a single device’s memory
- Model sharding divides weights across multiple GPUs or machines, enabling collaborative inference
- Implementation Approaches
- Vertical sharding: Different layers run on different devices (pipeline parallelism)
- Horizontal sharding: Single layers split across multiple devices (tensor parallelism)
- Hybrid approaches: Combining multiple partitioning strategies for optimal performance
- Benefits and Considerations
- Scalability: Access to larger, more capable models beyond single-device constraints
- Cost distribution: Share computational burden across multiple resources
- Tradeoffs: Increased communication overhead and potential for higher latency
- Notable Examples
- DeepSpeed’s ZeRO (Zero Redundancy Optimizer)
- PyTorch’s FSDP (Fully Sharded Data Parallel)
- Petals’ peer-to-peer approach (discussed in Section 6)

2. Agent & Orchestration Frameworks
As AI systems grow more complex, developers need tools to coordinate multiple models, manage conversational context, and integrate with external services. These frameworks provide the architectural scaffolding for building sophisticated AI applications.
2.1 LangChain
- Core Functionality
- A Python/JavaScript framework that simplifies the creation of applications powered by language models
- Enables chaining together different components (prompts, models, memory systems, external tools) into cohesive workflows
- Key Components
- Chains: Combine multiple steps of LLM processing with fixed or dynamic sequencing
- Agents: Enable models to reason about which tools to use for solving complex problems
- Memory: Maintain conversation history and relevant context across interactions
- Retrievers: Access and query external knowledge bases or vector stores
- Callbacks: Monitor and log the execution of chains and agents
- Use Cases
- Question-answering systems with grounding in specific knowledge bases
- Autonomous agents that can plan and execute multi-step tasks
- Conversational applications with persistent memory and external tool usage
- Document analysis pipelines that combine extraction, summarization, and insight generation

2.2 Super AGI
- Platform Overview
- An open-source framework for creating, deploying, and managing autonomous AI agents
- Provides a visual interface for configuring agent behaviors and monitoring performance
- Distinctive Features
- Agent marketplace: Ready-to-use agents for common tasks
- Visual workflow builder: No-code/low-code interface for agent design
- Resource management: Controls for managing computational resources
- Multi-agent coordination: Tools for designing systems of cooperating agents
- Practical Applications
- Customer service automation with contextual awareness
- Research assistants that can explore topics across multiple sources
- Workflow automation agents that coordinate complex business processes
2.3 Semantic Kernel
- Framework Description
- Microsoft’s orchestration framework specifically designed for building AI copilots and assistants
- Integrates seamlessly with Azure OpenAI Service and other Microsoft cloud products
- Core Capabilities
- Skills: Encapsulate AI and traditional code into reusable modules
- Semantic functions: Bridge natural language and code execution
- Planning: Generate execution plans to solve complex tasks
- Memory: Maintain and retrieve contextual information
- Enterprise Focus
- Built with scalability and security considerations for large organizations
- Supports integration with enterprise data sources and compliance frameworks
2.4 TORA (Tool Integrated Roaming Agent)
- Architectural Approach
- An implementation pattern combining LLMs with a structured set of external tools
- Uses a ReAct-like approach (Reasoning + Acting) to solve complex tasks
- Key Mechanisms
- Tool registry: Centralized catalog of available capabilities
- Action selection: Logic for choosing appropriate tools based on task requirements
- Result integration: Methods for incorporating tool outputs into ongoing reasoning
- Differentiation
- Emphasizes systematic tool discovery and selection
- Focuses on robust error handling and recovery strategies
2.5 XAgent
- Framework Characteristics
- Designed for autonomous task execution with minimal human intervention
- Implements adaptive planning and self-correction mechanisms
- Advanced Features
- Task decomposition: Breaks complex goals into manageable subtasks
- Execution monitoring: Tracks progress and adjusts strategies as needed
- Tool learning: Improves tool usage based on past experiences
- Application Domains
- Software development assistance (code generation, debugging)
- Complex data analysis workflows
- Research and information synthesis
2.6 EdgeChains
- Framework Focus
- Optimized for edge computing and low-latency LLM applications
- Emphasizes efficient resource utilization in constrained environments
- Technical Highlights
- Reduced dependency footprint compared to larger frameworks
- Specialized for integration with edge computing platforms
- Support for intermittent connectivity scenarios
2.7 Pathway “LLM App” Framework
- Development Approach
- Streamlines creation of LLM-powered applications with a focus on data processing
- Provides patterns for high-throughput data handling and transformation
- Notable Capabilities
- Data pipelines: Efficient processing of large datasets for LLM consumption
- Streaming support: Real-time processing of continuous data sources
- Deployment tools: Simplified packaging and scaling of LLM applications

3. Evaluation & Assessment Tools
As AI systems become more complex and widely deployed, rigorous evaluation becomes increasingly important. These tools help measure performance, detect biases, and ensure quality across various dimensions.
3.1 Eval by OpenAI
- Framework Purpose
- Provides structured approaches to evaluating LLM outputs across various metrics
- Enables consistent benchmarking and comparative analysis
- Evaluation Capabilities
- Factual accuracy: Measure correctness of model-generated information
- Harmfulness assessment: Detect potentially problematic outputs
- Custom rubrics: Define domain-specific evaluation criteria
- Comparative evaluation: Benchmark different models or prompting strategies
- Practical Implementation
- Can be integrated into CI/CD pipelines for continuous quality monitoring
- Supports human-in-the-loop evaluation workflows
3.2 ReLLM (Reinforcement Learning for Language Models)
- System Overview
- Tools for analyzing and improving LLM reasoning patterns
- Focuses on enhancing model performance through feedback loops
- Key Components
- Output analysis: Identify patterns in model responses
- Reinforcement mechanisms: Improve model behavior based on feedback
- Comparative testing: Evaluate improvements across model iterations
- Use Cases
- Refining models for specific domains or tasks
- Addressing systematic reasoning errors
- Optimizing performance on targeted benchmarks
3.3 PSPy Framework
- Tool Description
- A specialized environment for debugging and analyzing AI pipelines
- Provides visibility into intermediate steps of complex workflows
- Technical Capabilities
- Trace visualization: See how information flows through multi-step processes
- Bottleneck identification: Locate performance constraints in complex pipelines
- Component testing: Isolate and evaluate individual elements of an AI system
- Research Applications
- Analyzing emergent behaviors in complex agent systems
- Debugging unexpected interactions between components
- Optimizing prompt chains and reasoning patterns

4. Model Training, Fine-Tuning & Data Preparation
Creating effective AI systems requires not just models but also the tools to train them on relevant data and adapt them to specific needs. This section covers frameworks that streamline these processes.
4.1 gpt-llm-trainer
- Tool Description
- A framework for efficient training and fine-tuning of GPT-like language models
- Simplifies the process of adapting foundation models to specific domains or tasks
- Technical Features
- Efficient fine-tuning: Optimize for performance with limited data and compute
- Parameter-efficient techniques: Support for LoRA, QLoRA, and other approaches
- Hyperparameter optimization: Tools for finding optimal training configurations
- Distribution support: Scale across multiple GPUs or nodes
- Practical Applications
- Creating industry-specific variants of foundation models
- Developing specialized assistants with domain expertise
- Adapting models to specific writing styles or conventions
4.2 LMQL.ai
- Language Overview
- A query language specifically designed for interacting with language models
- Combines natural language with programming constructs for precise control
- Key Capabilities
- Constrained generation: Define rules for acceptable outputs
- Structured extraction: Pull specific information from model generations
- Multi-turn interactions: Script complex conversations with LLMs
- Validation logic: Ensure outputs meet specific criteria
- Developer Benefits
- Reduces prompt engineering complexity
- Enables more predictable and consistent model outputs
- Facilitates integration of LLMs into larger software systems
4.3 MageAI / Loop
- Platform Capabilities
- End-to-end frameworks for building data pipelines and AI applications
- Bridge the gap between data preparation, model training, and deployment
- Core Features
- Visual pipeline building: Create complex workflows with minimal coding
- Data transformation tools: Clean and prepare training data efficiently
- Integration capabilities: Connect with diverse data sources and deployment targets
- Monitoring and management: Track performance and resource utilization
- Business Applications
- Accelerating AI project delivery through standardized workflows
- Enabling cross-functional collaboration between data scientists and engineers
- Simplifying the transition from prototype to production
4.4 “unstructured”
- Framework Purpose
- Extract, transform, and structure information from diverse document formats
- Convert raw data into forms suitable for model training or knowledge bases
- Processing Capabilities
- Document parsing: Handle PDFs, images, HTML, and other formats
- Layout understanding: Extract information while preserving structural context
- Content normalization: Standardize extracted data for consistent processing
- Entity recognition: Identify and categorize key information elements
- Implementation Value
- Reduces manual data preparation effort
- Improves training data quality through consistent processing
- Enables incorporation of diverse information sources

5. Specialized Optimizers & Additional Tools
Beyond the core categories, specialized tools address specific challenges in the AI development lifecycle, from optimizing training dynamics to generating multimedia content.
5.1 Velo & Nevera Optimizers
- Technical Approach
- “Learned optimizers” that discover improved update rules through meta-learning
- Adapt optimization strategies based on the characteristics of specific models or datasets
- Performance Benefits
- Potential for faster convergence compared to standard optimizers
- Improved final model quality in some domains
- Reduced sensitivity to hyperparameter choices
- Implementation Considerations
- May require additional computational overhead during initial setup
- Best suited for specialized applications where optimization is a bottleneck
- Can be combined with existing training infrastructure
The standard gradient descent update rule is:

Where: –  represents the model parameters at step
represents the model parameters at step 
–  is the learning rate
is the learning rate
–  is the gradient of the loss function
is the gradient of the loss function
Learned optimizers like Velo modify this update rule based on historical information and meta-learned patterns:

Where: –  is the learned update function with parameters
is the learned update function with parameters 
– 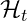 represents historical information about the optimization trajectory
represents historical information about the optimization trajectory
5.2 ShortGPT
- Tool Description
- An automation framework for creating short-form video content using AI
- Combines text generation, voice synthesis, and visual production
- Creation Pipeline
- Content planning: Generate scripts and storyboards
- Asset creation: Produce or select visuals and audio
- Editing automation: Assemble components into final productions
- Distribution preparation: Format for specific platforms and audiences
- Market Applications
- Social media content creation at scale
- Educational material development
- Marketing and promotional content

6. Distributed/Collaborative Inference
As model sizes grow, distributing computational load across multiple devices or even multiple organizations becomes increasingly important.
6.1 Petals
- System Concept
- A “BitTorrent for LLMs” that enables collaborative hosting and inference
- Distributes model layers across a network of volunteer computers
- Technical Architecture
- Layer-wise distribution: Different participants host different portions of the model
- Secure routing: Requests are processed across the network while preserving privacy
- Flexible participation: Join as a compute provider or consumer (or both)
- Practical Implications
- Democratized access: Run models too large for any single consumer device
- Resource sharing: Contribute and benefit from a community compute pool
- Reduced centralization: Less dependence on large cloud providers
- Limitations and Considerations
- Network reliability impacts inference performance
- Latency challenges for real-time applications
- Security and trust considerations across distributed nodes

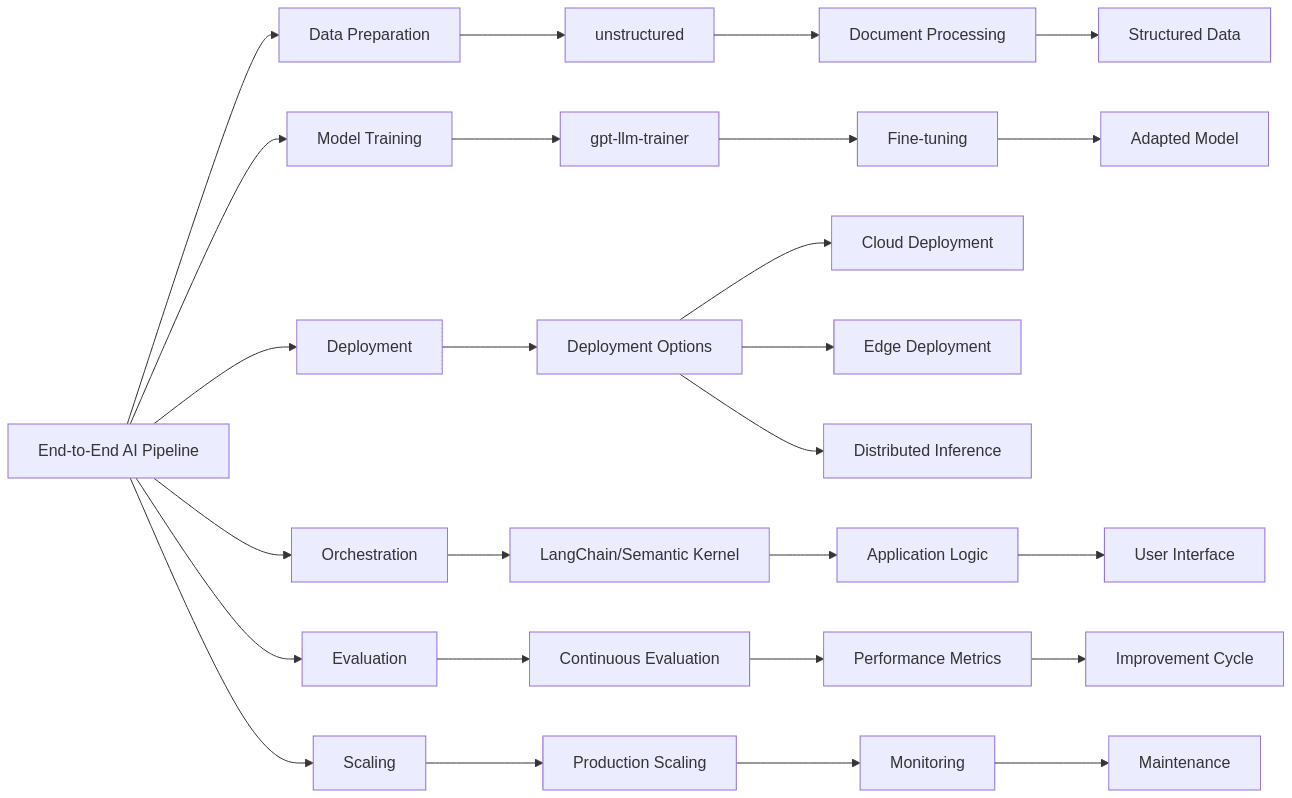
7. Practical Implementation: Building an End-to-End AI Pipeline
To illustrate how these tools can work together, here’s a comprehensive workflow that leverages multiple components from different categories.
7.1 Data Preparation & Compliance
- Use “unstructured” to:
- Convert diverse document formats into clean, consistent text
- Identify and redact personally identifiable information
- Segment content into appropriate training examples
- Extract structured data for fine-tuning or retrieval systems
7.2 Model Training & Adaptation
- Leverage
gpt-llm-trainerto:- Fine-tune foundation models on domain-specific data
- Implement parameter-efficient adaptation techniques
- Optimize for specific tasks or response patterns
- Optionally explore Velo or other learned optimizers to:
- Accelerate training convergence
- Improve final model quality
- Reduce sensitivity to learning rate selection
7.3 Deployment Architecture
For resource-intensive models:
– Implement sharding across multiple GPUs, or
– Utilize Petals for distributed community-based inference
– Consider llama.cpp or llama2.c for edge deployment scenarios
For production environments:
– Design redundancy and failover mechanisms
– Implement monitoring and alerting for performance issues
– Consider hybrid architectures combining local and cloud resources
7.4 Orchestration & Application Logic
- Build with LangChain or Semantic Kernel to:
- Create multi-step reasoning workflows
- Integrate external tools and data sources
- Manage conversation context and memory
- Implement retrieval-augmented generation
- For specialized use cases:
- Consider TORA or XAgent for autonomous task execution
- Explore EdgeChains for low-latency edge deployment
- Leverage Pathway for data-intensive processing requirements
7.5 Continuous Evaluation & Improvement
- Implement Eval by OpenAI to:
- Continuously assess output quality
- Monitor for bias or harmful outputs
- Compare performance across model versions
- Utilize ReLLM or PSPy to:
- Debug reasoning failures
- Optimize prompting strategies
- Identify areas for further fine-tuning
7.6 Scaling & Production Readiness
- Consider MageAI/Loop to:
- Standardize workflows across development and production
- Simplify deployment and scaling
- Enable monitoring and management by operations teams
8. Future Trends and Emerging Tools
As the AI landscape continues to evolve, several trends are shaping the next generation of tooling:
8.1 Efficiency-First Development
- Smaller, more efficient models are gaining traction as practical alternatives to massive systems
- Tools focusing on quantization, pruning, and distillation will become increasingly important
- Frameworks that optimize for battery life and thermal constraints on mobile devices
8.2 Multimodal Integration
- Rising demand for tools that seamlessly handle text, images, audio, and video
- Frameworks for cross-modal reasoning and content generation
- Specialized evaluation metrics for multimodal outputs
8.3 Collaborative AI Infrastructure
- More sophisticated distributed training and inference solutions
- Federated approaches that preserve data privacy while enabling collective improvement
- Community-maintained model weights and training resources
8.4 Specialized Vertical Solutions
- Industry-specific toolkits for healthcare, finance, legal, and other domains
- Pre-configured pipelines for common enterprise use cases
- Compliance-focused tools for regulated industries

9. Conclusion
The AI tooling landscape represents a vibrant ecosystem that continues to evolve at a remarkable pace. By understanding the strengths and applications of different tool categories—from on-device inference and model compression to orchestration frameworks and evaluation systems—practitioners can build more capable, efficient, and responsible AI systems.
The most effective implementations will likely combine multiple tools, creating customized pipelines tailored to specific requirements. As models continue to advance, the tooling that surrounds them will play an increasingly crucial role in unlocking their full potential while managing their limitations.
Whether you’re building a prototype, scaling to production, or researching new capabilities, the rich array of available tools provides a foundation for innovation. By staying informed about these evolving resources, you can navigate the technical challenges of AI development and focus on creating solutions that deliver genuine value.