Introduction
In the hyper-ventilating world of artificial intelligence and machine learning, one entity exerts something close to a gravitational pull on the hardware powering it all: NVIDIA. Forget market share percentages north of 95% for ML training, or the market cap rocketing past telephone numbers in 2023; those are just symptoms. NVIDIA’s dominance is a case study in building a platform so deeply entrenched, so meticulously interwoven with the fabric of the field, that alternatives struggle for oxygen. It’s one of the most potent examples of platform economics playing out in plain sight.
This piece digs into how NVIDIA carved out and defends its near-monopoly in AI compute. We’ll look beyond the chips to the strategic bedrock—the software, the co-design philosophy, the ecosystem—that makes escaping the NVIDIA orbit a non-trivial, often impractical, exercise for anyone serious about cutting-edge AI.
The CUDA Advantage: Building a Moat Filled With Engineering Hours
The cornerstone of NVIDIA’s empire is CUDA (Compute Unified Device Architecture). Rolled out in 2006, long before the current AI frenzy, it started as a parallel computing platform. It has since metastasized into arguably one of the most formidable moats in enterprise technology. It’s less a moat filled with water, more one filled with decades of accumulated, highly specialized engineering effort.
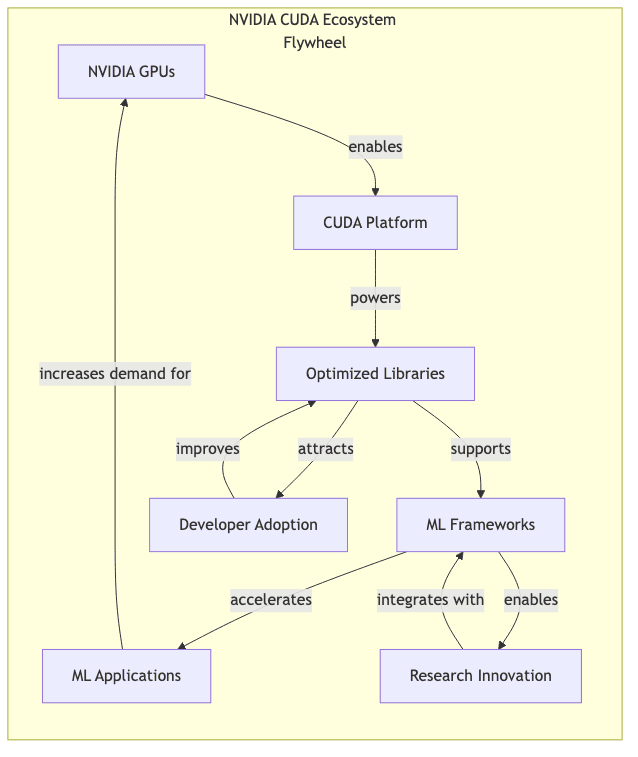
The Ecosystem Flywheel Effect
NVIDIA’s early, perhaps even prescient, insight was that hardware supremacy is transient. Long-term dominance demanded a software ecosystem that made the hardware indispensable. The strategy unfolded methodically:
- Seizing the Beachhead: Launching CUDA before ML went mainstream meant NVIDIA GPUs became the default substrate for nascent parallel computing explorations. When deep learning exploded, NVIDIA was already there, shovels in hand.
- Making the Difficult Accessible: CUDA offered a C-like interface, lowering the barrier for researchers to tap into GPU parallelism without needing degrees in arcane hardware architectures. It made the compute power usable.
- Forging the Tools: Critically, NVIDIA built and relentlessly optimized foundational libraries – cuDNN, cuBLAS, NCCL. These aren’t optional extras; they are the computational bedrock for virtually every significant ML framework. Trying to build serious ML without them is like trying to build a skyscraper without steel reinforcing bars.
The outcome? A textbook network effect. More developers built on CUDA, making NVIDIA GPUs more useful. More useful GPUs attracted more developers. Rinse, repeat. The inertia is now immense.
Operator Optimization: The Invisible Grind
A less appreciated, almost subterranean, aspect of NVIDIA’s lead is the obsessive optimization of mathematical operators – the fundamental verbs of neural networks.
- Down to the Metal: Operations like convolution, matrix multiplication, and attention are meticulously hand-tuned, often at the assembly level, for specific NVIDIA architectures. This is painstaking, brutal work.
- Relentless Refinement: NVIDIA dedicates armies of engineers solely to shaving microseconds off these operators. This continuous grind yields performance gains that competitors, focused on broader compatibility or newer architectures, find agonizingly difficult to replicate.
- Rapid Assimilation: When novel operators emerge from research papers (new attention mechanisms, different normalization layers), optimized NVIDIA implementations often materialize within weeks, integrated into the libraries researchers are already using.
// Simplified representation of how operator optimization works with CUDA
// This high-level pseudocode hides thousands of low-level optimizations
// Standard matrix multiplication
__global__ void matrixMul(float* A, float* B, float* C, int N) {
// Basic implementation
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
if (row < N && col < N) {
float sum = 0.0f;
for (int i = 0; i < N; i++) {
sum += A[row * N + i] * B[i * N + col];
}
C[row * N + col] = sum;
}
}
// NVIDIA's highly optimized version leverages:
// - GPU-specific memory hierarchy
// - Tensor core acceleration
// - Warp-level programming
// - Memory coalescing
// All invisible to the end-user but delivering 5-10x performanceEven if a competitor achieved theoretical architectural parity tomorrow, they would face the daunting task of replicating years and thousands of person-hours sunk into these operator-level optimizations just to achieve comparable real-world throughput. It’s a debt compounded by time.
Hardware-Software Co-Design: The Symbiotic Engine
NVIDIA doesn’t just design chips and then figure out the software. Their approach is fundamentally integrated: hardware and software evolve together, informing each other in a continuous feedback loop. It’s less like dropping a generic engine into a chassis and more like designing the engine and the vehicle as a single, optimized system.
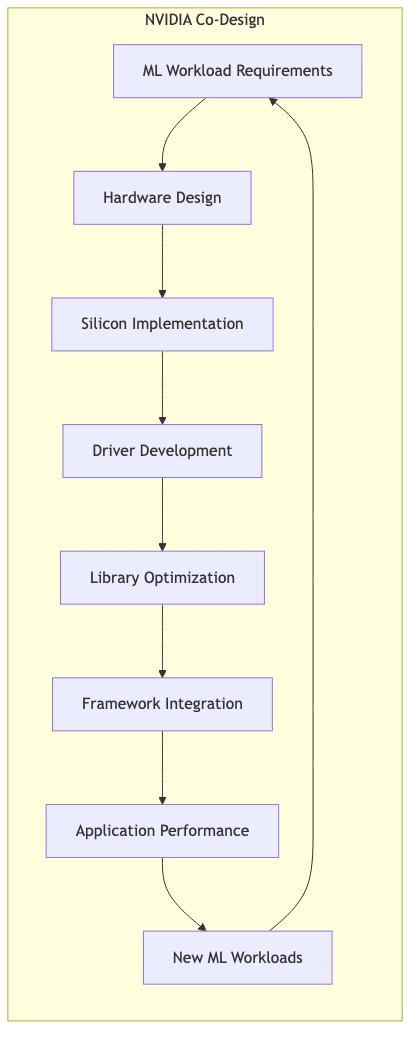
Purpose-Built Architecture for ML Workloads
This co-design philosophy manifests in hardware purpose-built for the demands of AI:
- Tensor Cores: Introduced with Volta (2017), they were specialized units designed explicitly to accelerate the mixed-precision matrix math at the heart of deep learning, anticipating the need before it became universally obvious.
- Memory Hierarchy: NVIDIA GPUs feature memory systems (caches, bandwidth, access patterns) tuned for the specific, often chaotic, demands of neural network training, not general-purpose computing.
- Scaling Prowess: Technologies like NVLink and NVSwitch weren’t afterthoughts. They were designed to tackle the challenge of training increasingly gargantuan models across multiple GPUs, enabling near-linear scaling where traditional interconnects falter.
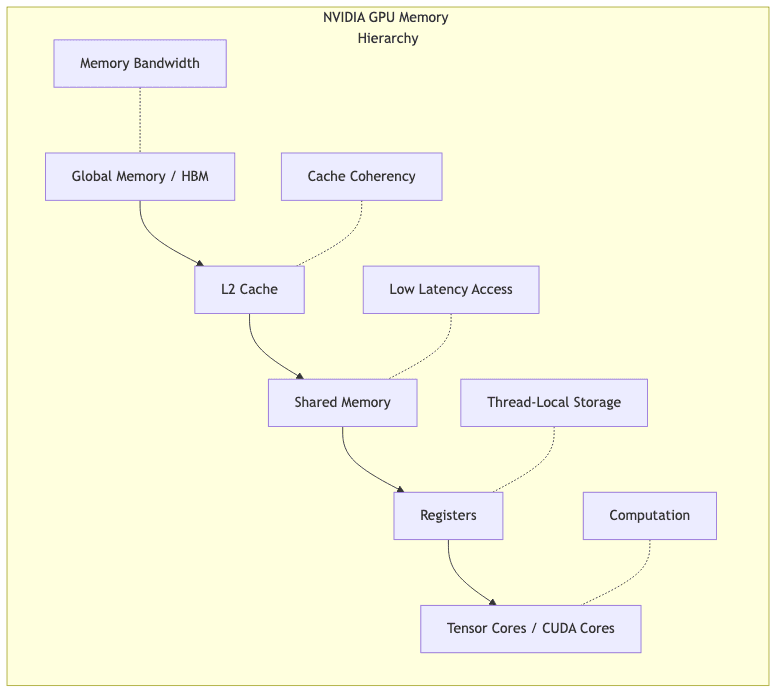
Memory Management Innovations
The “memory wall”—the persistent gap between compute speed and the ability to feed the beast with data—is a fundamental constraint. NVIDIA attacks this not just with brute force, but with strategy:
- High Bandwidth Memory (HBM): Pushing towards multi-terabyte-per-second bandwidth enabling larger models and faster iteration.
- Operator Fusion: Intelligently combining multiple compute steps in the pipeline to minimize round trips to main memory. This is software compensating for hardware physics.
- Hierarchical Memory Management: Employing sophisticated caching and prefetching tuned for ML workloads, reducing the latency penalty of accessing slower memory tiers.
The FLOPS Utilization Challenge
Here lies a crucial, often misunderstood, aspect of performance. Raw theoretical FLOPS (Floating Point Operations Per Second) mean little if the system can’t effectively use them.
- Achieving 60-70% FLOPS utilization on real-world, complex ML models is considered exceptional, even after years of software tuning. This is the reality gap between paper specs and usable power.
- NVIDIA’s mature, tightly integrated software stack is precisely what enables this high utilization. Competitors, even with comparable theoretical FLOPS, often struggle to sustain 30-40% on the same workloads due to software immaturity or lack of specific optimizations.
- This disparity makes direct FLOPS comparisons between NVIDIA and rivals fundamentally misleading. The number on the box tells you little about the speed on the road.
| Hardware | Theoretical FLOPS | Typical ML Utilization | Effective FLOPS |
|---|---|---|---|
| NVIDIA A100 | 312 TFLOPS (FP16) | 60-70% | 187-218 TFLOPS |
| Competitor X | 300 TFLOPS (FP16) | 30-40% | 90-120 TFLOPS |
| Competitor Y | 350 TFLOPS (FP16) | 25-35% | 87-122 TFLOPS |
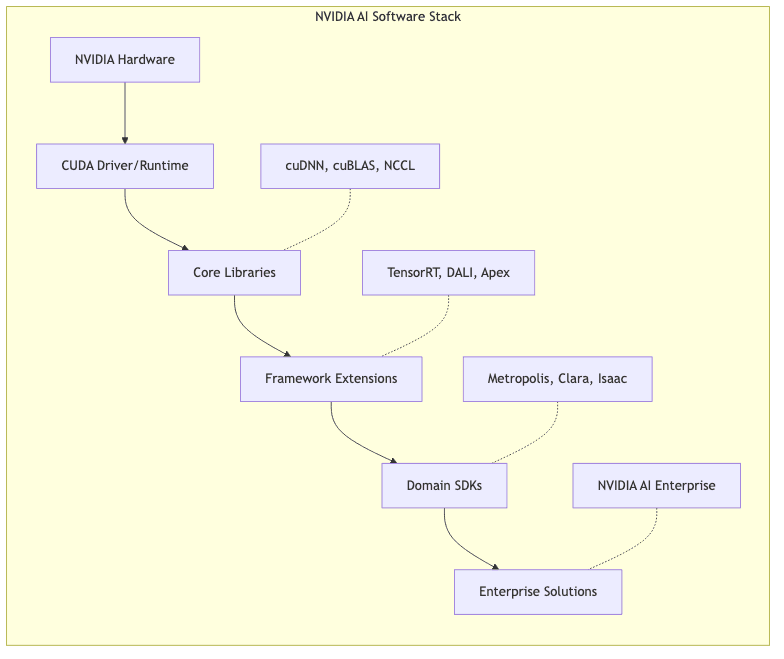
Beyond CUDA: The Broader Ecosystem Advantage
The dominance isn’t just CUDA and the core math libraries. NVIDIA has systematically built out a supporting universe of tools and frameworks, further cementing its position by reducing friction across the entire ML lifecycle:
- Development Tools: Profilers (like Nsight), debuggers, visualization tools – essential plumbing that developers rely on.
- Domain-Specific Stacks: Ready-made solutions like Metropolis (vision), Clara (healthcare), Isaac (robotics) provide pre-optimized pipelines for specific industries, saving developers immense effort.
- Enterprise Integration: Ensuring the software plays nice with major cloud platforms and enterprise IT infrastructure, making adoption the path of least resistance.
A Practical Example: PyTorch on NVIDIA GPUs
Consider the deceptive simplicity of matrix multiplication in PyTorch on an NVIDIA GPU:
import torch
import time
# Create large matrices on GPU
N = 4096
x = torch.randn(N, N, device="cuda")
y = torch.randn(N, N, device="cuda")
# Warmup run to eliminate initialization overhead
warmup = torch.matmul(x, y)
torch.cuda.synchronize()
# Benchmark matrix multiplication
start = time.time()
z = torch.matmul(x, y) # This one line triggers numerous NVIDIA optimizations
torch.cuda.synchronize()
elapsed = time.time() - start
# Calculate performance metrics
operations = 2 * N**3 # Multiply-adds in matrix multiplication
tflops = operations / elapsed / 1e12
print(f"Matrix multiplication of size {N}x{N} completed in {elapsed:.4f} seconds")
print(f"Effective performance: {tflops:.2f} TFLOPS")That single torch.matmul(x, y) line triggers a cascade of optimizations hidden beneath the surface:
- Hardware-aware precision selection (using FP16 or TF32 if beneficial and supported).
- Optimal memory layouts chosen for the specific GPU model.
- Automatic offloading to Tensor Cores where applicable.
- Potential kernel fusion to minimize data movement.
- Selection from multiple underlying algorithms based on matrix size and hardware specifics.
This automatic “magic” isn’t magic at all; it’s the distilled result of thousands of engineering hours, completely abstracted from the end-user. Achieving similar performance on alternative hardware would likely require months, if not years, of dedicated, low-level engineering effort per application.
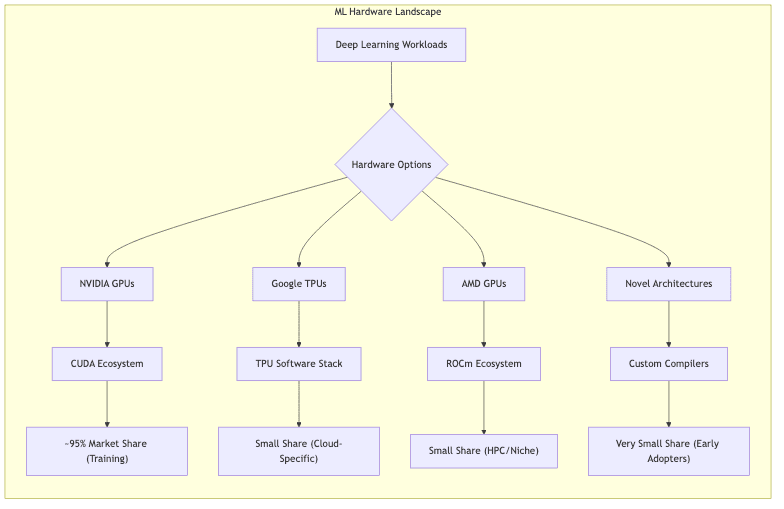
The Competitive Landscape: Contenders or Pretenders?
Despite the imposing nature of NVIDIA’s advantage, others are trying to chip away at the monolith:
Google TPUs
- Pros: Designed for ML, tight TensorFlow/JAX integration, strong in specific architectures (especially large Transformers).
- Cons: Primarily captive within Google Cloud, less versatile across diverse workloads, ecosystem still smaller than CUDA’s.
AMD ROCm
- Pros: Hardware specs are increasingly competitive on paper. Open-source aspirations.
- Cons: The software gap remains vast. ROCm’s ecosystem, library support, and operator optimization lag significantly behind CUDA. Compatibility remains a persistent headache.
New Entrants: Cerebras, Graphcore, SambaNova, etc.
- Angle: Radical departures from GPU architecture, purpose-built AI silicon.
- Hurdles: Immature software stacks are the killer. Convincing developers to learn new tools and rewrite code for unproven platforms is an enormous barrier against CUDA’s inertia.
The Open-Source Challenge: PyTorch 2.0 (TorchDynamo/Triton), OpenXLA
- Ambition: Create hardware-agnostic compiler layers (like OpenAI’s Triton) that could abstract away CUDA, allowing code to run efficiently on diverse hardware.
- Reality: A noble goal, and progress is being made, but they are still playing catch-up. Matching the breadth, depth, and sheer performance of NVIDIA’s hand-tuned libraries across the full spectrum of models remains a distant prospect.
Future Outlook: Can Anyone Dethrone NVIDIA?
Dislodging NVIDIA requires overcoming a confluence of deeply entrenched advantages:
- Ecosystem Lock-In: Decades of code, tools, libraries, and workflows are built assuming CUDA. Rewriting or porting is a massive undertaking.
- Talent & Training: The vast majority of ML engineers and researchers learn and work within the NVIDIA/CUDA ecosystem. This self-perpetuates the dominance.
- The Performance Chasm: It’s not enough for a competitor to match NVIDIA’s current performance. They need a compelling, sustained advantage to justify the immense switching costs and risks.
Paths to potential disruption exist, but they are steep and uncertain:
- Standardization Efforts: Hardware-agnostic APIs (SYCL, oneAPI, WebGPU?) could gain traction, but momentum has been slow, and performance parity elusive.
- Cloud Abstraction Layers: Cloud providers have an incentive to commoditize hardware. If they can build sufficiently performant abstraction layers, the underlying chip vendor might become less critical, but this is technically challenging.
- Niche Dominance: Competitors might carve out specific domains (e.g., ultra-low-power inference, specialized scientific computing) where NVIDIA’s general-purpose approach is less optimal, using that as a beachhead.
Conclusion
NVIDIA’s reign in AI/ML compute is more than just good chip design; it’s a masterclass in building and defending a technological platform. The tightly woven fabric of hardware-software co-design, relentless optimization, and comprehensive ecosystem development has created a strategic advantage that transcends benchmarks. It’s the system that dominates.
While the AI hardware market booms and new contenders emerge, NVIDIA’s integrated approach means it’s likely to remain the default choice, the bedrock upon which much of AI innovation is built, for the foreseeable future. For those operating at the bleeding edge, NVIDIA, for many complex workloads, remains functionally the only viable option. It’s a demonstration of how deep technical investment, coupled with strategic ecosystem control, can shape the trajectory of an entire industry. The question isn’t if NVIDIA maintains its lead, but how this concentration of foundational power will influence the future of AI itself.