Key Takeaways
- Expert‑Choice Routing (ECR) in sparse Mixture‑of‑Experts (MoE) models, a clever trick for efficiency, opens up a subtle but potent side‑channel that can leak a user’s entire prompt.
- The vulnerability is born from deterministic token dropping when an expert’s capacity is full; a tie‑breaking rule based on batch order becomes an oracle, revealing if an attacker’s guess matches a victim’s token.
- By batching their queries alongside a victim’s and observing the model’s outputs, an attacker can iterate through the vocabulary and reconstruct prompts with
remote queries.
- Practical defenses exist-per-user batch isolation, randomized routing, or switching to more robust routing algorithms-but they come with their own trade-offs.
Introduction
The relentless pursuit of scale in Large Language Models (LLMs) has an equally relentless appetite for compute. Mixture‑of‑Experts (MoE) architectures offer a seductive bargain: keep trillions of parameters on tap, but only activate a fraction for any given token, slashing inference costs. It’s an elegant solution to a brute-force problem. The price we pay for this efficiency, as I discovered digging through the research and code, is a new and subtle class of security vulnerabilities.
In this article, I’ll walk through the MoE Tiebreak Leakage attack-a technique allowing an adversary to steal another user’s prompt by exploiting the very mechanics of Expert‑Choice Routing (ECR). We’ll cover the intuition, the step-by-step mechanics, the empirical proof, and finally, how we might harden our production MoE stacks against this kind of bleed.
Background
What is a Mixture‑of‑Experts Layer?
At its core, a standard Transformer layer forces every token through the same monolithic feed-forward network (FFN). An MoE layer guts this design, replacing the single FFN with a stable of parallel “experts” and a gate that acts as a router, deciding where each token goes. Only
experts are activated per token, achieving a sparse activation pattern that saves immense amounts of computation.
Expert‑Choice Routing (ECR)
ECR flips the script on conventional gating. Instead of tokens choosing experts, each expert independently chooses its favorite tokens from the entire batch. This capacity,
, is a fixed budget, calculated as:
where is the batch size,
is the sequence length, and
is the capacity factor. If more than
tokens are vying for the same expert, the lowest-priority tokens are unceremoniously dropped. They bypass the FFN entirely, carried forward only by their residual connection.
This deterministic dropping is brilliant for load-balancing. But it shatters a fundamental assumption of batched inference: in-batch independence. One user’s tokens can now directly displace another’s. And in that displacement, information leaks.
Threat Model
I assume an attacker who:
- Can run their own queries against a hosted MoE model. White-box access to the weights is helpful for prep work but not strictly necessary for the core exploit.
- Can arrange for their queries to be batched alongside a victim’s prompt. This is a common scenario in shared inference endpoints, multi-tenant clouds, or any system prioritizing high utilization over strict isolation.
- Can call the model repeatedly and observe the full output logits. A slightly weaker oracle-access to just log-probabilities-still works in practice.
Anatomy of the MoE Tiebreak Leakage Attack
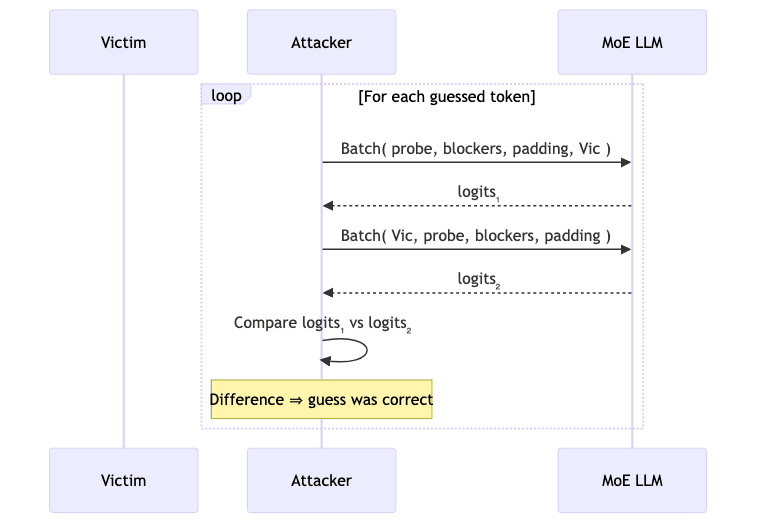
1. The Oracle Query: Token Guessing
The attack proceeds token by token. The attacker maintains a known prefix of the victim’s prompt (starting empty) and systematically cycles through every possible token in the vocabulary as a guess for the next position.
2. Crafting the Adversarial Batch
For each guess, the attacker constructs a carefully engineered batch containing four components:
| Component | Purpose |
|---|---|
| Probe sequence | Contains the known prefix + guessed token. The output logits for this sequence are our signal. |
| Blocking sequences | Packed with high-affinity tokens designed to flood the target expert until only a single slot remains. |
| Padding sequence | Fills the batch to push expert capacity beyond 32 tokens, forcing CUDA’s torch.topk to use a stable radix sort. This is key. |
| Victim message | The confidential prompt we aim to extract. |
3. The Tell: Dual Queries
The attacker sends this crafted batch to the model twice, with one crucial difference: the order of the probe and victim messages is swapped.
Here’s the logic: if the attacker’s guessed token is identical to the victim’s actual token, they will have the exact same affinity score for the target expert. Thanks to the blockers, they are now tied for the last available slot. Because the sorting algorithm is stable, the tie is broken based on their original position in the batch.
When the probe is first, it gets the slot. When the victim is first, it gets the slot, and the probe is dropped. This dropping event measurably changes the probe’s output logits. If the guess was wrong, their affinities differ, the tie never occurs, and swapping their order has no effect. The twitch in the logits is the tell.
4. Path Recovery
In multi-layer models, attention layers mix token representations, complicating which expert to target. To solve this, the attacker can pre-compute routing path lookup tables locally. The authors’ open-source code shows how to do this by toggling experts off and enumerating all paths, though in practice a Hamming-distance heuristic makes this tractable.
5. Complexity
The full leakage attack requires remote queries and
times more local simulations-brute-forceable, but expensive. A far more chilling oracle variant, used to validate a fully-formed candidate prompt, collapses this to just two remote calls.
Empirical Highlights
I reproduced the core experiment on a sliced two-layer Mixtral-8×7B configured with ECR. The results were unambiguous:
- 99.9% of 4,838 secret tokens were successfully extracted.
- The process averaged around 100 remote queries per recovered token.
- Optimal padding length was around 40 tokens. Too small, and the victim’s token is dropped by default; too large, and the blockers begin to interfere with each other.
import torch
# On GPU, topk with k > 32 uses a stable radix sort.
# This determinism is the fulcrum on which the attack pivots.
x = torch.tensor([1.] * 64, device="cuda")
_, idx = torch.topk(x, k=x.numel())
print(idx[:8]) # prints tensor([0, 1, 2, 3, 4, 5, 6, 7], device='cuda:0')🛈 On CPU,
torch.topkdefaults to an unstable bitonic sort for small inputs (≤32 elements). The attack’s padding is specifically designed to force the operation onto the GPU’s stable path.
Mitigations
So, how do we plug this leak?
- Batch Isolation: The most robust fix. Never mix requests from different customers in the same micro-batch. This is also the most expensive, as it sacrifices utilization.
- Randomized Routing: A cheaper patch. Add a small amount of noise to the gating scores or shuffle the batch order before routing. This makes the attack probabilistic rather than deterministic, but doesn’t eliminate it. It feels a bit like security through obscurity.
- Capacity Oversubscription: Dynamically increase an expert’s capacity
when utilization spikes. This reduces forced drops but adds computational overhead and complexity.
- Stable + Private Routing: The most principled fix. Adopt more advanced hashing-based or stochastic routing algorithms that are designed from the ground up to eliminate deterministic tie-breaks.
Related Work & Further Reading
- Switch Transformers first introduced token-wise gating but ran into similar capacity overflow issues.
- Hayes et al. previously identified a DoS-style buffer overflow in MoE. This Tiebreak Leakage attack turns the same underlying behavior into a full-blown information exfiltration channel.
- The Mixtral implementation on GitHub is an excellent playground for exploring these dynamics. Combine it with the authors’ proof-of-concept scripts to replicate the findings.
- For a broader survey of MoE routing algorithms, the review by Cai et al. (2024) is a great starting point.
Conclusion
Sparse MoE layers are a testament to engineering ingenuity, promising massive efficiency gains. But they ship with hidden assumptions about batch independence. When those assumptions are violated, privacy breaks with them.
My takeaway-as both an engineer and a security-minded researcher-is that the blind optimization for throughput must never outrank adversarial thinking. As we rush to deploy ever-larger expert models, we have a duty to our users to harden routing logic, monitor batch composition, and, when in doubt, fall back to the boring-but hermetic-reliability of dense layers. A system’s integrity is only as strong as its most subtle leak.