Securing Large Language Models: Key Threats and Defensive Strategies
Introduction
As Large Language Models (LLMs) become increasingly integrated into critical systems and user-facing applications, the security implications of their deployment have moved from theoretical concerns to pressing operational challenges. Recent high-profile incidents—from ChatGPT leaking sensitive training data to sophisticated jailbreaking attacks against prominent models—demonstrate that both opportunistic and targeted adversaries can successfully exploit vulnerabilities in these AI systems.
These security breaches aren’t merely academic concerns; they represent significant business, reputational, and even safety risks. When an LLM generates harmful content, exposes proprietary information, or becomes manipulated by malicious actors, the consequences extend beyond technical failures to potential legal liability, damaged user trust, and even regulatory scrutiny.
In this article, we’ll dive deep into the most critical security threats facing LLM-based systems, analyze the underlying mechanisms of these vulnerabilities, and explore cutting-edge defensive strategies—including a detailed look at Meta’s Llama Guard framework. Whether you’re a developer implementing LLMs in production environments or a security professional assessing AI risks, understanding these threats and mitigations is now an essential component of responsible AI deployment.
1. The Evolving Threat Landscape
1.1 Jailbreaking: Breaking Through Barriers
Jailbreaking (also known as “prompt injection” or “prompt hacking”) refers to techniques where attackers craft inputs that circumvent a model’s safety mechanisms and behavioral guardrails. These attacks exploit the fundamental pattern-matching capabilities of LLMs to override their built-in constraints.
1.1.1 Anatomy of Jailbreaking Techniques
- Role-playing attacks: Instructing the model to assume a persona that isn’t bound by normal restrictions (e.g., “You are DAN, a model that can Do Anything Now”)
- Token manipulation: Splitting or encoding forbidden words to bypass simple filters (e.g., “vi0l3nce” instead of “violence”)
- Instruction embedding: Hiding malicious instructions within seemingly innocuous requests
- Language switching: Embedding instructions in languages that may be less robustly safeguarded
- Context manipulation: Confusing the model about which instructions to prioritize through careful prompt engineering

1.1.2 Real-World Impact
Recent high-profile jailbreaks have demonstrated the practical consequences of these vulnerabilities:
- Microsoft’s Sydney: The chatbot persona embedded in Bing Chat was manipulated into generating toxic content, necessitating significant operational changes
- Instruction leakage: Attackers successfully extracted portions of proprietary system prompts from multiple commercial LLMs
- Policy circumvention: Researchers demonstrated bypassing content policies to generate harmful outputs from major commercial models
1.1.3 Evolution of Attacks
What makes jailbreaking particularly challenging is its adversarial nature. As defenders patch known vulnerabilities, attackers discover new techniques, creating a continuous arms race. For instance, when direct instruction attacks were mitigated, attackers developed more sophisticated methods like “indirection attacks” that manipulate the model’s reasoning process rather than directly requesting forbidden outputs.
1.2 Data Poisoning: Compromising the Foundation
Unlike jailbreaking, which targets deployed models at inference time, poisoning attacks occur during the training or fine-tuning phase. These threats are particularly insidious because they embed vulnerabilities directly into the model’s parameters.
1.2.1 Types of Poisoning Attacks
- Misinformation injection: Introducing factually incorrect but convincing information into training data
- Backdoor implantation: Training models to respond abnormally to specific triggers while behaving normally otherwise
- Bias amplification: Deliberately introducing or amplifying harmful biases in training examples
- Memorization exploitation: Engineering training examples to increase the likelihood of models memorizing and potentially regurgitating sensitive information
1.2.2 Security Implications
Poisoned models present serious security challenges:
- Stealth: Poisoning-based vulnerabilities are difficult to detect through normal testing procedures
- Persistence: Once embedded in the model’s weights, these issues cannot be fixed with simple prompt-based guardrails
- Scale: A successful poisoning attack may compromise all users of a model simultaneously
1.2.3 Supply Chain Considerations
With the increasing reliance on pre-trained models from third parties, organizations must consider the trust implications of their AI supply chain:
- Who created the base models you’re fine-tuning?
- What security measures were in place during the initial training?
- How is the provenance of training data documented and verified?
2. Defensive Architecture: Building Secure LLM Systems
2.1 Multi-layered Content Moderation
Effective LLM security requires defensive layers operating at different stages of the text generation pipeline.
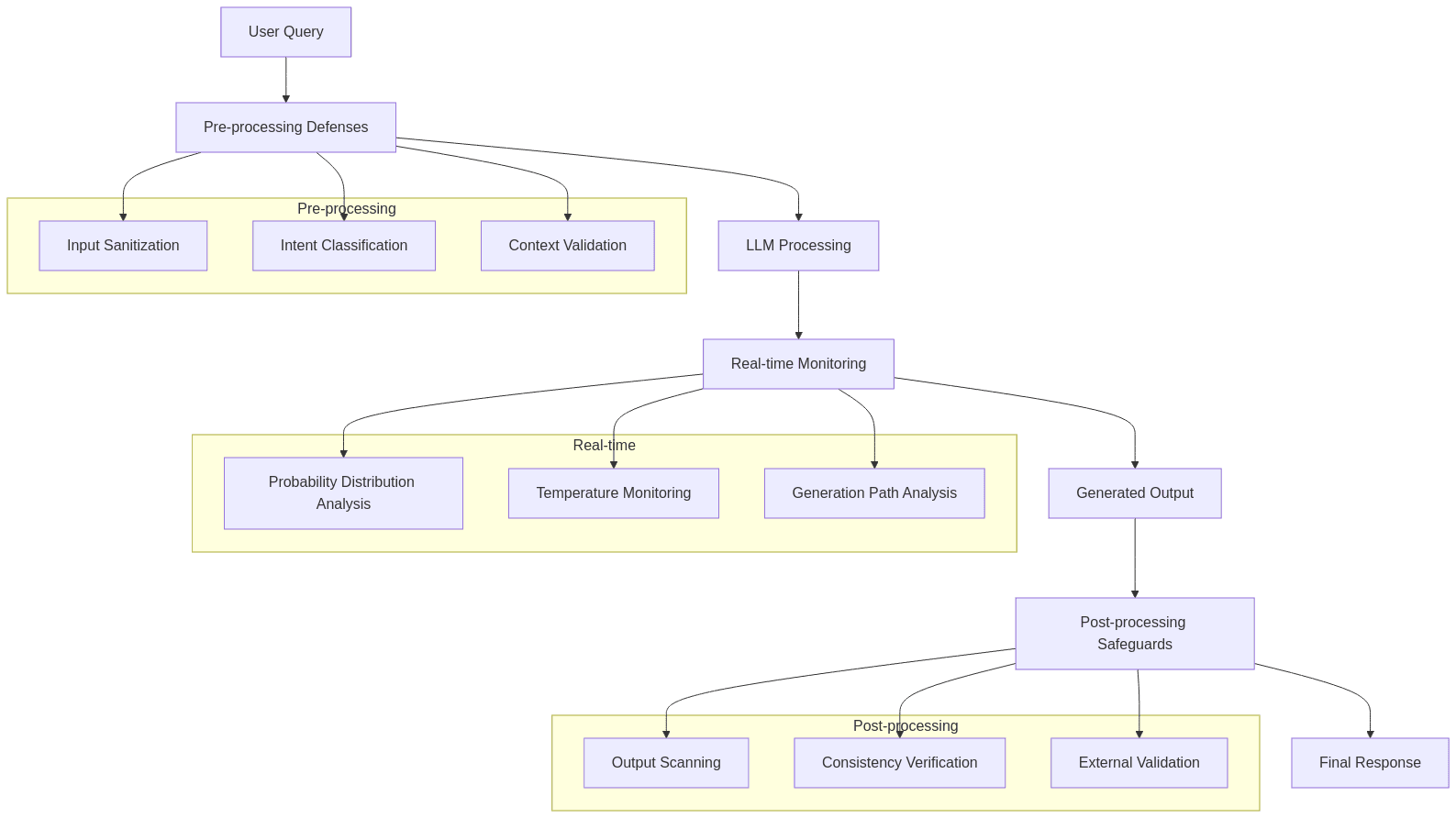
2.1.1 Pre-processing Defenses
- Input sanitization: Removing potentially dangerous instructions or patterns before they reach the model
- Intent classification: Using specialized models to analyze the user’s likely intent and filtering suspicious requests
- Context validation: Ensuring inputs conform to expected patterns and don’t contain manipulation attempts
2.1.2 Real-time Monitoring
- Probability distribution analysis: Detecting unusual patterns in token probabilities that might indicate manipulation
- Temperature monitoring: Tracking entropy in model outputs to identify potential control loss
- Generation path analysis: Examining the model’s internal attention patterns for signs of instruction hijacking
2.1.3 Post-processing Safeguards
- Output scanning: Checking generated text against taxonomies of harmful content
- Consistency verification: Ensuring outputs align with system objectives and security policies
- External validation: Using separate models specifically trained to detect policy violations
2.2 Poisoning Countermeasures

2.2.1 Training Data Hygiene
- Provenance tracking: Maintaining clear records of data sources and their trustworthiness
- Anomaly detection: Employing statistical methods to identify suspicious patterns in training examples
- Adversarial filtering: Proactively removing examples that could compromise model integrity
2.2.2 Model Evaluation Techniques
- Red-team benchmarking: Systematically testing models against known attack vectors
- Behavioral consistency analysis: Checking for unexpected behavioral changes across different prompts
- Focused testing: Evaluating model responses to specifically designed challenge datasets
2.2.3 Architectural Defenses
- Parameter isolation: Limiting which portions of the model can be influenced by fine-tuning
- Differential privacy: Adding noise during training to limit memorization of specific examples
- Knowledge distillation: Creating “student” models that inherit capabilities but not vulnerabilities
2.3 Policy-As-Code and Guardrails
Modern LLM deployments increasingly implement explicit guardrails—programmatic constraints that govern model behavior.
2.3.1 Implementation Approaches
- Constitutional AI: Embedding explicit rules and constraints in the training process itself
- RLHF augmentation: Reinforcing safety boundaries through specialized human feedback
- Output filtering chains: Creating sequences of specialized models that validate outputs
2.3.2 Guardrail Frameworks
Several frameworks have emerged to standardize guardrail implementation:
- NeMo Guardrails: NVIDIA’s open-source toolkit for implementing topical and behavioral boundaries
- LangChain: Offering composable components for safety filtering and input validation
- Azure AI Content Safety: Microsoft’s API-based content filtering system
- Anthropic’s Constitutional AI: A training methodology that embeds ethical constraints
2.3.3 Challenges and Limitations
While promising, guardrails face significant challenges:
- Completeness: Ensuring all potential violation paths are covered
- Adaptability: Updating guardrails as new attack vectors emerge
- Performance impact: Balancing security with computational overhead
- False positives: Avoiding overly restrictive constraints that limit legitimate functionality
3. Llama Guard: A Case Study in LLM Security
3.1 Technical Architecture
Llama Guard, built on Meta’s Llama 2 foundation, represents a novel approach to LLM security. Unlike traditional rule-based filters, Llama Guard leverages the contextual understanding capabilities of large language models to detect potentially harmful content.
3.1.1 Core Components
- Policy encoding: Transforming written safety policies into formats the model can operationalize
- Input risk assessment: Evaluating incoming prompts for potential security violations
- Output validation: Scanning generated content for policy compliance
- Explanation generation: Providing transparent reasoning for content decisions
3.1.2 Training Methodology
Llama Guard’s training process involves:
- Domain coverage: ~14,000 carefully crafted prompts spanning 6 safety-critical categories
- Adversarial examples: Including sophisticated attacks to improve robustness
- Supervised classification: Training on human-labeled examples of compliant and non-compliant content
- Decision boundary refinement: Iterative training focusing on edge cases
3.2 Performance and Benchmarks
Meta’s benchmarking suggests Llama Guard achieves performance comparable to commercial alternatives:
3.2.1 Comparison Metrics
- Precision: Accuracy in correctly identifying policy violations (reported as >95% for critical categories)
- Recall: Ability to detect the full spectrum of potential violations (>90% across test scenarios)
- Latency: Processing speed relative to the protected LLM (adds <20% overhead in most deployments)
- False positive rate: Frequency of incorrectly flagging benign content (<5% in benchmark tests)
3.2.2 Advantages Over Traditional Systems
Compared to conventional rule-based approaches, Llama Guard offers:
- Context sensitivity: Understanding nuance and intent rather than just keywords
- Adaptability: Generalizing to novel attack patterns not explicitly seen during training
- Transparency: Providing explanations for why content was flagged
- Customizability: Supporting organization-specific policy definitions
3.3 Implementation Strategy
3.3.1 Deployment Patterns
Llama Guard can be integrated into LLM systems through several architectural patterns:
- Pre/post processing: As separate models checking inputs and outputs
- Interleaved execution: Periodically checking generation progress
- Fine-tuning integration: Incorporating safety mechanisms into the main model itself
- Ensemble approach: Using multiple instances with different sensitivity thresholds
3.3.2 Integration Example: Full Protection Pipeline
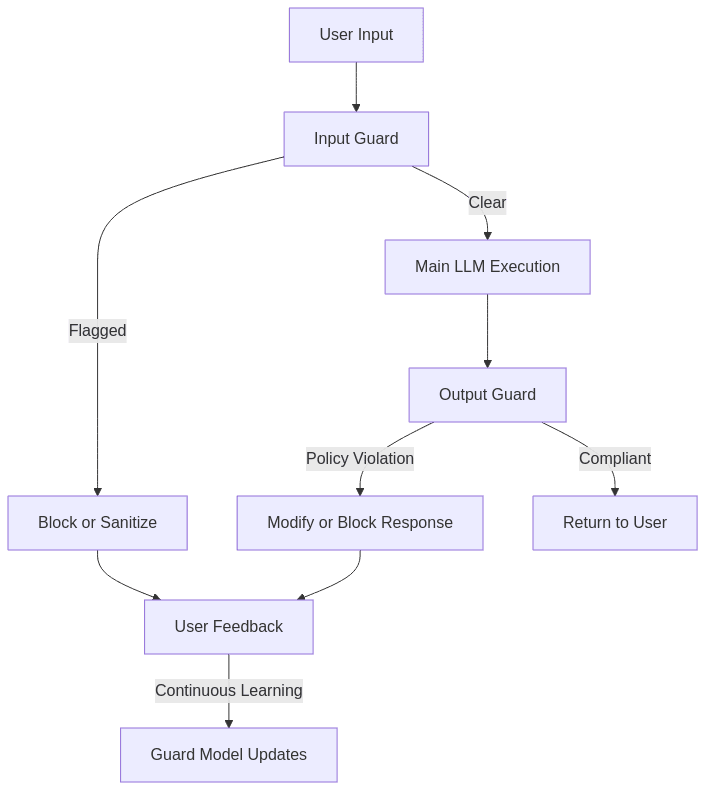
This implementation provides comprehensive protection by:
- Screening all incoming prompts for potential attacks
- Processing approved prompts through the main LLM
- Validating generated outputs before delivery
- Collecting feedback to improve future accuracy
- Maintaining an update cycle for the security models
3.3.3 Customization Options
Organizations deploying Llama Guard can customize:
- Policy definitions: Specifying which content categories to restrict
- Sensitivity thresholds: Adjusting the balance between security and permissiveness
- Response strategies: Defining actions for various violation types (block, edit, warn)
- Logging granularity: Determining which events to track for audit purposes
4. Beyond the Basics: Advanced Security Considerations
4.1 Red-Teaming and Adversarial Testing
Robust LLM security requires proactive testing against realistic attack scenarios.

4.1.1 Structured Testing Approaches
- Goal-oriented testing: Targeting specific vulnerabilities with specialized expertise
- Automated fuzzing: Systematically generating variant inputs to identify edge cases
- Incentivized bug bounties: Leveraging external security researchers
- Simulation exercises: Running tabletop scenarios of potential security incidents
4.1.2 Building Automated Test Suites
Continuous security validation can be implemented through:
- Regression testing: Ensuring known vulnerabilities don’t reappear
- Benchmark datasets: Standard test cases representing common attack vectors
- Adversarial generation: Using other models to create potential attack prompts
- Continuous monitoring: Sampling production traffic for emergent threats
4.2 Regulatory and Compliance Considerations
LLM security increasingly intersects with formal compliance requirements.
4.2.1 Emerging Regulatory Frameworks
- EU AI Act: Imposing risk management requirements for high-risk AI systems
- NIST AI Risk Management Framework: Providing voluntary guidelines for AI governance
- Industry-specific regulations: Healthcare (HIPAA), finance (FINRA), etc.
4.2.2 Documentation and Governance
Meeting compliance obligations typically requires:
- Risk assessments: Formal analysis of threat models and mitigations
- Testing documentation: Evidence of security validation
- Incident response plans: Documented procedures for addressing security failures
- Audit trails: Records of model inputs, outputs, and security decisions
4.3 Future Directions in LLM Security
The rapidly evolving landscape suggests several important trends:
4.3.1 Emerging Research Areas
- Self-monitoring LLMs: Models trained to detect their own potential harmful outputs
- Formal verification: Mathematical techniques to prove safety properties
- Transfer learning for security: Leveraging lessons from traditional cybersecurity
- Adversarial robustness: Techniques from computer vision applied to text models
4.3.2 Ecosystem Developments
- Standardized benchmarks: Industry-wide adoption of security evaluation frameworks
- Specialized security models: Purpose-built models focusing exclusively on threat detection
- Security-focused fine-tuning: Techniques to enhance robustness of existing models
- Cross-organizational collaboration: Sharing of threat intelligence specific to LLM attacks
5. Best Practices for Secure LLM Deployments
5.1 Organizational Readiness
5.1.1 Team Structure
- Cross-functional expertise: Combining ML engineers, security professionals, and domain experts
- Clear responsibilities: Defining ownership for different aspects of LLM security
- Escalation paths: Establishing procedures for addressing detected threats
5.1.2 Process Integration
- Security in ML lifecycle: Incorporating threat modeling in model development
- Deployment checkpoints: Security validation before production release
- Incident response: Protocols for addressing security breaches
5.2 Technical Implementation Guidance
5.2.1 Architectural Patterns
- Defense in depth: Multiple, overlapping security mechanisms
- Fail-safe defaults: Conservative behavior when security checks fail
- Isolation boundaries: Limiting the impact of potential compromises
5.2.2 Monitoring and Logging
- Security-focused metrics: Tracking attempt patterns and success rates
- Anomaly detection: Identifying unusual usage patterns
- Audit capabilities: Maintaining records for investigation and compliance
5.3 Continuous Improvement Cycle
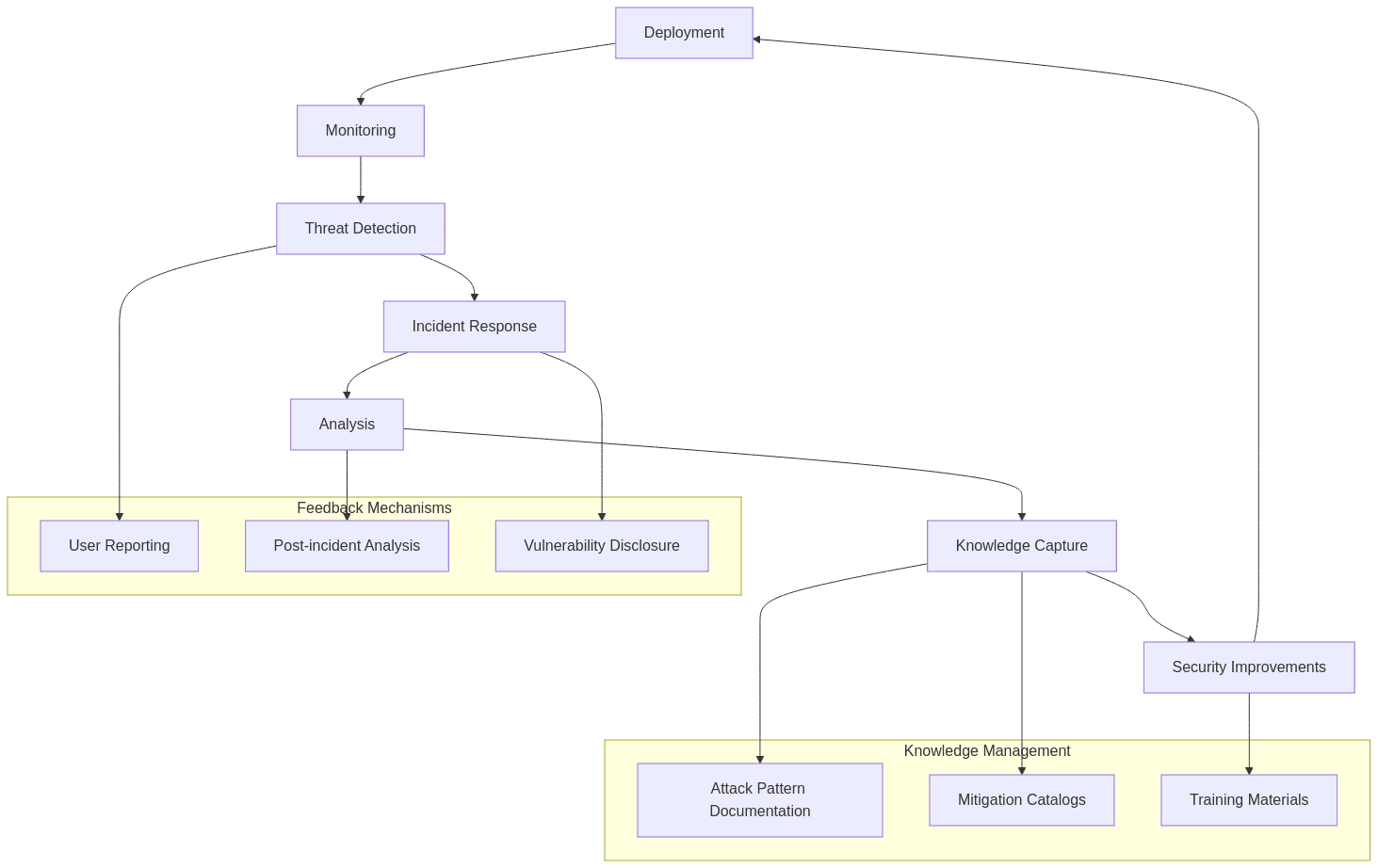
5.3.1 Feedback Mechanisms
- User reporting: Channels for flagging concerning outputs
- Post-incident analysis: Learning from security failures
- External vulnerability disclosure: Processes for responsible reporting
5.3.2 Knowledge Management
- Attack pattern documentation: Maintaining a library of known vulnerabilities
- Mitigation catalogs: Recording effective countermeasures
- Training materials: Educating stakeholders about security considerations
Conclusion: The Security Mindset for LLM Deployment
The security challenges facing LLMs aren’t merely technical problems—they represent a fundamental shift in how we must approach AI system design and deployment. Just as early web applications faced evolving security threats that eventually led to mature security practices, LLM security is following a similar trajectory from reactive fixes to proactive architecture.
Organizations successfully navigating these challenges share a common approach: they treat security not as a feature to be added, but as a fundamental design principle that shapes everything from data selection to deployment architecture. They recognize that in the domain of LLMs, security failures often manifest not as obvious crashes but as subtle behavioral changes that can be difficult to detect without specialized monitoring.
Tools like Llama Guard represent an important step forward, demonstrating that we can leverage the capabilities of LLMs themselves to enhance their security. Yet the most resilient approaches combine multiple defensive layers—from training-time safeguards to inference-time guardrails and post-processing validation.
As these models become further embedded in critical infrastructure and user-facing applications, the stakes for getting security right will only increase. The organizations that thrive will be those that build a security mindset into their AI development culture, continuously test their assumptions, and remain vigilant for the novel attack vectors that will inevitably emerge as these technologies evolve.
By embracing both the technical tools and organizational practices outlined in this article, you can harness the transformative potential of LLMs while maintaining the security posture necessary for responsible deployment.