Introduction
The AI narrative has been dominated by Large Language Models (LLMs), machines capable of generating startlingly human-like text and tackling problems once thought intractable. Yet, this power has largely resided behind the walled gardens of GPU-laden data centers, accessible primarily via APIs – a dependency that carries costs, privacy implications, and surrenders a measure of control. For developers and organizations wanting to wield this technology on their own terms, locally, the barrier seemed insurmountably high.
Then came Meta’s LLaMA (Large Language Model Meta AI) models – potent checkpoints offered in various sizes (7B to 65B parameters). Impressive, certainly, but still seemingly tethered to serious hardware. The game truly changed with the arrival of llama.cpp.
Forged by Georgi Gerganov and a rapidly growing legion of contributors, llama.cpp represents a pragmatic rebellion against the GPU oligarchy. It’s a C++ implementation laser-focused on wrestling LLM inference onto commodity CPUs. Suddenly, sophisticated language models were liberated from the cloud, capable of running on the laptops and desktops already sitting on our desks, no exorbitantly priced GPUs or recurring API fees required.
Marry this CPU efficiency with Cosmopolitan libc, and the picture becomes even more compelling. Cosmopolitan allows the creation of single-binary applications that shrug off operating system boundaries. This combination strikes at fundamental issues of privacy, offline utility, and the very feasibility of embedding potent AI directly into diverse applications, free from network tethers and vendor lock-in.
Understanding LLaMA Models
To grasp the significance of llama.cpp, one must first understand the substrate it operates on: the LLaMA family.
Meta dropped the initial LLaMA models in February 2023, sending ripples through the AI space. They weren’t just another set of weights; they offered:
- Efficiency: Performance punching far above their weight class, rivaling larger models with fewer parameters.
- Open Research Catalyst: Despite an initial non-commercial license, their existence fueled an explosion of research and fine-tuning within the open-source community.
- Scalability: Released in sizes from 7B to 65B parameters, offering a spectrum of capability versus computational cost.
The release of LLaMA 2 in July 2023 upped the ante, improving performance and, crucially, adopting a more permissive license allowing commercial use (albeit with caveats). This accelerated adoption, cementing LLaMA variants as a foundational layer for countless community-driven models fine-tuned for specific tasks like coding, instruction-following, or mimicking chatbot interactions. LLaMA became the bedrock upon which much of the open LLM ecosystem is now built.
What Is llama.cpp?
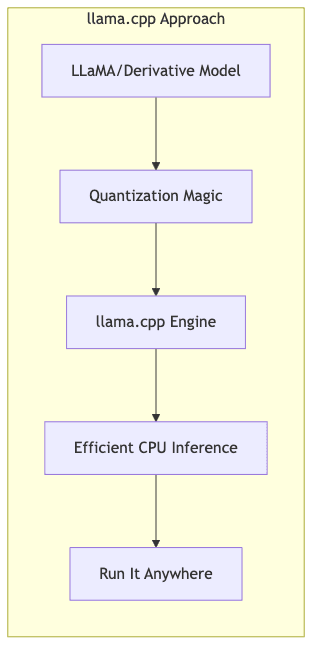
At its essence, llama.cpp is a lean, mean C/C++ engine built for one primary purpose: running LLaMA-architecture models efficiently on CPUs. Its potency stems from several key design choices:
1. Brutally Optimized CPU Inference
Forget the heavy frameworks primarily targeting GPUs. llama.cpp sweats the details of CPU performance using:
- SIMD Instructions: Harnessing AVX, AVX2, and AVX-512 extensions found on modern processors to chew through computations faster.
- Memory Frugality: Meticulous management of memory access patterns to maximize cache hits and minimize data shuffling.
- Multithreading: Effectively utilizing multi-core CPUs to parallelize the workload.
2. Aggressive Quantization
Perhaps the most critical innovation enabling llama.cpp’s feasibility on consumer hardware is its embrace of quantization:
- Sub-8-bit Precision: Techniques like 4-bit quantization dramatically shrink model footprints (up to 4x smaller than 16-bit).
- GGML/GGUF Formats: Custom tensor library and file formats designed for rapid loading and inference on quantized models.
- Mixed Precision: Intelligently using different numerical precisions for different model layers, balancing performance and accuracy.
Quantization isn’t magic; it’s a carefully engineered trade-off, sacrificing some numerical precision for massive gains in reduced memory usage and computational cost. This is what allows multi-billion parameter models to become tractable on hardware lacking dedicated tensor cores.
3. Minimal Dependencies
The project deliberately sidesteps the multi-gigabyte baggage of typical ML frameworks. This translates to:
- Lean Deployment: No complex Python environments or framework installations needed just to run inference.
- Build Simplicity: Easier compilation across diverse platforms.
- Lower Complexity: A more understandable and hackable codebase.
4. Community as the Engine
llama.cpp’s rapid evolution is a testament to its vibrant open-source community:
- Relentless Optimization: Continuous performance tweaks and refinement.
- Innovation Hub: A proving ground for new quantization schemes and inference strategies.
- Expanding Horizons: Growing support for models beyond the LLaMA family.
Benefits of CPU-Based LLM Inference
Why bother running these models locally on a CPU when cloud GPUs exist? The advantages are compelling:
1. Democratization and Accessibility
- Use What You Have: Runs on the hardware most developers and users already possess.
- GPU Independence: Sidesteps the cost, scarcity, and power demands of high-end GPUs.
- Lowering the Barrier: Enables students, hobbyists, and researchers with constrained budgets to engage with SOTA models.
2. Privacy, Security, and Compliance
- Data Sovereignty: Sensitive information stays local, never hitting third-party servers. Mandatory for many domains.
- Offline Capability: AI functionality remains available even without an internet connection.
- Regulatory Alignment: Simplifies compliance with data privacy regulations like GDPR, HIPAA, etc.
3. Deployment Autonomy
- Edge Computing: Enables powerful AI on devices operating at the network edge.
- Direct Integration: Embed LLM capabilities directly into applications without external API dependencies or network latency.
- Predictable Costs: Avoids variable, potentially escalating API usage fees.
4. Latency Control
- Eliminating Network Hops: No roundtrips to distant cloud servers.
- Consistent Performance: Less vulnerability to API provider throttling, outages, or changes in terms of service.
- Responsive Streaming: Tokens can be generated and processed immediately, crucial for interactive applications.
Cosmopolitan libc Integration
The fusion with Cosmopolitan libc elevates llama.cpp from a powerful inference engine to a radically distributable tool.
What is Cosmopolitan libc?
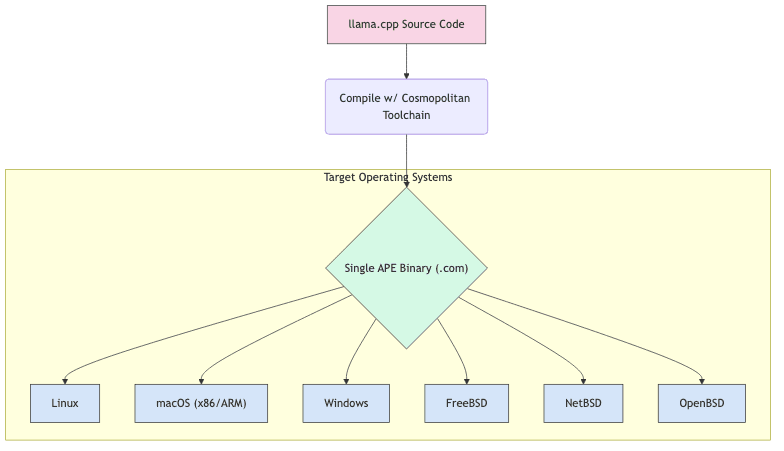
Created by Justine Tunney, Cosmopolitan libc (cosmocc) is a C library that enables the creation of Actually Portable Executables (APEs). It’s a fascinating piece of engineering that allows developers to:
- Build a single binary executable.
- Run that exact same file natively on Linux, macOS, Windows, FreeBSD, OpenBSD, and NetBSD.
- Avoid the nightmare of maintaining separate build toolchains and binaries for each platform.
Cosmopolitan achieves this through clever binary formatting and a runtime layer that abstracts away OS differences.
The Power of Combining llama.cpp with Cosmopolitan
Compiling llama.cpp with Cosmopolitan yields a potent combination:
- Universal Distribution: Package your LLM application as a single file that runs virtually anywhere.
- Deployment Simplified: Drastically reduces the complexity of distributing software across different operating systems.
- Frictionless Access: Makes it trivial for end-users, regardless of their OS, to run local LLM tools.
llama.cpp provides the capability to run LLMs locally; Cosmopolitan provides the reach to deliver that capability effortlessly.
Building llama.cpp with Cosmopolitan
Compiling llama.cpp with Cosmopolitan involves a specific toolchain setup. While the exact steps might evolve, the general process looks like this:
# 1. Clone the llama.cpp repository
git clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp
# 2. Fetch and set up the Cosmopolitan toolchain
# (Follow instructions on https://cosmo.zip/ or Cosmopolitan GitHub)
# Typically involves downloading cosmos.sh and running it
mkdir -p cosmocc
curl -s https://cosmo.zip/pub/cosmocc/cosmos.sh > cosmos.sh
chmod +x cosmos.sh
./cosmos.sh cosmocc # Installs toolchain into ./cosmocc
# 3. Configure the build environment to use cosmocc
export PATH="$PWD/cosmocc/bin:$PATH"
export CC=cosmocc
export CXX=cosmoc++
# Ensure we build a portable CPU-only binary, disabling GPU backends
export CFLAGS="-O3 -DGGML_USE_METAL=0 -DGGML_USE_CUBLAS=0 -DGGML_USE_VULKAN=0 -DGGML_USE_SYCL=0"
export LDFLAGS="-static" # Statically link for maximum portability
# 4. Use CMake to configure and build
mkdir build-cosmo
cd build-cosmo
# Explicitly disable GPU options for robustness
cmake .. -DCMAKE_BUILD_TYPE=Release -DLLAMA_METAL=OFF -DLLAMA_CUBLAS=OFF -DLLAMA_VULKAN=OFF -DLLAMA_SYCL=OFF -DLLAMA_NATIVE=OFF
# Compile using available cores
make -j$(nproc)
# 5. The resulting portable executable (e.g., main.com) is in build-cosmo/bin
# This single file should run across supported OSes.This process deliberately yields a CPU-only binary, sacrificing potential GPU speedup for maximum portability. The .com extension is characteristic of Cosmopolitan APEs.
Preparing and Running LLaMA Models
Using the compiled llama.cpp binary requires models in the correct format:
1. Obtaining Model Weights
Accessing base LLaMA weights often involves agreeing to Meta’s terms. However, the ecosystem thrives on fine-tuned variants (Alpaca, Vicuna, WizardLM, Mistral derivatives, etc.), many available on platforms like Hugging Face, often with more open licenses. Always check the specific license for any model you intend to use.
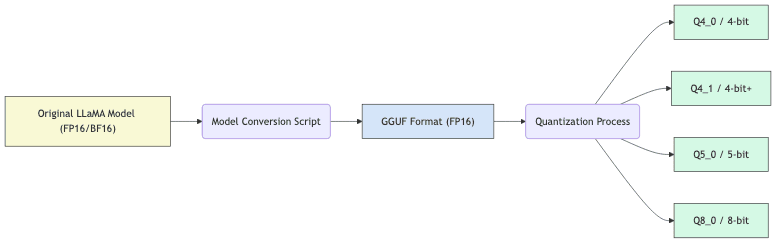
2. Converting and Quantizing Models
Models typically start in PyTorch or Safetensors format and need conversion to llama.cpp’s native GGUF format. Quantization follows conversion:
# Example: Convert a Hugging Face model to GGUF FP16
python convert.py /path/to/hf/model/ --outfile models/my-model/gguf-f16.bin --outtype f16
# Example: Quantize the FP16 model to Q4_0 (4-bit)
./quantize models/my-model/gguf-f16.bin models/my-model/gguf-q4_0.bin q4_0Quantization is where the magic happens, shrinking models dramatically while striving to retain performance:
| Parameter Size | Typical FP16 Size | Typical 4-bit (Q4_0) Size | RAM Needed (Approx) |
|---|---|---|---|
| 7B | ~13 GB | ~3.8 GB | 5-6 GB |
| 13B | ~24 GB | ~7.3 GB | 9-10 GB |
| 70B | ~130 GB | ~38 GB | 40-48 GB |
(Note: Actual file sizes and RAM usage vary based on model architecture and specific quantization method)
3. Running Inference
Executing inference with the compiled binary is straightforward:
# Simple prompt completion
./main -m models/my-model/gguf-q4_0.bin -n 256 -p "Explain quantum entanglement like I'm five:"
# Interactive mode using a chat prompt format
./main -m models/my-model-chat/gguf-q4_0.bin --color -i -r "User:" --in-prefix " " -f prompts/chat-with-assistant.txt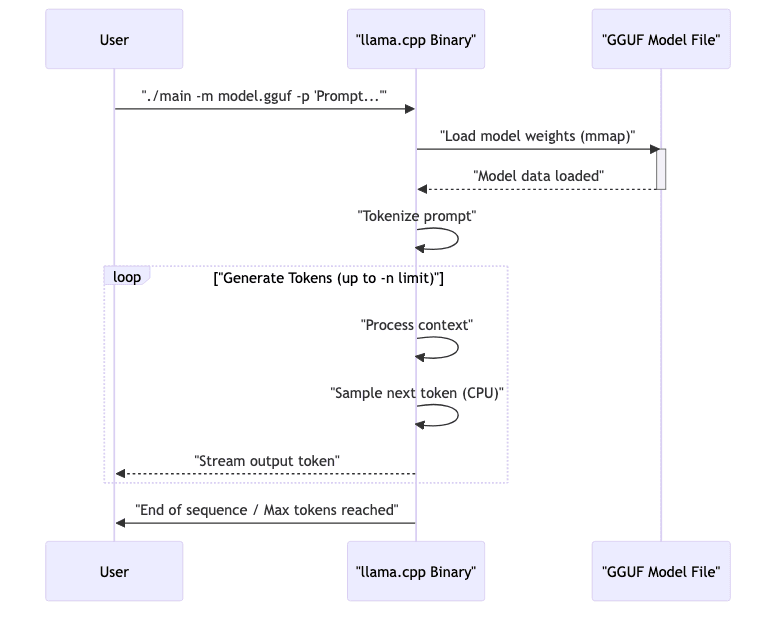
Key command-line parameters often include:
-m <path>: Path to the GGUF model file.-n <int>: Max number of tokens to generate.-p <text>: The initial prompt.-t <int>: Number of CPU threads (usually physical cores).--temp <float>: Sampling temperature (controls randomness; ~0.7 is common).--ctx_size <int>: Context window size (max tokens the model considers).-i: Interactive mode.
Performance Considerations
Local CPU inference is a game of trade-offs. Performance hinges critically on hardware:
Hardware Reality Check
This is a rough guide; actual performance varies wildly:
| Model Size (Quantized) | Min RAM Needed | Recommended CPU Cores | Typical Tokens/Second |
|---|---|---|---|
| 7B (Q4_0) | ~5 GB | 4+ Modern Cores | 8-40+ |
| 13B (Q4_0) | ~10 GB | 8+ Modern Cores | 4-20+ |
| 33B (Q4_0) | ~20 GB | 16+ Modern Cores | 2-10+ |
| 70B (Q4_0) | ~40 GB | High Core Count CPU | 1-5+ |
Factors influencing speed: CPU architecture (AVX support), memory bandwidth, quantization level, context size, batch size.
Tuning for Speed
Extracting maximum performance involves tweaking parameters:
- Thread Count (
-t): Match physical CPU cores, not logical threads. - Context Size (
--ctx_size): Smaller contexts use less RAM and can be faster, but limit memory. - Batch Processing (
-b): Can improve throughput on beefy CPUs if processing multiple prompts. - Memory Mapping (
--mmap/--no-mmap):mmapoften speeds up loading; sometimes disabling it helps runtime. - Quantization Choice: Experiment with different
Qlevels (Q4_K_M, Q5_K_M, etc.) – higher quality usually means slightly slower.
Performance Trajectory
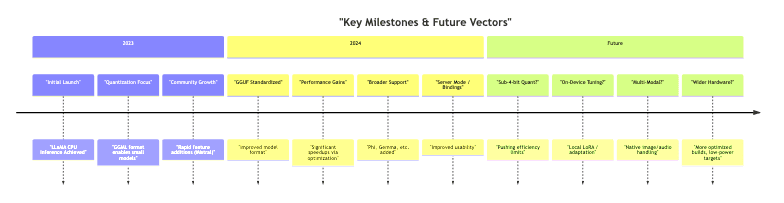
The speed of llama.cpp isn’t static. Optimization is relentless:
- Early 2023: Initial versions offered maybe ~10 tokens/sec on good hardware.
- Late 2023: Significant gains pushed this to 20-30+ tokens/sec.
- 2024 Onward: Advanced quantization (like K-quants), better GGUF handling, and architecture-specific tuning continue to improve speeds, sometimes exceeding 50 tokens/sec on consumer gear for smaller models.
Recent Advancements
The llama.cpp project and its ecosystem are constantly in flux:
Broader Model Support
It’s no longer just for LLaMA. Support includes major architectures like:
- Mistral/Mixtral: Including the popular 7B model and Mixture-of-Experts variants.
- Phi: Microsoft’s smaller, capable models.
- Qwen: Models from Alibaba.
- Gemma: Google’s open models.
- An ever-growing list of community fine-tunes and novel architectures.
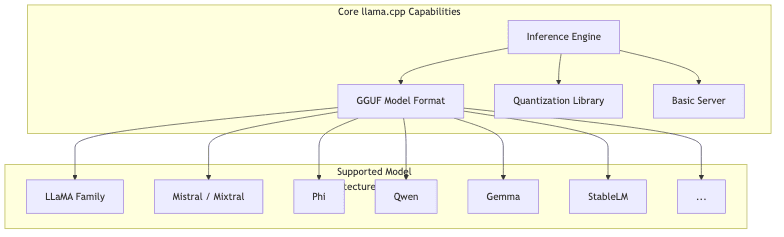
Quantization Frontiers
The art of shrinking models while preserving quality advances rapidly:
- GGUF Format: The standard, offering flexibility and metadata support, replacing older GGML.
- K-Quants: Sophisticated methods aiming for better quality preservation at low bitrates.
- Ongoing Research: Exploration of <4-bit quantization and new techniques.
Usability Enhancements
Beyond the core CLI tool:
- Server Mode: Built-in HTTP server providing OpenAI-compatible API endpoints.
- Python Bindings: Official
llama-cpp-pythonlibrary for easy integration. - Community UIs: Numerous web interfaces built on top of the server or bindings.
Optional GPU Offloading
While CPU-first, llama.cpp can leverage GPUs if available and desired:
- CUDA: For NVIDIA GPUs.
- Metal: For Apple Silicon (and AMD on macOS).
- OpenCL / Vulkan: Broader, sometimes experimental, GPU support. (Note: Using GPU offloading breaks Cosmopolitan’s universal portability goal)
Practical Applications
The ability to run LLMs locally unlocks use cases infeasible or undesirable with cloud APIs:
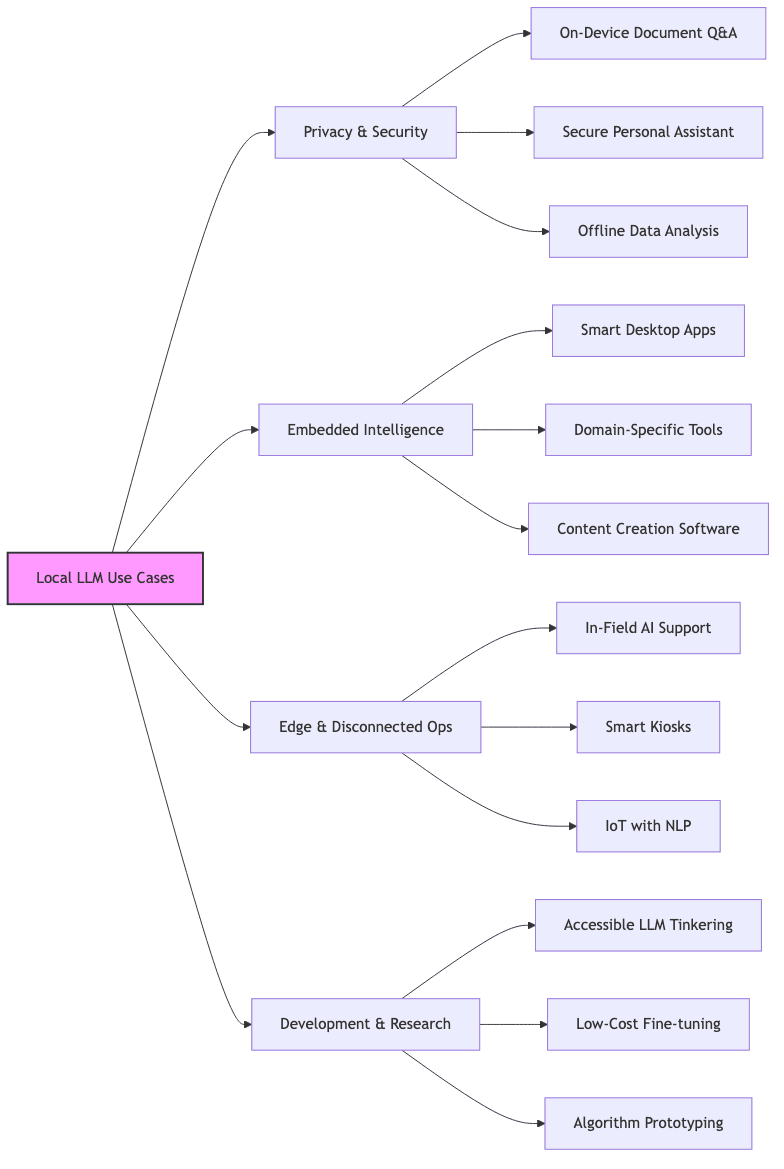
Privacy-Critical Solutions
- Local Document Interaction: Analyze sensitive contracts, medical records, or proprietary code without data leakage.
- Offline Knowledge Systems: Build searchable, interactive documentation or personal knowledge managers.
- Confidential Assistants: Enterprise or personal bots that guarantee data never leaves the device.
Embedded AI Functionality
- Smarter Desktop Software: Integrate context-aware help, summarization, or generation into existing apps.
- Niche Expert Tools: Create specialized assistants trained on specific professional knowledge bases.
- Offline Creative Aids: Writing assistants, code completers, or brainstorming tools that work anywhere.
Edge and Offline Deployments
- Remote Field Work: Provide diagnostic help or information retrieval in areas without reliable internet.
- Interactive Kiosks: Power information booths or control systems without cloud dependency.
- Intelligent IoT: Add sophisticated language understanding to edge devices.
Education, Research, and Tinkering
- Accessible Experimentation: Lowers the barrier for students and researchers to study LLM behavior.
- Custom Model Development: Facilitates local fine-tuning and experimentation with techniques like LoRA.
- Understanding Inference: Provides a relatively simple codebase to study LLM mechanics.
Integration Examples
Integrating llama.cpp often involves using its server mode or Python bindings:
Using Python Bindings (llama-cpp-python)
# Assumes llama-cpp-python is installed (pip install llama-cpp-python)
from llama_cpp import Llama
# Point to your GGUF model file
model_path = "models/mistral-7b-instruct-v0.2.Q4_K_M.gguf"
# Initialize (using CPU only for portability focus)
llm = Llama(
model_path=model_path,
n_ctx=4096, # Context size
n_threads=8, # Adjust to your core count
n_gpu_layers=0 # Explicitly CPU only
)
# Example prompt using Mistral Instruct format
prompt = "[INST] What are the main benefits of using llama.cpp? [/INST]"
# Generate
output = llm(
prompt,
max_tokens=256,
temperature=0.7,
stop=["</s>", "[INST]"] # Stop sequences
)
# Access the generated text
response_text = output["choices"][0]["text"]
print(response_text.strip())Interacting with Server Mode (JavaScript Example)
// Assuming llama.cpp is running in server mode (e.g., ./server -m model.gguf)
async function queryLlamaServer(promptText) {
try {
const response = await fetch('http://127.0.0.1:8080/completion', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({
prompt: promptText,
n_predict: 256, // Max tokens to generate
temperature: 0.7,
stop: ["</s>", "\nUser:"] // Stop generation triggers
})
});
if (!response.ok) {
throw new Error(`HTTP error! status: ${response.status}`);
}
const data = await response.json();
return data.content; // The generated text
} catch (error) {
console.error("Error querying llama.cpp server:", error);
return "Error contacting server.";
}
}
// How you might use it
const userPrompt = "[INST] Summarize the concept of quantization in LLMs. [/INST]";
queryLlamaServer(userPrompt).then(response => {
console.log("AI Response:", response);
// Update your application UI here
});Future Directions
The trajectory points towards even greater capability and efficiency:
- Relentless Optimization: Squeezing more performance out of existing hardware through algorithmic improvements and better low-level code.
- Architecture-Specific Tuning: Exploiting unique features of different CPU families (e.g., specific AVX versions, ARM NEON).
- New Model Adaptations: Quickly integrating support for novel, efficient model architectures as they appear.
- On-Device Fine-Tuning: Making it practical to adapt models locally with techniques like LoRA.
- Multi-Modal Expansion: Extending beyond text to natively handle image, audio, or other data types within the same framework.
- Ultra-Low Resource Targets: Pushing feasibility onto even more constrained devices like microcontrollers (for smaller models).
Conclusion
llama.cpp, especially when paired with the reach of Cosmopolitan libc represents a fundamental shift in AI accessibility. It wrenches powerful language models from the exclusive domain of cloud providers and places them directly into the hands of developers and users, runnable on the hardware they already own.
This combination unlocks possibilities previously constrained by cost, connectivity, or privacy concerns. It enables a future where sophisticated AI is more than a service you rent, but a capability you can own, embed, and deploy autonomously. For anyone building applications that require local data processing, offline functionality, or simply freedom from API dependencies, the llama.cpp ecosystem offers a compelling, pragmatic, and increasingly powerful foundation.
The relentless pace of optimization and model adaptation suggests that local inference will only become more viable. llama.cpp stands as a crucial bridge, translating cutting-edge research into practical tools that democratize access to the engines driving the next wave of intelligent applications. It’s a reminder that sometimes, the most impactful innovations are more than about building bigger models. But about making existing power radically more accessible.