Introduction: The Challenge of Fine-Tuning Large Models
Fine-tuning Large Language Models (LLMs) has been a brute-force affair demanding obscene amounts of GPU memory. Models bloating into the billions of parameters routinely required hundreds of gigabytes of VRAM, locking them away in high-end hardware clusters accessible only to the heavily capitalized. This hardware blockade has actively throttled innovation and kept LLM tech concentrated in few hands.
Enter QLoRA (Quantized Low-Rank Adaptation). Emerging in 2023, this technique isn’t a single magic bullet but a clever combination of optimization strategies designed to slash the hardware tax for fine-tuning. QLoRA makes the seemingly absurd feasible: fine-tuning models with tens, even hundreds, of billions of parameters on consumer-grade GPUs packing relatively modest VRAM (think single cards with 24GB or less).
In this piece, we’ll dissect:
- The core components enabling QLoRA’s efficiency
- How these pieces interlock to crush memory requirements
- Practical notes on implementation
- The real-world performance implications – what you gain, what you might trade off
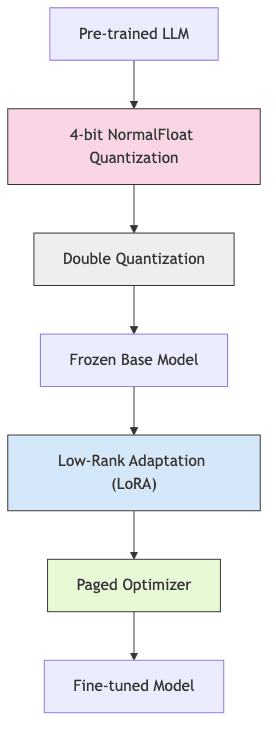
The Building Blocks of QLoRA
QLoRA achieves its remarkable efficiency not through one trick, but by layering four distinct technical components:
- 4-bit NormalFloat quantization: Aggressively shrinking weight precision from the standard 16/32-bit down to a mere 4 bits.
- Double quantization: Applying compression even to the quantization constants themselves, squeezing out more efficiency.
- Low-Rank Adaptation (LoRA): Sidestepping full parameter updates by leveraging low-rank decomposition for targeted changes.
- Paged optimizers: Implementing a virtual memory strategy for optimizer states, shifting the burden between GPU and CPU.
Let’s unpack each layer.
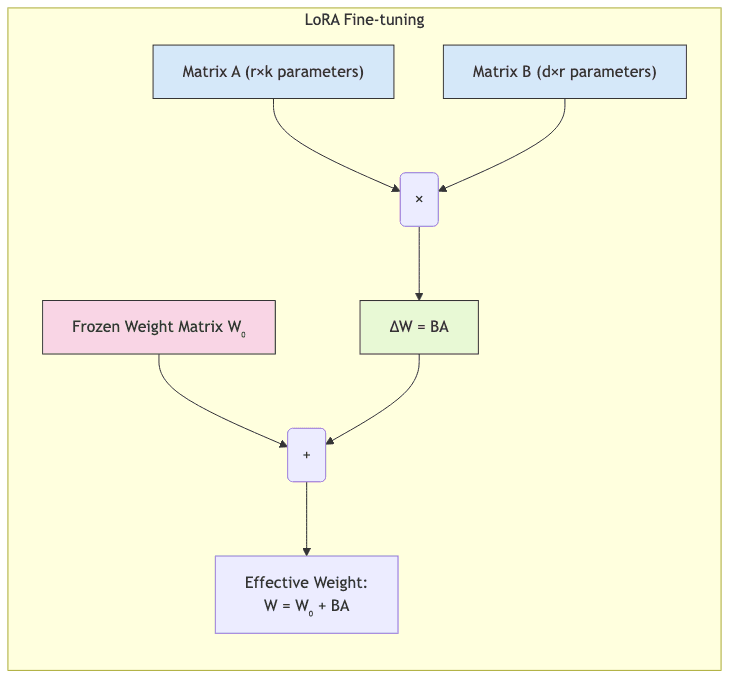
Low-Rank Adaptation (LoRA): The Foundation
LoRA serves as the foundation for QLoRA’s parameter efficiency. It operates on a crucial insight: the weight adjustments needed during fine-tuning often inhabit a much lower-dimensional space than the full parameter matrix suggests. The deltas aren’t sprawling changes across the entire model; they’re concentrated.
How LoRA Works
Instead of modifying the entire pre-trained weight matrix , LoRA keeps
frozen and introduces two smaller, trainable matrices,
and
, to represent the change
:
Where:
is the untouched, pre-trained weight matrix (massive).
is a matrix of size
.
is a matrix of size
.
is the “rank” of the update – the dimensionality of the subspace we’re working in (typically small, like 8-64, dwarfed by
and
).
The upshot? Instead of wrestling with all parameters in
, we only train the (r \times (d + k)) parameters in
and
. When
is small, the reduction in trainable parameters is immense.
LoRA Benefits
- Memory thrift: Slashes the number of trainable parameters, often by over 99%.
- Training velocity: Fewer parameters translate directly to less computation during backpropagation.
- Modularity: Different LoRA adapters (trained
LoRA alone is a significant step, but wrestling truly enormous models (70B+) onto consumer GPUs still requires more aggressive measures. This is where quantization comes into play.
4-Bit NormalFloat: Precision That Matters
Standard deep learning often settles for half-precision (FP16) or BFloat16. QLoRA takes a more radical approach, employing the 4-bit NormalFloat (NF4) quantization scheme, primarily via the bitsandbytes library.
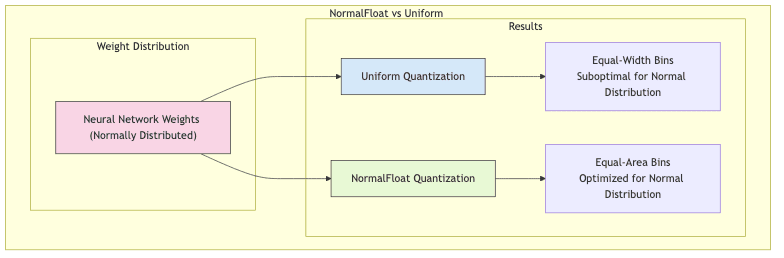
What Makes NormalFloat Special
- Distribution-Aware: Standard uniform quantization treats all value ranges equally. NormalFloat is smarter; it acknowledges that neural network weights aren’t uniformly distributed but typically follow a bell curve (normal distribution). It optimizes quantization levels for this specific distribution.
- Equal-Area Binning: Instead of equal-width bins, NF4 aims for bins that capture roughly the same number of weights under a normal distribution. This means more precision is allocated where most weights actually reside (near zero).
- Better Outlier Handling: By focusing precision on the dense central region, NF4 inherently handles the tails of the distribution more effectively than uniform methods.
A stark comparison:
| Precision | Bits | Memory Usage (Relative) | Accuracy Impact |
|---|---|---|---|
| FP16 | 16 | 100% | Baseline |
| INT8 | 8 | 50% | Often minor |
| NF4 | 4 | 25% | Manageable |
Crucially, empirical results show that for LLMs, NF4 quantization maintains model performance surprisingly well, despite the drastic compression. The information loss is tolerable.
Double Quantization: Compressing the Compression
Quantizing a model involves storing not just the 4-bit weights but also the parameters needed to de-quantize them – scale factors and zero-points, typically stored in higher precision (like FP16). For enormous models, these quantization metadata parameters themselves start consuming non-trivial memory.
Double quantization addresses this by applying a second, less aggressive round of quantization specifically to these metadata parameters:
- Primary Quantization: Convert the main model weights from FP16/32 down to 4-bit NF4.
- Secondary Quantization: Quantize the resulting FP16 scaling factors (and potentially zero-points) down to 8-bit.

This second pass typically shaves off an additional ~0.4 bits per parameter. Doesn’t sound like much, but across billions of parameters, it adds up.
Consider a 70B parameter model:
- Single quantization (4-bit weights, FP16 metadata): Might require ~35GB.
- Double quantization (4-bit weights, 8-bit metadata): Might drop to ~33GB.
That 2GB saving might seem marginal, but it can be the difference between fitting onto a specific GPU tier or being forced onto more expensive hardware. It’s about maximizing utility at the edge of feasibility.
The Paged Optimizer: Virtual Memory for Training
Quantized weights and LoRA drastically cut down the memory needed for the model parameters themselves. However, the optimizer state remains a major memory hog during training. Optimizers like Adam maintain momentum and variance estimates for each trainable parameter, potentially doubling or tripling the memory footprint associated with those parameters.
The paged optimizer tackles this using a concept borrowed directly from operating system virtual memory management:
- CPU Holds the Bulk: Most optimizer state variables reside in standard CPU RAM.
- GPU Gets What’s Needed: Only the optimizer states relevant to the current batch of parameters being updated are transferred (“paged in”) to the GPU VRAM.
- Intelligent Swapping: Uses batching and prefetching to minimize the latency impact of CPU-GPU transfers, moving data just before it’s needed.

This allows training processes where the total optimizer state size is far larger than the available GPU memory, effectively using CPU RAM as slower, cheaper overflow storage.
Putting It All Together: The QLoRA Advantage
When these four techniques converge, the memory savings compound dramatically:
- Base Model Compression: 4-bit NormalFloat + Double Quantization cuts base model memory to ~25% of FP16.
- Trainable Parameter Reduction: LoRA ensures only a tiny fraction (<1%) of parameters need gradients and optimizer states.
- Optimizer State Management: Paged optimization prevents the remaining optimizer states from overwhelming GPU memory.
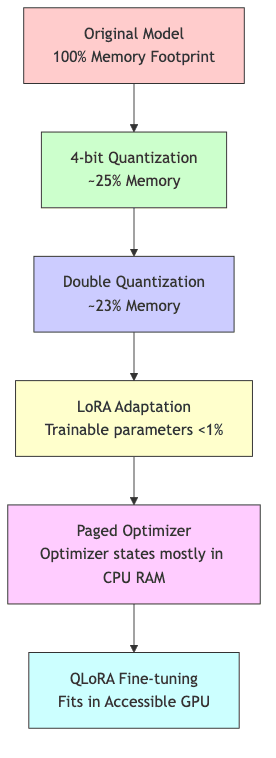
The outcome is stark: models previously demanding hundreds of gigabytes for fine-tuning become tractable on a single, high-end consumer or prosumer GPU.
Illustrative Memory Requirements (Approximate):
| Model Size | Traditional FP16 Fine-tuning | LoRA Only (FP16 Base) | QLoRA (4-bit Base) |
|---|---|---|---|
| 7B | ~28GB+ | ~14GB+ | ~5GB+ |
| 13B | ~52GB+ | ~26GB+ | ~9GB+ |
| 33B | ~132GB+ | ~66GB+ | ~24GB+ |
| 70B | ~280GB+ | ~140GB+ | ~48GB+ |
(Note: ‘+’ indicates additional memory needed for activations, varies with batch size and sequence length.)
With QLoRA, a 70B model potentially becomes fine-tunable on a single A100 (80GB), while models like Llama-2 7B or 13B are well within reach of GPUs like the RTX 3090/4090 (24GB).
QLoRA in Practice: Implementation Workflow
Here’s a sketch of the typical workflow using popular libraries like Hugging Face transformers, peft, and bitsandbytes.
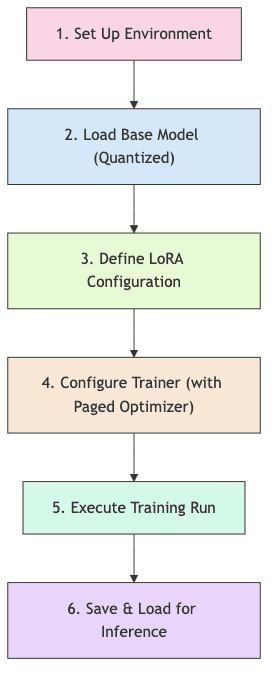
1. Prepare Your Environment
Install the usual suspects:
pip install transformers accelerate bitsandbytes peft trl2. Load the Quantized Base Model
This is where bitsandbytes configures the 4-bit loading.
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
import torch
# Configure 4-bit quantization with NF4 and double quantization
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16, # Or bfloat16 if supported/needed
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4" # Use NormalFloat4
)
# Specify the base model
model_id = "meta-llama/Llama-2-7b-hf" # Example
tokenizer = AutoTokenizer.from_pretrained(model_id)
# Load the model, applying quantization config
model = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config=quantization_config,
device_map="auto" # Distribute model layers across available GPUs if needed
)3. Configure LoRA Adaptation
Use peft to specify which layers get LoRA adapters and the rank.
from peft import LoraConfig, get_peft_model
# Define LoRA settings
lora_config = LoraConfig(
r=16, # Rank - higher means more capacity, more memory
lora_alpha=32, # Scaling factor (often 2*r)
lora_dropout=0.05, # Dropout for regularization
bias="none", # Usually 'none' for LoRA
task_type="CAUSAL_LM", # Specify task type
target_modules=[ # Apply LoRA to these modules (model-specific)
"q_proj", "k_proj", "v_proj", "o_proj", # Common for attention layers
"gate_proj", "up_proj", "down_proj" # Common for MLP layers
]
)
# Wrap the base model with LoRA adapters
model = get_peft_model(model, lora_config)
model.print_trainable_parameters() # Useful check4. Configure Training with Paged Optimizer
Specify the paged optimizer in TrainingArguments.
import bitsandbytes as bnb
from transformers import TrainingArguments
# Note: The optimizer itself can be 8-bit for further memory saving
# The TrainingArguments will handle instantiation
training_args = TrainingArguments(
output_dir="./qlora-finetune-output",
per_device_train_batch_size=4, # Keep low due to activation memory
gradient_accumulation_steps=4, # Accumulate gradients for larger effective batch size
learning_rate=2e-4, # Typical LR for LoRA
num_train_epochs=3, # Example epochs
save_strategy="epoch", # Save adapter checkpoints
logging_steps=10,
optim="paged_adamw_8bit", # Crucial: specify the paged optimizer
fp16=True, # Or bf16=True, for mixed-precision training
)(Note: Explicit optimizer instantiation like bnb.optim.PagedAdamW8bit is often handled internally by Trainer when optim="paged_adamw_8bit" is set).
5. Train and Save the Model
Use the Hugging Face transformers0.
from transformers import Trainer, DataCollatorForLanguageModeling
# Assume train_dataset is loaded (e.g., from datasets library)
# Assume data_collator is defined (e.g., DataCollatorForLanguageModeling)
trainer = Trainer(
model=model, # The PEFT model
args=training_args,
train_dataset=train_dataset, # Your training data
tokenizer=tokenizer,
data_collator=data_collator, # Appropriate data collator
)
# Start fine-tuning
trainer.train()
# Save only the trained LoRA adapter weights, not the whole base model
model.save_pretrained("./my-qlora-adapter")
tokenizer.save_pretrained("./my-qlora-adapter") # Save tokenizer too6. Inference with the Fine-tuned Model
Load the quantized base model again, then merge the trained LoRA adapter weights.
from peft import PeftModel
# Reload the base model (can be quantized for efficient inference)
base_model_config = BitsAndBytesConfig(load_in_4bit=True, bnb_4bit_compute_dtype=torch.float16) # Example config
base_model = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config=base_model_config,
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("./my-qlora-adapter") # Load tokenizer from saved adapter dir
# Load the LoRA adapter onto the base model
fine_tuned_model = PeftModel.from_pretrained(
base_model,
"./my-qlora-adapter" # Path to saved adapter
)
fine_tuned_model.eval() # Set to evaluation mode
# Example generation
prompt = "Machine learning is transforming industries by"
inputs = tokenizer(prompt, return_tensors="pt").to(fine_tuned_model.device)
with torch.no_grad():
outputs = fine_tuned_model.generate(
**inputs,
max_new_tokens=50,
temperature=0.7,
do_sample=True
)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))Key Considerations and Best Practices
1. Quantization Precision Trade-offs
- NF4 is the Go-To: Generally the best balance of memory saving and performance for LLMs.
- FP4 as Fallback: If NF4 causes instability (rare), standard 4-bit float (FP4) is an option, potentially with slightly lower quality.
- Compute
transformers1: Matchtransformers2 (e.g.,transformers3 ortransformers4) to your desired mixed-precision training format. This is the precision used for calculations after de-quantization during the forward/backward pass.
2. LoRA Configuration Tuning
This is where the art meets the science.
- Rank (
transformers5): Controls capacity. Start small (8-16), increase (32, 64) if performance plateaus but memory allows. Higher rank = more trainable parameters = more memory. - Alpha (
transformers6): Scaling factor. Common heuristic:transformers7. Adjusting can sometimes help stabilize training. - Target Modules: Which layers get adapted?
- Minimal: Just attention query (
transformers8) and value (transformers9). Memory-light, might be enough for simple adaptations. - Standard: All attention linear layers (
peft0,peft1,peft2,peft3). Good baseline. - Comprehensive: Attention + MLP layers (
peft4,peft5,peft6). More capacity, more memory, often better performance. Check model architecture for exact module names.
- Minimal: Just attention query (
![]()
3. Batch Size and Gradient Accumulation
- Activations during the forward pass still consume significant memory, often becoming the bottleneck even with QLoRA.
- Start with
peft7. - Use
peft8 to achieve a larger effective batch size without increasing peak memory. Effective batch size =peft9. - Increment
bitsandbytes0 cautiously while monitoring VRAM usage (bitsandbytes1).
4. Hardware Reality Check
Minimum VRAM estimates for QLoRA fine-tuning (can vary):
| Model Size | Min VRAM (Approx) | Example GPU(s) |
|---|---|---|
| 7B | 8GB | RTX 3060 (12GB), RTX 4060 Ti (16GB) |
| 13B | 12GB | RTX 3090/4090 (24GB), A10 (24GB) |
| 33B | 24GB | RTX 4090 (24GB), A100 (40GB/80GB) |
| 70B | 40GB+ | A100 (40GB/80GB), H100 |
5. Troubleshooting Common Pitfalls
- CUDA Out of Memory (OOM): The classic. Reduce
bitsandbytes2, reduce LoRAbitsandbytes3, target fewer modules (e.g., only attention), increasebitsandbytes4. - Training Instability (NaN losses): Lower the learning rate. Ensure
bitsandbytes5 is appropriate (trybitsandbytes6 if on Ampere+ GPUs). Increase training warmup steps. Check data quality. - Subpar Performance: Train longer. Increase LoRA
bitsandbytes7. Target more modules. Improve data quality/quantity. Experiment with hyperparameters (LR, scheduler).
Real-World Performance and Results
Does this aggressive optimization sacrifice performance? The evidence suggests surprisingly little. The original QLoRA paper, along with subsequent studies, consistently shows that models fine-tuned using QLoRA perform remarkably close to their fully fine-tuned counterparts across a range of NLP benchmarks.
- Standard Benchmarks (GLUE, SuperGLUE etc.): Performance often within 1-2 percentage points of full FP16 fine-tuning.
- Instruction Following & Chat: QLoRA has proven particularly adept at tuning models like Llama into capable instruction-followers (e.g., Guanaco, Alpaca variants).
- Domain Adaptation: Effective for specializing foundation models on specific datasets (medical, legal, financial).
The key finding from the QLoRA paper was demonstrating a 65B parameter model fine-tuned on a single 80GB A100 GPU matching the performance of the same model fine-tuned traditionally, which demanded significantly more hardware (around 8x A100s). It’s a step-change in accessibility.
The Future of Efficient Fine-Tuning
QLoRA is a powerful demonstration of optimizing within constraints, but the field isn’t standing still. Expect further evolution:
- Speed Optimizations: Projects like
bitsandbytes8 build on QLoRA, optimizing CUDA kernels to achieve significant (2-5x) speedups during training. - Beyond 4-bit: Research into 3-bit, 2-bit, or even 1-bit quantization continues, pushing the boundaries of compression, though often with more noticeable performance trade-offs.
- Efficient Inference: Techniques like GPTQ, AWQ, GGUF complement QLoRA by enabling efficient deployment of these quantized and adapted models.
- Mixture-of-Experts (MoE): Applying parameter-efficient techniques to sparse MoE models is crucial for making trillion-parameter behemoths adaptable.
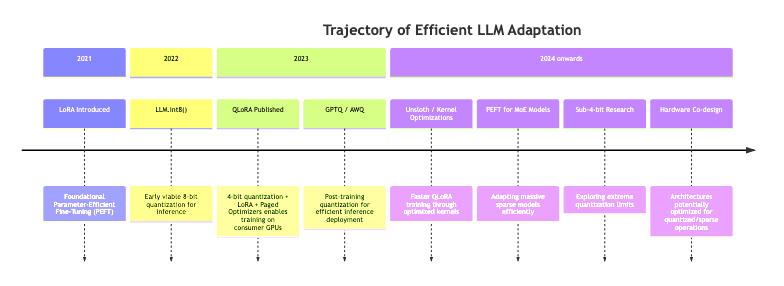
The trend is clear: making powerful AI models not just bigger, but smarter in their resource utilization.
Conclusion
QLoRA stands as a prime example of smart engineering triumphing over brute-force hardware scaling. By ingeniously combining 4-bit NormalFloat quantization, double quantization, the parameter efficiency of LoRA, and the virtual memory tactics of paged optimizers, it dismantles a major hardware barrier. Memory requirements plummet, making the adaptation of state-of-the-art LLMs feasible beyond the confines of elite labs and hyperscalers.
This more than just about saving money on GPUs; it’s about democratizing capability. Researchers with limited budgets, startups crafting niche AI solutions, even individuals experimenting on home machines can now engage with and customize models that were previously out of reach.
QLoRA, and the techniques it embodies, signals a necessary shift in AI development – emphasizing resourcefulness and optimization alongside the relentless pursuit of scale. As models inevitably continue to grow, innovations that allow us to do more with less will be fundamental to widespread progress and adoption.
Further Reading & References
- QLoRA: Efficient Finetuning of Quantized LLMs – The original paper. Essential reading.
- LoRA: Low-Rank Adaptation of Large Language Models – The foundational paper for LoRA.
bitsandbytes9 Repository – The library enabling NF4, double quantization, and paged optimizers.- Hugging Face
bitsandbytes0 Library – Implements LoRA, QLoRA integration, and other PEFT methods. - HuggingFace Blog: Making LLMs even more accessible with bitsandbytes, 4-bit quantization and QLoRA – A practical overview.
- LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale – Foundational work on quantization effects in LLMs.