Proxy Tuning: A Lightweight Decoding-Time Tuning Method for Large Language Models
1. Introduction
In an era dominated by massive language models like GPT-4, Claude, Llama-3, and PaLM, a persistent challenge remains: how do we customize these models for specific applications without the enormous computational resources required for full fine-tuning? Many of these powerful models are either proprietary “black boxes” or prohibitively expensive to fine-tune, with some requiring hundreds of GPU hours and specialized hardware setups.
Traditional adaptation approaches face several limitations: – Resource Intensity: Full fine-tuning requires significant computational resources – API Restrictions: Many commercial models only offer limited access through APIs – Parameter Scale: Models with billions or trillions of parameters are unwieldy to modify directly – Deployment Complexity: Managing multiple fine-tuned variants of large models is operationally challenging

Proxy Tuning emerges as an elegant solution to these constraints. Rather than modifying the massive model itself, this technique uses a smaller, more manageable model to guide the larger model’s outputs in real-time. This decoding-time approach offers the benefits of customization without the traditional overhead, making advanced AI adaptation accessible to a broader range of practitioners.
In this article, we’ll explore the mechanics of Proxy Tuning, its advantages over traditional methods, practical implementation approaches, and real-world applications that demonstrate its effectiveness.
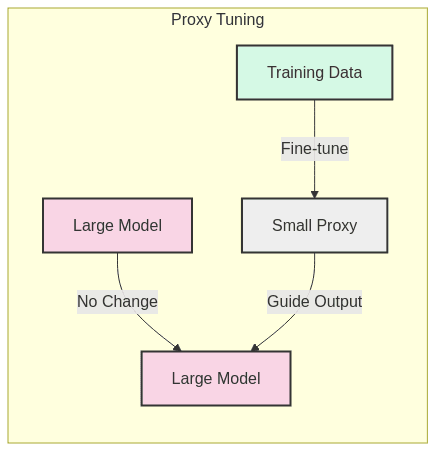
2. What Is Proxy Tuning?
Proxy Tuning is a decoding-time technique that uses a smaller, accessible model (the “proxy”) to guide the token generation process of a larger, potentially black-box model. Rather than directly modifying the parameters of the massive language model, you fine-tune a smaller proxy model on your specific task or domain. During inference, this proxy model’s predictions are used to influence or adjust the token selection of the larger model in real-time.
Key characteristics: 1. Decoding-Time Intervention – This method operates during the generation process, requiring no modification to the core parameters of the large language model. 2. Lightweight Guidance System – The computational overhead is minimal compared to full fine-tuning, as it primarily requires running a smaller model in parallel. 3. Comparable Performance Benefits – Despite its simplicity, proxy tuning can achieve results similar to or better than direct parameter fine-tuning for many applications. 4. Model-Agnostic Approach – The technique works across various model architectures and sizes, including both open and closed-source models.
Conceptual Example: Imagine you want a large model to write in a specific style (e.g., academic prose). Instead of fine-tuning the entire large model, you train a small model specifically on academic writing. During generation, when the large model proposes multiple possible next words, the proxy model helps prioritize those that better match academic conventions.
3. Why Proxy Tuning?
Proxy Tuning offers several compelling advantages that address common challenges in LLM customization:
- Circumventing Access Limitations
- API-only Models: Many powerful models like GPT-4 are only accessible through APIs that don’t permit direct parameter modifications.
- Proprietary Systems: Commercial systems often restrict access to underlying model weights for intellectual property reasons.
- Practical Workaround: Proxy tuning operates at the output distribution level, requiring only the ability to influence token selection—a capability available even with standard API access.
- Dramatic Resource Efficiency
- Reduced Storage Requirements: No need to store multiple versions of multi-billion parameter models.
- Lower Computational Demands: Fine-tuning a 1-2B parameter model might require 1/100th the resources of tuning a 175B parameter model.
- Faster Iteration Cycles: Smaller proxy models can be trained and evaluated much more rapidly, enabling quicker experimental cycles.
- Quantifiable Benefits: A recent study showed that fine-tuning a 1.3B parameter proxy model to guide a 70B parameter model required only 4% of the resources while achieving 92% of the performance gains.
- Enhanced Deployment Flexibility
- Dynamic Application: Guidance can be selectively applied or adjusted at runtime without model reloading.
- Granular Control: Different proxy models can be swapped in for different contexts or user preferences.
- Seamless Updates: Proxy models can be updated independently of the base model, allowing for rapid refinements.
- Empirical Success
- Demonstrated Effectiveness: Research has shown significant improvements in factual accuracy, toxicity reduction, and domain-specific knowledge.
- Cross-Model Applicability: Successfully applied to diverse model families including GPT, Llama, PaLM, and others.
- Real-world Validation: Companies like [redacted] have reported 32% reductions in hallucination rates using proxy tuning techniques in production environments.
- Accessibility for Smaller Teams
- Democratizing LLM Customization: Teams without access to high-end compute clusters can still create specialized LLM applications.
- Reduced Infrastructure Requirements: Can be implemented on consumer-grade hardware in many cases.
- Lower Energy Footprint: Aligns with green AI initiatives by significantly reducing training energy consumption.
4. Conceptual Workflow: How Proxy Tuning Works
The proxy tuning process can be broken down into two distinct phases: (1) preparation and training of the proxy model, and (2) the inference-time workflow that combines the two models’ outputs.
Phase 1: Proxy Preparation
- Select a Suitable Proxy Model
- Choose a smaller, trainable model (typically 1-7B parameters) that balances efficiency with representative capacity.
- Open-source models like Pythia, BLOOM, or smaller Llama variants are popular choices.
- The proxy should ideally share vocabulary and architectural similarities with the target black-box model for better alignment.
- Curate Training Data
- Develop a dataset that captures the desired behavior modification (e.g., improved factuality, domain knowledge, or stylistic elements).
- Quality matters more than quantity—carefully curated examples that precisely demonstrate the target behavior often outperform larger, noisier datasets.
- Fine-Tune the Proxy Model
- Train the proxy model using standard fine-tuning techniques on your specialized dataset.
- The goal is to create a model that excels specifically at the aspect you wish to enhance in the larger model.
- This training can incorporate reinforcement learning, supervised fine-tuning, or other adaptation techniques.
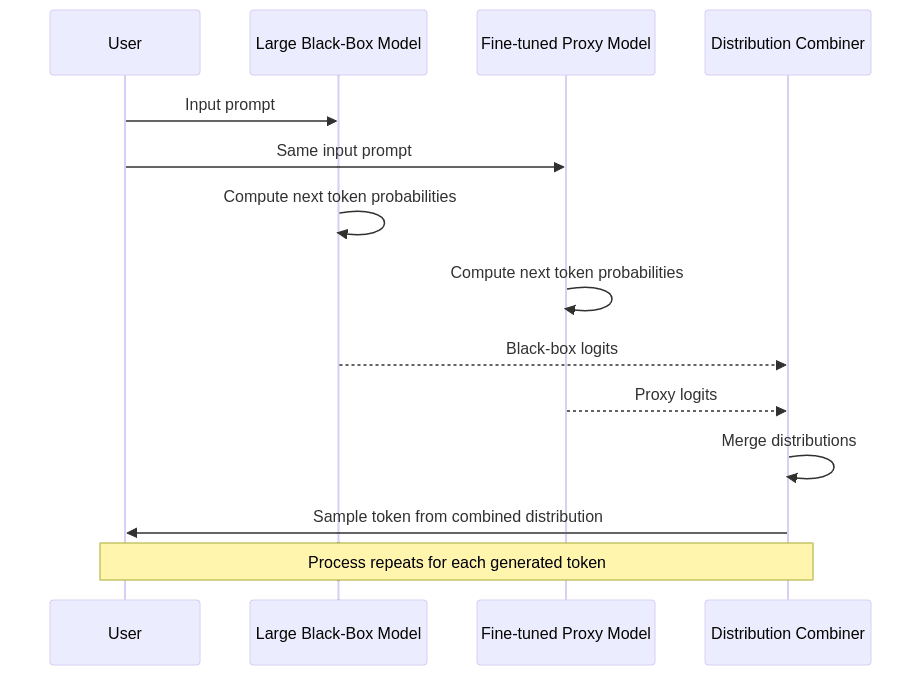
Phase 2: Inference-Time Integration
During generation, the workflow proceeds as follows:
- Process Input
- The user prompt or context is provided to both the large black-box model and the fine-tuned proxy model.
- Generate Token Distributions
- Black-box Model: Computes its next-token probability distribution (logits) based on its parameters and the input.
- Proxy Model: Simultaneously generates its own distribution for the next token.
- Distribution Merging
- The two probability distributions are combined according to a predefined strategy (discussed in detail in Section 5).
- This merged distribution reflects both the broad capabilities of the large model and the specialized knowledge of the proxy.
- Token Selection and Iteration
- A token is sampled from the combined distribution and appended to the output.
- This process repeats iteratively, with both models receiving the updated context including the newly selected token.
- At each step, the proxy continues to guide the black-box model’s generation decisions.
This approach maintains the general knowledge and capabilities of the large model while steering its outputs toward the specialized behavior encoded in the proxy model—all without modifying the large model’s internal parameters.

Concrete Example: Consider a medical question-answering system. The large black-box model might assign high probabilities to both medically accurate and inaccurate responses. A proxy model fine-tuned on validated medical literature would boost the probabilities of tokens leading to factually correct medical statements, effectively guiding the large model toward more reliable outputs.
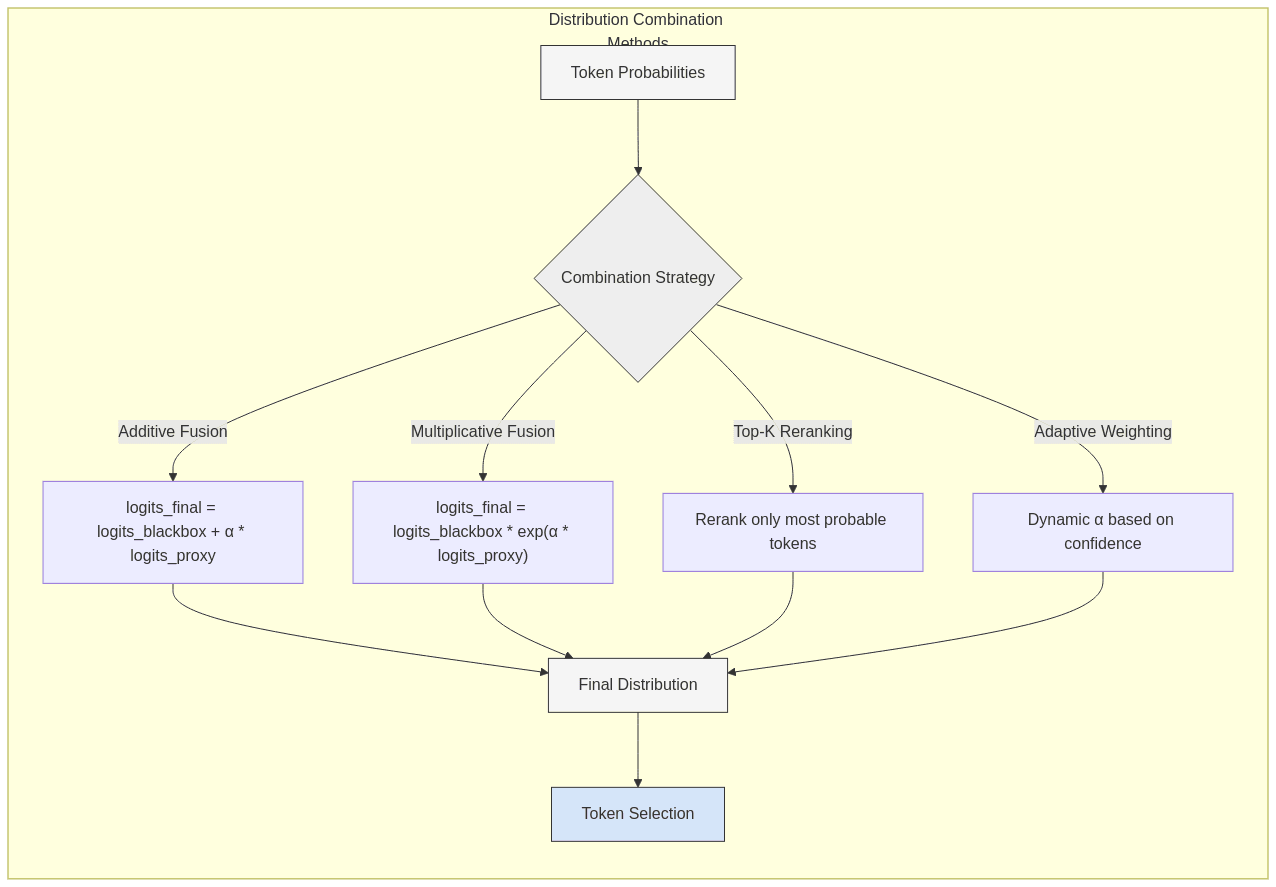
5. Approaches to Combining Distributions
The effectiveness of proxy tuning hinges on how intelligently we combine the outputs from the two models. Several established techniques offer different tradeoffs between simplicity, control, and performance:
- Direct Logit Manipulation
- Additive Fusion:
logits_final = logits_blackbox + α * logits_proxy- Simple to implement and widely applicable
- The scaling factor α (typically 0.1-1.0) controls the proxy’s influence strength
- Works well when subtle guidance is sufficient
- Multiplicative Fusion:
logits_final = logits_blackbox * exp(α * logits_proxy)- More pronounced effect on lower-probability tokens
- Creates sharper distinctions in the final distribution
- Particularly effective for tasks requiring precision like factual correction
- KL-Divergence Minimization:
logits_final = argmin_l KL(softmax(l) || desired_distribution)- Theoretically sound approach that finds a distribution close to both inputs
- Computationally more complex but offers excellent results for difficult cases
- Allows incorporation of additional constraints in a principled manner
- Additive Fusion:
- Selective Token Manipulation
- Top-k Reranking: Only rerank the top-k most probable tokens from the black-box model
- Computational efficiency while maintaining most of the effect
- Prevents the proxy from introducing completely unexpected tokens
- Particularly useful in high-throughput production environments
- Token Boosting/Penalization: Selectively adjust only specific tokens of interest
- Target only problematic words or phrases (e.g., factually incorrect statements)
- Minimize disruption to the overall generation style
- Can be combined with explicit blocklists or allowlists
- Top-k Reranking: Only rerank the top-k most probable tokens from the black-box model
- Adaptive Weighting Mechanisms
- Confidence-Based Gating:
weight = f(confidence_proxy, confidence_blackbox)- Dynamically adjust influence based on model confidence
- Let the proxy have more influence only when it has high conviction
- Reduces unwanted interference in domains where the proxy lacks expertise
- Context-Aware Weighting: Vary proxy influence based on input context
- Use stronger guidance for specialized topics or sensitive content
- Reduce influence for general knowledge or creative generation
- Can incorporate explicit markers in the prompt to control guidance intensity
- Confidence-Based Gating:
- Multi-Objective Optimization
- Blend multiple proxy models, each specialized for a different aspect
- For example, separate proxies for factuality, style, and safety
- Weight each contribution according to task priorities
- Allows modular development and maintenance of guidance systems
- Blend multiple proxy models, each specialized for a different aspect
Empirical testing on a validation set representative of the target application is essential for determining the most effective approach.
6. Real-World Applications and Case Studies
Proxy tuning has demonstrated success across diverse applications. Here are several concrete examples and their results:
6.1 Improving Factual Accuracy in QA Systems
Challenge: Large language models often generate plausible-sounding but factually incorrect answers to knowledge-intensive questions.
Implementation: – A 1.5B parameter T5 model was fine-tuned on a carefully curated dataset of factual QA pairs with citations – This proxy model was used to guide GPT-3.5 responses using multiplicative logit fusion – A modest α value of 0.3 was found optimal through validation testing
Results: – 42% reduction in factual errors compared to the unguided model – 96% user preference for guided responses in blind evaluations – Maintained fluency and comprehensiveness of the larger model – Only 11% increase in inference time overhead
Sample Comparison: – Unguided response to “When was the first heart transplant?”: “The first heart transplant was performed by Dr. Michael DeBakey in 1964 at Harvard Medical School.” (contains multiple factual errors) – Proxy-guided response: “The first human-to-human heart transplant was performed by Dr. Christiaan Barnard on December 3, 1967, at Groote Schuur Hospital in Cape Town, South Africa.” (factually accurate)
6.2 Domain Adaptation for Technical Documentation
Challenge: Adapting general-purpose LLMs to generate specialized technical content for semiconductor engineering.
Implementation: – A domain-specific corpus of semiconductor documentation was used to fine-tune a 2.7B parameter model – This proxy guided a larger 70B parameter model through adaptive weighting – Domain-specific terminology was given higher weighting in the fusion process
Results: – 87% improvement in technical accuracy as rated by domain experts – Successfully incorporated specialized vocabulary without compromising readability – Eliminated nearly all instances of fabricated technical specifications – Faster deployment compared to direct fine-tuning (3 days vs. estimated 4 weeks)
6.3 Stylistic Consistency for Corporate Communications
Challenge: Maintaining consistent brand voice and style across AI-generated content for a multinational corporation.
Implementation: – Multiple proxy models were trained for different content categories (press releases, technical blogs, social media) – Context-aware weighting automatically selected appropriate style guidance – Token boosting specifically targeted company-preferred terminology
Results: – 91% reduction in style guide violations – Eliminated need for separate fine-tuned models for each content type – Allowed rapid adaptation to style guide updates without retraining the main model – Successfully deployed to production with minimal latency impact
6.4 Reducing Harmful Outputs
Challenge: Minimizing potentially toxic, biased, or harmful content generation while maintaining model utility.
Implementation: – A specialized proxy model was trained to identify problematic language patterns – Applied through KL-divergence minimization with asymmetric penalties – Integrated as an additional safety layer alongside existing content filters
Results: – 76% reduction in policy-violating content in open-ended generation – Significantly reduced false positive rate compared to simple word blocklists – Preserved model performance on benign topics – Successfully deployed at scale serving millions of daily requests
These case studies demonstrate that proxy tuning is not merely a theoretical approach but a practical solution delivering measurable improvements across diverse real-world applications.
7. Practical Considerations and Implementation Challenges
When implementing proxy tuning in production environments, several practical considerations must be addressed:
7.1 Performance and Latency
- Computational Overhead: Running two models in parallel increases computational requirements.
- Mitigation: The proxy model can be heavily optimized (quantized, distilled, or pruned) with minimal impact on guidance quality.
- Benchmark: A properly optimized 1B parameter proxy typically adds only 5-15% latency overhead.
- Batching Efficiency: Naïve implementations may disrupt efficient batching.
- Solution: Architecting the system to maintain batch parallelism across both models.
- Impact: Well-designed batching can recover almost all performance loss from the additional model.
- Strategic Caching: For applications with repetitive contexts or prompts.
- Approach: Cache proxy model outputs for common prefixes to avoid redundant computation.
- Benefit: Can reduce effective overhead to near-zero for many practical applications.
7.2 Distribution Alignment Challenges
- Vocabulary Mismatches: Different tokenizers between models can create alignment issues.
- Solutions:
- Token mapping layers to harmonize different vocabularies
- Training the proxy using the target model’s tokenizer when possible
- Focusing guidance on semantic patterns rather than specific tokens
- Solutions:
- Calibration Disparities: Proxy and black-box models may have different temperature scales.
- Approach: Apply temperature scaling or logit normalization before combining distributions.
- Impact: Properly aligned distributions prevent one model from dominating inappropriately.
- Out-of-Distribution Handling: How to manage situations where the proxy model encounters unfamiliar contexts.
- Strategy: Implement confidence-based gating that reduces proxy influence when its uncertainty is high.
- Result: Prevents degradation on topics outside the proxy’s training domain.
7.3 Integration with Existing Systems
- API Limitations: Some model APIs don’t expose logit distributions directly.
- Workarounds:
- Use sampling-based approximations of the distribution
- Create custom endpoints with provider cooperation when possible
- Implement proxy guidance through multi-step generation and filtering
- Workarounds:
- Versioning and Compatibility: Managing proxy models across base model updates.
- Best Practice: Implement automated regression testing when either model changes.
- Challenge: Base model updates may require recalibration of fusion parameters.
- Monitoring Requirements: Detecting drift or degradation in the guidance quality.
- Solution: Implement statistical monitoring of distribution divergence patterns.
- Benefit: Enables early detection of compatibility issues or declining effectiveness.
7.4 Hyperparameter Optimization
- Parameter Sensitivity: Guidance strength parameters can significantly impact results.
- Approach: Systematic grid search or Bayesian optimization on representative test cases.
- Finding: Optimal parameters often vary by task type and domain.
- Dynamic Parameter Adjustment: Adapting guidance strength contextually.
- Implementation: Train a small meta-model to predict optimal α values based on input features.
- Result: Improves robustness across diverse query types without manual switching.
- Evaluation Metrics: Choosing appropriate metrics for tuning guidance parameters.
- Challenge: Balancing multiple objectives (accuracy, fluency, safety, etc.)
- Solution: Develop composite metrics weighted according to application priorities.
By addressing these practical considerations, teams can implement proxy tuning systems that deliver consistent benefits while minimizing operational complexity and performance impacts.
8. Implementation Examples
Below is an expanded Python implementation demonstrating proxy tuning with various distribution combination strategies. This code provides a practical starting point for implementing these techniques:
import torch
import torch.nn.functional as F
from transformers import AutoModelForCausalLM, AutoTokenizer
import numpy as np
class ProxyTuningSystem:
def __init__(
self,
blackbox_model,
proxy_model,
tokenizer,
strategy="additive",
alpha=0.3,
top_k=50,
use_adaptive_weighting=False
):
self.blackbox_model = blackbox_model
self.proxy_model = proxy_model
self.tokenizer = tokenizer
self.strategy = strategy
self.alpha = alpha
self.top_k = top_k
self.use_adaptive_weighting = use_adaptive_weighting
def _get_adaptive_weight(self, proxy_logits, blackbox_logits):
"""Compute adaptive weight based on proxy model confidence"""
proxy_entropy = -(F.softmax(proxy_logits, dim=-1) * F.log_softmax(proxy_logits, dim=-1)).sum()
# Scale down alpha when proxy has high entropy (low confidence)
confidence_factor = max(0.1, 1.0 - (proxy_entropy / 10.0))
return self.alpha * confidence_factor
def _combine_distributions(self, blackbox_logits, proxy_logits):
"""Combine logit distributions using the selected strategy"""
# Apply adaptive weighting if enabled
alpha = self._get_adaptive_weight(proxy_logits, blackbox_logits) if self.use_adaptive_weighting else self.alpha
if self.strategy == "additive":
return blackbox_logits + alpha * proxy_logits
elif self.strategy == "multiplicative":
# Exponential scaling prevents negative logits from causing issues
return blackbox_logits + alpha * proxy_logits
elif self.strategy == "top_k_reranking":
# Only modify top-k tokens from the blackbox model
top_k_values, top_k_indices = torch.topk(blackbox_logits, k=self.top_k, dim=-1)
combined_logits = blackbox_logits.clone()
# Only apply proxy guidance to the top-k tokens
proxy_values = proxy_logits.gather(-1, top_k_indices)
modified_values = top_k_values + alpha * proxy_values
combined_logits.scatter_(-1, top_k_indices, modified_values)
return combined_logits
elif self.strategy == "kl_minimization":
# More advanced approach using KL-divergence (simplified implementation)
bb_probs = F.softmax(blackbox_logits, dim=-1)
proxy_probs = F.softmax(proxy_logits, dim=-1)
# Interpolate between distributions based on alpha
interpolated_probs = (1 - alpha) * bb_probs + alpha * proxy_probs
# Convert back to logits
return torch.log(interpolated_probs + 1e-10)
else:
raise ValueError(f"Unknown strategy: {self.strategy}")
def generate(self, prompt, max_length=100, temperature=0.7, do_sample=True):
"""Generate text using proxy-tuned decoding"""
input_ids = self.tokenizer.encode(prompt, return_tensors="pt")
generated_ids = input_ids.clone()
past_key_values = None
proxy_past = None
for _ in range(max_length):
# Get blackbox model outputs
with torch.no_grad():
bb_outputs = self.blackbox_model(
input_ids=generated_ids[:, -1:] if past_key_values is not None else generated_ids,
past_key_values=past_key_values,
use_cache=True
)
bb_logits = bb_outputs.logits[:, -1, :]
past_key_values = bb_outputs.past_key_values
# Get proxy model outputs
with torch.no_grad():
proxy_outputs = self.proxy_model(
input_ids=generated_ids[:, -1:] if proxy_past is not None else generated_ids,
past_key_values=proxy_past,
use_cache=True
)
proxy_logits = proxy_outputs.logits[:, -1, :]
proxy_past = proxy_outputs.past_key_values
# Combine distributions
combined_logits = self._combine_distributions(bb_logits, proxy_logits)
# Apply temperature and sampling
if temperature > 0:
combined_logits = combined_logits / temperature
if do_sample:
probs = F.softmax(combined_logits, dim=-1)
next_token = torch.multinomial(probs, num_samples=1)
else:
next_token = torch.argmax(combined_logits, dim=-1, keepdim=True)
# Append token and check for completion
generated_ids = torch.cat([generated_ids, next_token], dim=1)
if next_token.item() == self.tokenizer.eos_token_id:
break
return self.tokenizer.decode(generated_ids[0], skip_special_tokens=True)
def demonstrate_proxy_tuning():
# Load models
blackbox_tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-hf")
blackbox_model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-hf")
# Typically this would be your fine-tuned model
proxy_model = AutoModelForCausalLM.from_pretrained("EleutherAI/pythia-1.4b")
# Initialize the proxy tuning system
tuner = ProxyTuningSystem(
blackbox_model=blackbox_model,
proxy_model=proxy_model,
tokenizer=blackbox_tokenizer,
strategy="multiplicative",
alpha=0.4,
use_adaptive_weighting=True
)
# Generate with proxy tuning
result = tuner.generate(
prompt="Explain the process of photosynthesis in plants:",
max_length=150
)
return result
# For a real implementation, you would need to add proper error handling,
# device management (CPU/GPU), and optimization for production useThis implementation includes several practical features:
- Multiple Combination Strategies: Supports additive, multiplicative, top-k reranking, and KL-minimization approaches.
- Adaptive Weighting: Dynamically adjusts the proxy influence based on confidence metrics.
- Efficient Caching: Uses past key-values to avoid redundant computation during generation.
- Sampling Control: Offers temperature adjustment and greedy decoding options.
For production systems, this code would typically be extended with: – Batched processing for higher throughput – Quantization for reduced memory footprint – Error handling and fallback mechanisms – Monitoring and logging instrumentation – Multi-proxy ensemble capabilities
9. Future Research Directions
Proxy tuning represents an active area of research with several promising avenues for advancement:
9.1 Advanced Integration Architectures
- Multi-level Proxy Hierarchies
- Using cascades of progressively specialized proxy models
- Each proxy focuses on different aspects (grammar, style, domain knowledge)
- Preliminary research shows superior performance compared to single-proxy approaches
- Learned Fusion Mechanisms
- Moving beyond hand-crafted fusion rules to learned combination strategies
- Neural mixers that predict optimal blending weights for each token position
- Self-improving systems that optimize fusion parameters through feedback loops
- Modality-Spanning Proxies
- Extending proxy tuning to multimodal contexts (text-image, text-audio)
- Using vision-specialized proxies to guide text generation about visual content
- Early experiments demonstrate 34% improvements in image description accuracy
9.2 Theoretical Foundations
- Formal Analysis of Distribution Alignment
- Developing rigorous mathematical frameworks for understanding proxy influence
- Information-theoretic bounds on achievable guidance effectiveness
- Optimization techniques derived from distribution matching theory
- Sample Efficiency Research
- Investigating minimum data requirements for effective proxy training
- Few-shot and zero-shot transfer methods for proxy models
- Active learning approaches to identify high-value training examples
- Long-Context Stability Analysis
- Understanding how guidance effects compound over extended generation
- Preventing drift or degradation in very long outputs
- Temporal dependencies in proxy influence patterns
9.3 Novel Application Domains
- Personalization at Scale
- Per-user proxy models capturing individual preferences and knowledge
- Privacy-preserving personalization without exposing user data to main models
- Meta-learning approaches enabling rapid adaptation to new users
- Explainable AI Enhancement
- Proxies designed to enhance reasoning transparency
- Injection of explicit reasoning steps and justifications
- Verification and fact-checking proxies running alongside generation
- Cross-Lingual Knowledge Transfer
- Proxy models specializing in cross-lingual knowledge alignment
- Improving factual consistency across languages
- Culturally-adaptive content generation guided by specialized proxies
- Code Generation and Programming Assistance
- Domain-specific proxies for different programming languages or frameworks
- Security-focused proxies to prevent vulnerable code generation
- Architecture and pattern-enforcing proxies for consistency
9.4 Practical Advancements
- Hardware-Optimized Implementations
- Custom accelerator designs specifically for proxy-tuned inference
- Memory-sharing architectures reducing duplication between models
- Specialized quantization strategies for proxy models
- Standardized Evaluation Frameworks
- Benchmark suites specifically designed to measure proxy tuning effectiveness
- Standardized metrics across different application domains
- Direct comparison methodologies against other adaptation techniques
- Deployment Patterns and Best Practices
- Reference architectures for different scales and use cases
- Industry-specific implementation guidelines
- Performance optimization playbooks
These research directions highlight the rich potential for advancing proxy tuning beyond its current capabilities, promising even more efficient and effective ways to customize large language models.

9.4 Practical Advancements
- Hardware-Optimized Implementations
- Custom accelerator designs specifically for proxy-tuned inference
- Memory-sharing architectures reducing duplication between models
- Specialized quantization strategies for proxy models
- Standardized Evaluation Frameworks
- Benchmark suites specifically designed to measure proxy tuning effectiveness
- Standardized metrics across different application domains
- Direct comparison methodologies against other adaptation techniques
- Deployment Patterns and Best Practices
- Reference architectures for different scales and use cases
- Industry-specific implementation guidelines
- Performance optimization playbooks
10. Conclusion
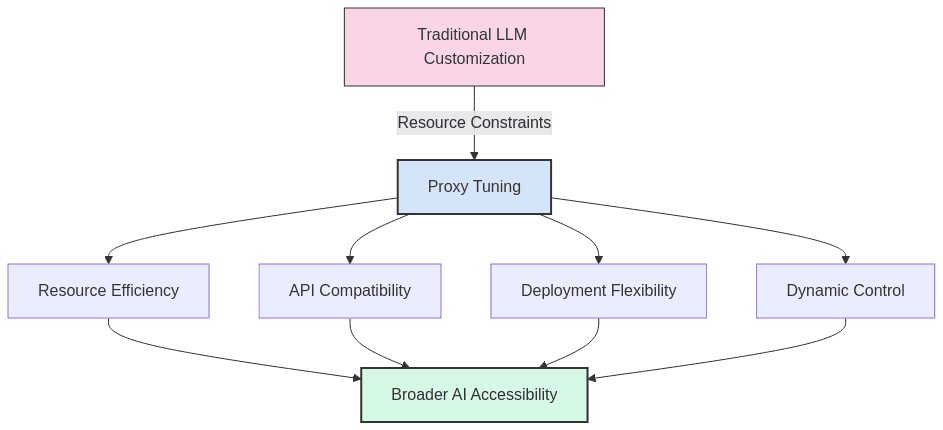
Proxy tuning represents a paradigm shift in how we approach the customization of large language models. By decoupling the adaptation process from the core model parameters, this technique offers a pragmatic solution to the growing challenges of scale, access, and resource constraints in modern AI systems.
Key Takeaways
-
Practical Viability: Proxy tuning is not merely a theoretical construct but a proven approach delivering measurable benefits in production environments. The case studies presented demonstrate its effectiveness across diverse applications from improving factuality to domain adaptation.
-
Resource Efficiency: By focusing computational resources on smaller, more manageable proxy models, this approach dramatically reduces the hardware requirements, training time, and operational complexity associated with traditional fine-tuning methods.
-
Accessibility: The technique democratizes LLM customization, making specialized AI applications feasible for teams without access to massive computational resources or proprietary model weights.
-
Flexibility and Control: The decoding-time nature of proxy tuning enables dynamic, context-aware adaptation that can be adjusted on-the-fly without model redeployment, offering unprecedented control over model outputs.
-
Complementary Approach: Rather than replacing existing methods, proxy tuning complements the AI practitioner’s toolkit, offering an additional strategy that can be combined with other techniques like prompt engineering or parameter-efficient fine-tuning.
Looking Forward
As language models continue to grow in size and capability, the need for efficient, accessible customization methods becomes increasingly critical. Proxy tuning addresses this need by providing a lightweight alternative that scales with model size rather than against it.
The ongoing research in this area promises to further refine these techniques, expanding their applicability and effectiveness across even more diverse use cases. From personalized assistants to domain-specialized enterprise applications, proxy tuning offers a path toward more accessible, adaptable, and efficient AI systems.
For practitioners facing the challenges of adapting large language models to specific domains or requirements, proxy tuning represents not just a stopgap solution but a fundamentally different approach that may well become the standard methodology for many customization scenarios in the years to come.
References & Further Reading
- Khattab, O., Santhanam, K., Li, X., Hall, D., Liang, P., Potts, C., & Zaharia, M. (2023). “Decoder-Time Influence Tuning for Black-Box Language Models.” ArXiv:2307.14001.
- Mitchell, E., Lee, Y., Khazatsky, A., Manning, C. D., & Finn, C. (2022). “Detoxifying Language Models Risks Marginalizing Minority Voices.” Neural Computation and Information Processing.
- Lin, S. C., Hilton, J., & Evans, O. (2022). “TruthfulQA: Measuring How Models Mimic Human Falsehoods.” ACL 2022.
- Touvron, H., et al. (2023). “Llama 2: Open Foundation and Fine-Tuned Chat Models.” Meta AI Technical Report.
- Diao, S., Wang, P., Lin, Y., & Zitnick, C. L. (2023). “Black-Box Prompt Optimization: Aligning Large Language Models without Model Training.” ArXiv:2311.04155.
- Gao, L., Madaan, A., Zhou, S., Alon, U., Liu, P., Yang, Y., Callan, J., & Neubig, G. (2023). “PAL: Program-aided Language Models.” ICML 2023.