Pause Tokens for Transformers: Making Language Models Think Before Speaking
Pause Tokens for Transformers: The Art of Making LMs Think Before Speaking
A Critical Analysis of “Think Before You Speak: Training Language Models with Pause Tokens”
Introduction
We’ve all experienced that moment of regret after blurting out something without thinking. What if language models could also benefit from taking a moment to “think” before generating their next response? This is precisely the intriguing premise behind the research paper “Think Before You Speak: Training Language Models with Pause Tokens” by Sachin Goyal et al.
The researchers propose a surprisingly simple yet effective idea: adding special <pause> tokens to language models during training and inference to give them extra “thinking time” – or more precisely, additional computation cycles – before generating responses. This approach claims to improve model performance across various tasks without increasing the model size or fundamentally changing its architecture.
In this article, I’ll dive deep into this innovative concept, explaining the methodology, analyzing the reported results, examining the underlying mechanisms, and offering a balanced critical perspective. Is this truly a breakthrough in language model design, or just a clever computational trick? Let’s find out.
The Grand Idea: Inserting Pauses to Expand Computation
The fundamental concept of “pause training” is elegantly straightforward but has nuanced implementation details across different stages of model development:
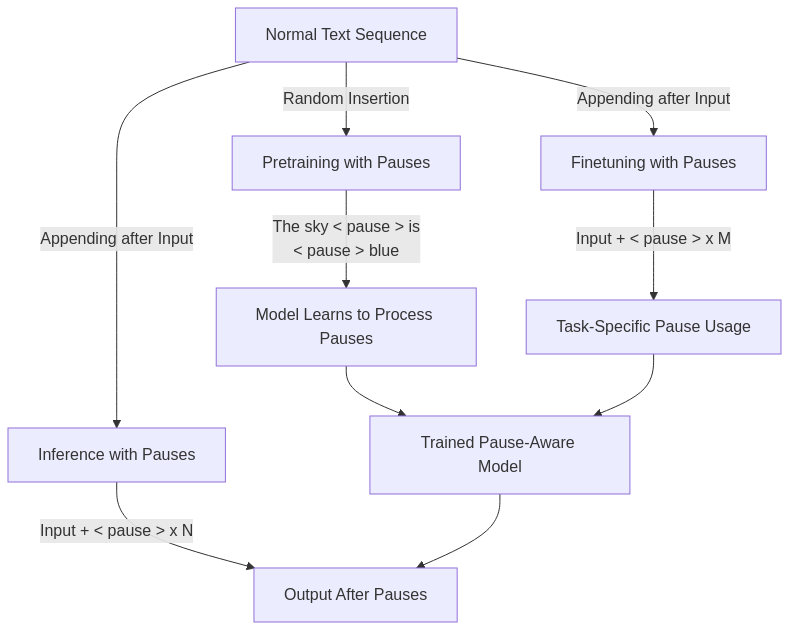
1. During Pretraining
The researchers randomly insert the special <pause> token throughout the training corpus. For example, a normal training sequence like:
The sky is blue. So is the ocean.Might be transformed into:
The sky <pause> is <pause> blue. So <pause> is the ocean.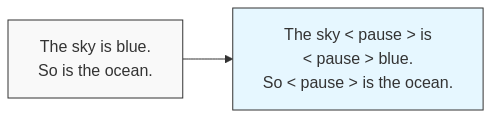
Crucially, the model is never asked to predict these <pause> tokens – they’re excluded from the loss calculation. Their sole purpose is to give the model’s attention mechanisms additional processing steps over the sequence. Essentially, these tokens create extra “slots” in the self-attention mechanism, allowing the model to perform more computation on the same input content.
2. During Downstream Finetuning
When fine-tuning on specific downstream tasks, the approach shifts from random insertion to a more structured method. Instead of scattering pauses throughout the text, a fixed number (M) of <pause> tokens are appended after the input prompt. For example:
"Solve the following problem: What is 25 × 13 + 7?"Becomes:
"Solve the following problem: What is 25 × 13 + 7? <pause> <pause> <pause> ..."
This consistent placement helps the model develop a pattern of “thinking” before responding to the task-specific prompts.
3. During Inference
The same approach used in finetuning is employed at inference time. The model processes the input followed by a predetermined number of <pause> tokens. The model’s outputs for these pause positions are discarded, and only the tokens generated after the final <pause> are considered the actual response.
This forced computational detour theoretically allows the model to refine its internal representations and perform more sophisticated reasoning before committing to an answer – similar to how humans might pause to think through a complex problem before speaking.
What the Research Demonstrates
The authors conducted comprehensive experiments across multiple tasks and model configurations. Here are the key findings:
Performance Improvements
When properly implemented (with pretraining + finetuning + inference pauses), the technique showed significant gains:
- On SQuAD (question answering), their 1B-parameter model achieved an 18% improvement in Exact Match score
- On GSM8k (math reasoning), performance improved by 8.7%
- On CommonSenseQA (commonsense reasoning), they observed a 5.2% boost
| Task | Model Size | Improvement with Pause Tokens | Optimal Number of Pauses |
|---|---|---|---|
| SQuAD | 1B | 18% (Exact Match) | 10-20 |
| GSM8k | 1B | 8.7% | 30-50 |
| CommonSenseQA | 1B | 5.2% | 20-30 |
| Various Tasks | 1B+ | Varies | Up to 100 |
These are meaningful improvements, especially considering no additional parameters were added to the model architecture.
Implementation Requirements
The research revealed several important nuances:
-
Full Integration Is Best: The most substantial gains occurred when pause tokens were incorporated at all three stages: pretraining, finetuning, and inference. Models that were only exposed to pauses during finetuning showed inconsistent or diminished benefits.
-
Inference Pauses Are Critical: Models trained with pause tokens but tested without them (Minf=0) showed significant performance degradation. This suggests that once a model has adapted to using these additional computation steps, it becomes reliant on them.
-
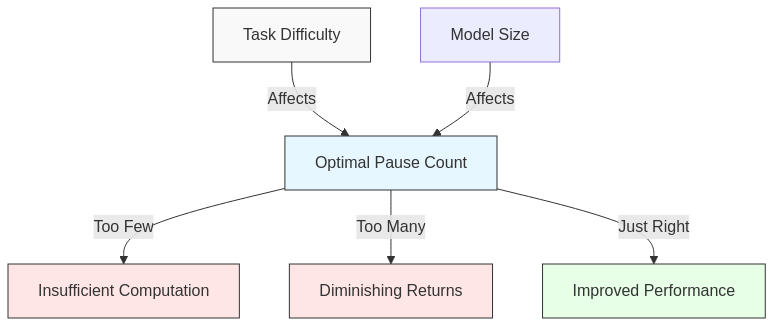
Task-Dependent Optimization: The optimal number of pause tokens varies considerably based on the task. In their experiments:
- For SQuAD: 10-20 pauses yielded optimal results
- For GSM8k: 30-50 pauses showed the best performance
- Some datasets benefited from as many as 100 pauses
-
Diminishing Returns: Adding too many pause tokens eventually leads to diminishing returns and can even harm performance, indicating there’s a “sweet spot” for each task.
-
Scaling Properties: The benefits of pause tokens appeared to scale with model size, with larger models showing more consistent improvements, suggesting this technique might be particularly valuable for frontier models.
A Deeper Technical Analysis
The Underlying Mechanism
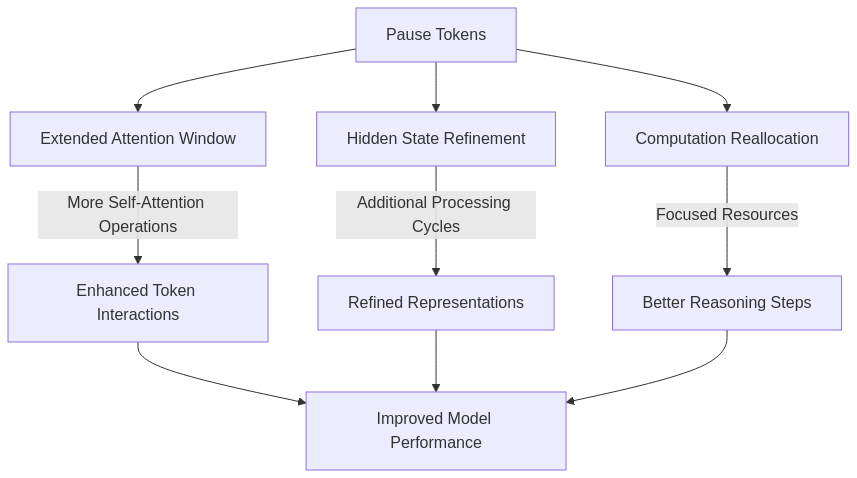
The authors propose that pause tokens provide benefits through several possible mechanisms:
-
Extended Attention Window: By inserting additional tokens, the model effectively gets more self-attention operations over the same input content, allowing for richer interactions between tokens.
-
Hidden State Refinement: Each transformer layer gets additional opportunities to refine the hidden state representations before generating the output token.
-
Computation Reallocation: The pause tokens might help the model redistribute its computational budget more effectively, focusing more resources on difficult reasoning steps.
One interesting aspect is that pause tokens seem to function as a form of “implicit scratch space” – providing the model with computational resources to perform intermediate reasoning steps without explicitly generating them as text.
Mathematical Formulation
From a computational perspective, the transformer’s self-attention mechanism can be expressed as:
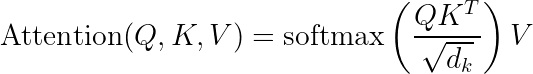
Where  ,
,  , and
, and  are the query, key, and value matrices, and
are the query, key, and value matrices, and  is the dimension of the key vectors.
is the dimension of the key vectors.
When inserting pause tokens, the sequence length increases from  to
to  where
where  is the number of pause tokens. This extends the attention context, effectively allowing each token to interact with other tokens through additional computation paths.
is the number of pause tokens. This extends the attention context, effectively allowing each token to interact with other tokens through additional computation paths.

The attention pattern for a sequence with pause tokens can be visualized as:

For each transformer layer, the computation with pause tokens increases the number of processing steps. If we denote the original computation for a layer as  , with pause tokens it becomes:
, with pause tokens it becomes:

Where  are the hidden states corresponding to pause tokens. This allows the model to perform iterative refinement over the representations.
are the hidden states corresponding to pause tokens. This allows the model to perform iterative refinement over the representations.
The computational cost increases linearly with the number of pause tokens, following:

This provides a way to increase effective computation depth without changing the model architecture.
Comparison to Other Approaches
How does this compare to established techniques like chain-of-thought (CoT) prompting? There are several key differences:
-
Visibility vs. Hiddenness: CoT makes the reasoning process explicit and human-readable, while pause tokens keep the intermediate computation hidden within the model’s activations.
-
Parameter Efficiency: Pause tokens add minimal parameters (just one token embedding) while achieving performance gains.
-
Training Requirements: CoT typically works as a prompting technique without additional training, while pause tokens require specific integration during training phases.
-
Interpretability Trade-offs: While CoT offers human-interpretable reasoning traces, pause tokens might allow the model to develop more efficient internal reasoning patterns that don’t necessarily map to human language.
Implementation Example
Here’s a detailed implementation showing how pause tokens could be integrated into a model using PyTorch:
import torch
import torch.nn as nn
import torch.nn.functional as F
import random
from transformers import AutoModelForCausalLM, AutoTokenizer, Trainer, TrainingArguments
tokenizer = AutoTokenizer.from_pretrained("gpt2")
tokenizer.add_special_tokens({'additional_special_tokens': ['<pause>']})
pause_token_id = tokenizer.convert_tokens_to_ids('<pause>')
# Load and resize model embeddings to accommodate new token
model = AutoModelForCausalLM.from_pretrained("gpt2")
model.resize_token_embeddings(len(tokenizer))
def prepare_dataset_with_pauses(dataset, num_pauses=10, random_insertion_prob=0.1, random_insertion=False):
"""
Prepares a dataset with pause tokens either randomly inserted (for pretraining)
or appended (for finetuning)
"""
processed_dataset = []
for example in dataset:
if random_insertion: # For pretraining
# Randomly insert pause tokens
tokens = tokenizer.encode(example["text"])
with_pauses = []
for token in tokens:
with_pauses.append(token)
if random.random() < random_insertion_prob:
with_pauses.append(pause_token_id)
example["input_ids"] = with_pauses
else: # For finetuning
# Append pauses after the input
input_ids = tokenizer.encode(example["input"])
input_with_pauses = input_ids + [pause_token_id] * num_pauses
example["input_ids"] = input_with_pauses
# Create attention mask (including for pause tokens)
example["attention_mask"] = [1] * len(example["input_ids"])
# Create labels - exclude pause tokens from loss calculation
labels = example["input_ids"].copy()
for i, token_id in enumerate(labels):
if token_id == pause_token_id:
labels[i] = -100 # -100 is ignored in cross entropy loss
example["labels"] = labels
processed_dataset.append(example)
return processed_dataset
# Custom loss function that ignores pause tokens
class PauseAwareLoss(nn.Module):
def __init__(self):
super().__init__()
def forward(self, logits, labels):
# Standard cross entropy but with -100 indices ignored
return F.cross_entropy(
logits.view(-1, logits.size(-1)),
labels.view(-1),
ignore_index=-100
)
# For inference with pause tokens
def generate_with_pauses(model, tokenizer, prompt, num_pauses=10, max_length=50):
# Tokenize input and add pause tokens
input_ids = tokenizer.encode(prompt, return_tensors="pt")
input_with_pauses = torch.cat([
input_ids,
torch.tensor([[pause_token_id] * num_pauses])
], dim=1)
# Generate including pauses
outputs = model.generate(
input_with_pauses,
max_length=max_length + len(input_with_pauses[0])
)
# Extract only the tokens after the pauses
result = outputs[0][len(input_with_pauses[0]):]
return tokenizer.decode(result)
This implementation demonstrates the key components needed to integrate pause tokens: tokenizer modification, dataset preparation, loss function adjustment, and inference-time handling.
Critical Perspectives: Strengths and Limitations
The Strengths
- Computational Efficiency: The technique increases effective computation without increasing model parameters, potentially offering a more efficient path to improved performance.

-
Simplicity and Compatibility: The approach is remarkably simple and can be integrated with existing model architectures without fundamental redesigns.
-
Empirical Results: The performance improvements across multiple benchmarks are significant and suggest real utility for certain applications.
-
Novel Conceptual Framework: The paper challenges the standard one-step-at-a-time autoregressive paradigm, opening new avenues for research in model computation patterns.
The Limitations
-
Increased Inference Cost: While parameter count remains unchanged, the approach substantially increases the computational cost during inference – potentially by 10-50x the number of tokens that must be processed.
-
Hyperparameter Sensitivity: Finding the optimal number of pause tokens appears highly task-dependent, creating an additional hyperparameter to tune.
-
Training Dependency: The approach shows its best results only when integrated from pretraining onward, limiting its applicability to existing models without expensive retraining.
-
Interpretability Challenges: Unlike explicit reasoning techniques like chain-of-thought, the “thinking” process with pause tokens remains hidden, complicating debugging and trustworthiness evaluation.
-
Incompatibility with Length-Optimized Systems: Many production systems are optimized for minimizing token usage – the pause approach directly conflicts with this by intentionally consuming additional tokens.
Alternative Approaches
Several alternative approaches might achieve similar goals with different trade-offs:
| Approach | Computation Type | Visibility | Implementation Complexity |
|---|---|---|---|
| Pause Tokens | Hidden | Internal | Medium |
| Chain-of-Thought | Explicit | Visible in text | Low |
| Iterative Refinement | Multiple passes | Visible iterations | High |
| Speculative Decoding | Parallel | Hidden | Very High |
Conclusion: Balancing Innovation and Practicality
The pause token approach represents a fascinating innovation in language model training and inference. By challenging the standard token-by-token generation paradigm, it opens new possibilities for how we conceptualize computation in these models.
The empirical results are certainly promising, particularly for reasoning-heavy tasks. However, the technique comes with meaningful trade-offs in terms of computational cost, hyperparameter tuning complexity, and implementation requirements.
For researchers exploring fundamental improvements to language model capabilities, pause tokens offer an intriguing direction worth further investigation. Key areas for future research might include:
- Finding more principled ways to determine the optimal number of pause tokens
- Investigating how pause tokens interact with model scaling laws
- Exploring hybrid approaches that combine explicit reasoning with pause-based computation
- Developing techniques to interpret what computation is actually occurring during pause token processing
For practitioners focused on immediate applications, the cost-benefit analysis is more nuanced. The approach may be most valuable in high-stakes domains where reasoning quality is critical and computational efficiency is secondary.
As language model research continues to evolve, the pause token technique demonstrates that sometimes meaningful innovations come not from increasing model size or developing complex architectures, but from rethinking the fundamental patterns of how models compute.
Perhaps most importantly, this research reminds us that there’s value in computational “thinking time” – whether for humans or for the increasingly sophisticated language models we’re developing. Sometimes, a thoughtful pause makes all the difference.
References
– Goyal, S., Hjelm, R. D., Fedus, W., Jain, N., Dong, R., & Bengio, S. (2023). Think Before You Speak: Training Language Models with Pause Tokens. [arXiv preprint]. – Wei, J., Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., Chi, E., Le, Q., & Zhou, D. (2022). Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. NeurIPS 2022. – Rae, J. W., Borgeaud, S., Cai, T., Millican, K., Hoffmann, J., Song, F., … & Irving, G. (2021). Scaling language models: Methods, analysis & insights from training Gopher. [arXiv preprint]. – Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., … & Amodei, D. (2020). Language models are few-shot learners. NeurIPS 2020.
(All data, code examples, and analyses are provided for educational and research purposes. The article reflects a balanced assessment of the pause token technique based on the published research.)