Mixture of Experts (MoE): Scaling AI with Intelligent Specialization
Introduction: The Challenge of Scale in Modern AI
In the race to build more capable AI systems, the field has witnessed an exponential growth in model sizes. Modern Transformer-based architectures—like GPT, LLaMA, BERT, T5, and their successors—regularly exceed hundreds of billions of parameters. While these massive models have demonstrated remarkable capabilities across diverse tasks, they come with significant challenges:
- Computational demands that strain even the most advanced hardware
- Memory limitations restricting deployment options
- Energy consumption concerns raising questions of sustainability
- Diminishing returns from simply scaling model size
Enter Mixture of Experts (MoE), an architectural paradigm that fundamentally reimagines how we scale neural networks. Rather than forcing every input to traverse the same massive parameter space, MoE architectures intelligently route inputs to specialized sub-networks called “experts.” This approach enables models to:
- Achieve dramatically larger parameter counts without proportionally increasing computation
- Develop specialized knowledge domains through expert specialization
- Balance performance with efficiency in novel ways
This article explores how MoE works, its implementation in cutting-edge models, and why it represents one of the most promising directions for building more powerful and efficient AI systems.
1. The Promise of MoE: Why Conditional Computation Matters
Traditional neural networks process all inputs through identical parameters, regardless of the input’s nature. This “one-size-fits-all” approach becomes increasingly inefficient as models scale. Mixture of Experts offers a more nuanced solution through these key mechanisms:
1.1 Sparse Activation: Computing Less, Achieving More
- Traditional Transformer layers are “dense”—every token passes through the entire parameter set
- MoE activates only a small subset of parameters (typically 1-2 experts out of many) per token
- This conditional computation drastically reduces FLOPs (floating-point operations) during both training and inference
- Research shows MoE can achieve similar performance to dense models with 1/10th the computational cost
1.2 Specialization: Leveraging the Power of Focus
- Individual experts naturally specialize in different domains, styles, or linguistic patterns
- This emergent specialization happens without explicit supervision
- Studies show experts often develop focus areas (e.g., code, scientific text, conversational language)
- The router dynamically directs tokens to the most appropriate expert based on input characteristics

1.3 Efficient Scaling: Breaking the Computation-Capacity Barrier
- MoE allows adding parameters (capacity) without proportionally increasing computation
- This relationship fundamentally changes the scaling laws for neural networks
- Models like Switch Transformer demonstrated a 7x training speedup compared to equivalent dense models
- The sparse activation pattern creates new opportunities for hardware-efficient deployment

1.4 Empirical Success: Setting New Performance Benchmarks
- Google’s Switch Transformer and GLaM achieved breakthrough performance-to-compute ratios
- Meta’s implementation in their latest models shows significant efficiency gains
- Research across NLP tasks consistently demonstrates MoE advantages at scale
- Open-source implementations like Fairseq-MoE have democratized access to this technique
2. MoE Architecture: A Technical Deep Dive
Understanding how MoE works requires examining its key components and their interactions. Here’s a detailed look at the architecture that makes conditional computation possible:
2.1 Core Components and Data Flow
A standard Transformer architecture with MoE typically follows this pattern:
- Input Embedding & Positional Encoding: Standard Transformer processing
- Self-Attention Mechanism: Processes relationships between tokens (unchanged from standard Transformers)
- MoE Feed-Forward Layer: Replaces the traditional FFN with a sparse MoE layer:
- Router Network: Determines which expert(s) process each token
- Expert Networks: Multiple feed-forward networks with separate parameters
- Combination Mechanism: Aggregates outputs from selected experts
This pattern can repeat throughout the model, with MoE layers often alternating with traditional dense layers.
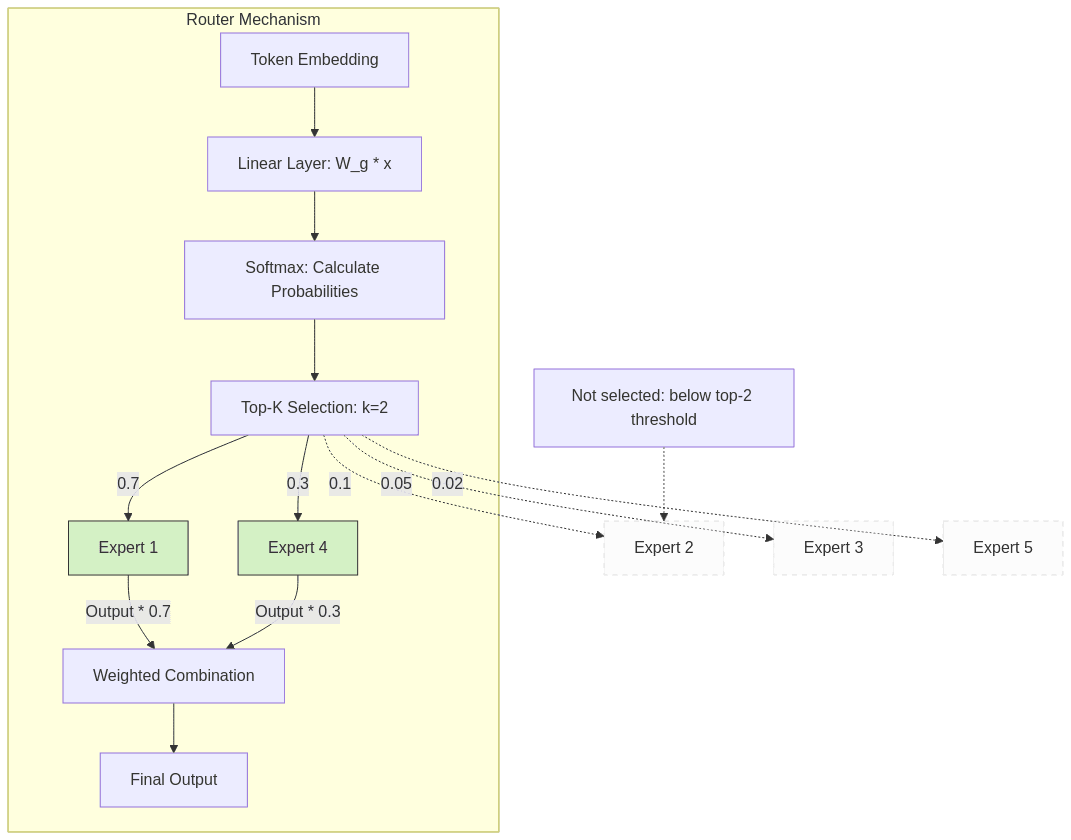
2.2 The Router: The Brain Behind Expert Selection
At the heart of every MoE layer is the router (or gating network), which makes critical decisions about token-to-expert assignment:
- Architecture: Typically a simple neural network (often just a linear layer followed by softmax/top-k selection)
- Input: Takes token representations from the previous layer
- Processing: Computes “routing probabilities” for each token-expert pair
- Output: Produces routing decisions, usually selecting the top-k experts (k=1 or 2) for each token
The mathematical formulation for basic top-k routing is:
g(x) = TopK(softmax(W_g * x))Where:
– x is the token representation
– W_g is the router’s weight matrix
– TopK selects the k highest probability experts
2.3 Expert Networks: Specialized Processing Units
Each expert in an MoE layer is an independent neural network with its own parameters:
- Structure: Typically a standard feed-forward network (FFN) with two or more dense layers
- Isolation: Experts don’t directly share parameters, enabling specialization
- Capacity: Individually similar to standard Transformer FFNs, but collectively much larger
- Activation: Only processes tokens specifically routed to it
2.4 Load Balancing: Preventing Expert Collapse
Without constraints, routers tend to send disproportionate numbers of tokens to a small subset of experts, leading to: – Underutilization of model capacity – Training instability – Poor specialization
To prevent this, MoE implementations employ load balancing mechanisms:
- Auxiliary Loss Terms: Additional loss components that penalize imbalanced routing
- Capacity Factors: Limiting the maximum tokens per expert
- Differentiable Load Balancing: Router designs that inherently encourage balance
For example, Switch Transformer uses an auxiliary loss of the form:
L_balance = α * ∑_i (fraction_of_tokens_to_expert_i - 1/num_experts)²Where α is a hyperparameter controlling the strength of load balancing.
3. Notable MoE Implementations in Production Systems
MoE has moved from theoretical concept to production-ready technology in several high-profile systems:
3.1 Google’s Switch Transformer
- Pioneered simplified top-1 routing (each token goes to exactly one expert)
- Scaled to over 1.7 trillion parameters while training significantly faster than dense models
- Achieved new state-of-the-art results on various NLP tasks
- Introduced techniques for stabilizing training of sparse models at scale
3.2 GLaM (Generalist Language Model)
- Used a mixture of 64 experts per MoE layer
- Activated only a small fraction (~2%) of parameters for each token
- Demonstrated 2x the performance of GPT-3 on various benchmarks while using 1/3 the energy for training
- Incorporated advanced load-balancing and expert utilization techniques
3.3 Fairseq-MoE
- Facebook/Meta’s implementation in their PyTorch-based Fairseq framework
- Provides modular components for incorporating MoE into various model architectures
- Features distributed training capabilities for efficient multi-node deployment
- Supports configurable routing strategies and balancing mechanisms
3.4 Mixtral 8x7B
- Released by Mistral AI in late 2023
- Employs 8 experts per layer with activation of 2 experts per token
- Outperforms much larger dense models despite using less compute during inference
- Demonstrates strong performance across multiple domains with minimal instruction tuning
4. Training MoE at Scale: Practical Considerations
The distributed nature of MoE models introduces unique training challenges and opportunities:
4.1 Distributed Training Strategies
Efficiently training large MoE models requires specialized approaches to parallelism:
- Data Parallelism:
- Each device processes different batches with the same model
- Gradients are synchronized across devices
- Standard in most distributed training setups
- Expert Parallelism:
- Distinct from model parallelism
- Distributes experts across devices
- Each device hosts a subset of the total experts
- Requires custom communication patterns for token routing
- Hybrid Approaches:
- Combining expert parallelism with tensor/pipeline parallelism
- Allows scaling to extremely large models (100B+ parameters)
- Requires sophisticated orchestration of compute resources

4.2 Communication Patterns and Efficiency
The sparse activation pattern of MoE creates unique communication requirements:
- All-to-All Communication: Tokens must be gathered and dispatched to devices hosting the required experts
- Token Dispatching: Grouping tokens by assigned expert to minimize communication overhead
- Expert Sharding: Strategically distributing experts to minimize cross-device communication
4.3 Training Stability Techniques
MoE models can be challenging to train stably. Effective techniques include:
- Auxiliary Losses: Beyond load balancing, regularization to prevent expert collapse
- Expert Dropout: Randomly dropping experts during training for robustness
- Router Z-Loss: Penalizing extreme routing decisions to maintain diverse expert utilization
- Initialization Strategies: Special initialization for experts to encourage diverse specialization
4.4 Implementation Example (Fairseq Style)
fairseq-train data-bin/wmt14_en_de/ \
--arch transformer_moe \
--task translation \
--moe-experts 16 \
--moe-freq 2 \
--moe-gating-func top2 \
--moe-second-expert-policy all \
--moe-eval-capacity-token-fraction 0.25 \
--moe-load-balance-loss-coefficient 0.01 \
--distributed-world-size 8 \
--fp16Key parameters include:
– --moe-experts 16: Sets the number of experts per MoE layer
– --moe-freq 2: Indicates MoE layers appear every 2 layers in the Transformer stack
– --moe-gating-func top2: Selects 2 experts per token
– --moe-load-balance-loss-coefficient 0.01: Controls the strength of load balancing
– --distributed-world-size 8: Distributes training across 8 devices
5. Inference and Deployment: Bringing MoE to Production
The unique architecture of MoE models creates both challenges and opportunities for efficient deployment:
5.1 Memory Management Strategies
MoE models can have trillions of parameters, far exceeding available GPU memory. Efficient deployment requires:
- Expert Offloading: Storing experts in CPU memory or even disk
- Dynamic Loading: Moving experts to GPU only when needed
- Caching Mechanisms: Retaining frequently used experts in high-speed memory
- Batch Scheduling: Grouping similar inputs to minimize expert swapping
5.2 Quantization for MoE
Parameter reduction techniques are particularly effective for MoE:
- Expert-specific Quantization: Different quantization precision for different experts
- Mixed Precision: Using lower precision for expert weights while maintaining higher precision for routing
- Post-Training Quantization: Methods like GPTQ specifically optimized for MoE structures
- Sparse Quantization: Exploiting both weight and activation sparsity for further compression
5.3 Inference Optimization Techniques
Several techniques can further optimize MoE inference:
- Batched Expert Execution: Processing tokens assigned to the same expert together
- Expert Pruning: Removing rarely used experts post-training
- Static Routing: Pre-computing routing decisions for common input patterns
- Speculative Execution: Predicting routing decisions to prefetch expert weights
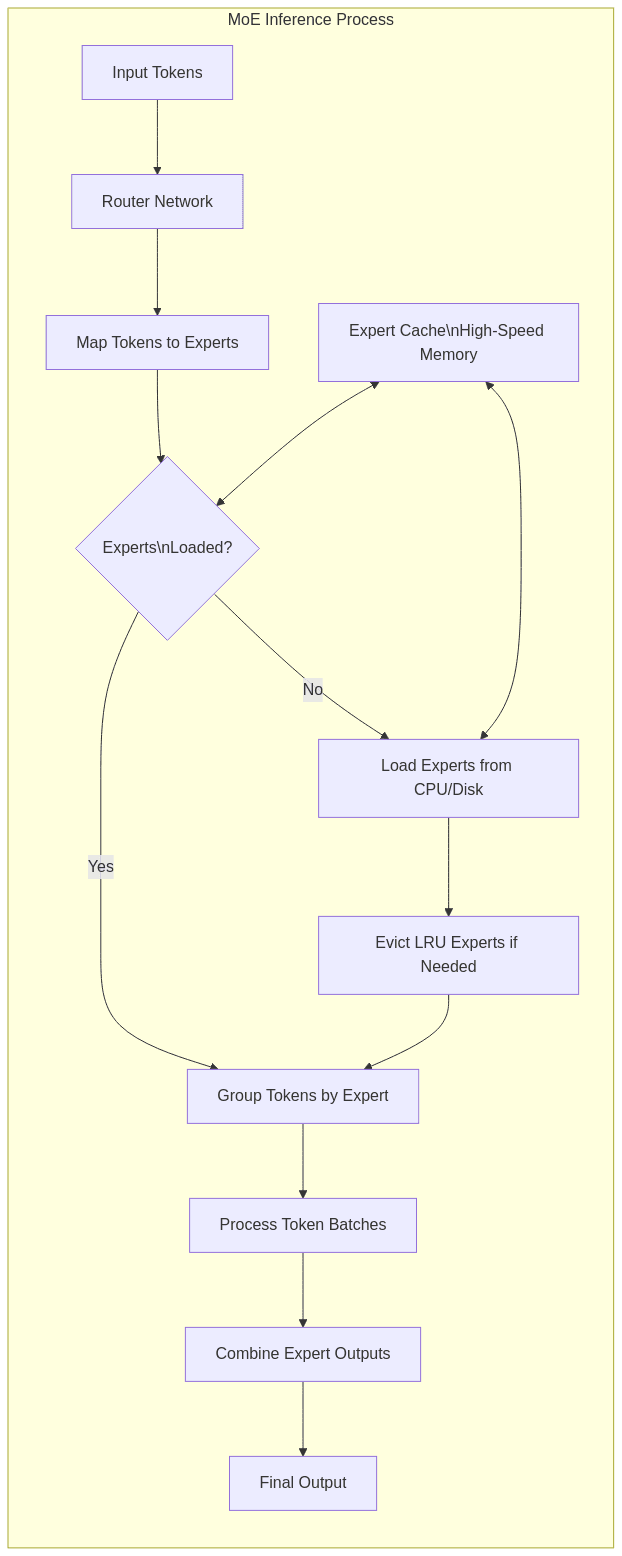
5.4 Deployment Architecture Example
class MoEInferenceEngine:
def __init__(self, router, experts, gpu_cache_size=4):
self.router = router
self.experts = experts # dictionary of expert_id -> expert parameters on CPU/disk
self.loaded_experts = {} # expert_id -> loaded model on GPU
self.expert_cache = LRUCache(max_size=gpu_cache_size)
def forward(self, token_embeddings):
# Get routing decisions
expert_indices, routing_weights = self.router(token_embeddings)
# Group tokens by assigned expert
expert_to_tokens = defaultdict(list)
token_to_original_idx = {}
for token_idx, expert_idx in enumerate(expert_indices):
expert_to_tokens[expert_idx.item()].append(token_idx)
token_to_original_idx[token_idx] = token_idx
# Process each expert batch
outputs = torch.zeros_like(token_embeddings)
for expert_idx, token_indices in expert_to_tokens.items():
# Load expert if needed
expert = self.expert_cache.get(expert_idx)
if expert is None:
expert = self._load_expert_to_gpu(expert_idx)
self.expert_cache.put(expert_idx, expert)
# Process batch for this expert
token_batch = token_embeddings[token_indices]
expert_outputs = expert(token_batch)
# Place outputs back in original positions
for i, orig_idx in enumerate(token_indices):
outputs[orig_idx] = expert_outputs[i]
return outputsThis implementation shows how tokens can be batched by expert assignment and processed efficiently with dynamic expert loading.
6. Real-World Impact: Successes and Challenges
MoE architectures have shown remarkable success across various domains, but also face unique challenges:
6.1 Success Stories and Benchmarks
- Language Generation: Models like Mixtral and Switch Transformer achieve SOTA results with fewer active parameters
- Multilingual Applications: MoE excels in multilingual settings where different experts naturally specialize in different languages
- Code Generation: Specialized experts significantly improve performance on programming tasks
- Multitask Learning: The natural specialization of experts enables strong performance across diverse task types
6.2 Production Challenges
The deployment of MoE at scale reveals several practical challenges:
- Runtime Variance: Token processing time can vary significantly depending on expert assignment
- Load Balancing During Inference: Popular experts can become bottlenecks
- Memory Management Complexity: Dynamic loading/unloading adds significant implementation complexity
- Batch Processing Efficiency: Varying expert activation patterns complicate efficient batching
6.3 Cost-Benefit Analysis
Organizations considering MoE must weigh several factors:
- Training vs. Inference Tradeoffs: MoE often trains faster but may have more complex inference
- Deployment Environment Constraints: Edge deployment may favor dense models despite MoE’s theoretical advantages
- Maintenance Complexity: MoE systems require more sophisticated monitoring and management
- Hardware Specialization: Custom hardware accelerators may offer different efficiency profiles for MoE
| Aspect | Dense Models | Mixture of Experts |
|---|---|---|
| Parameter Efficiency | All parameters used for every input | Only a fraction of parameters used per input |
| Computational Cost | Scales linearly with parameter count | Scales sub-linearly with parameter count |
| Training Speed | Slower for same parameter count | Faster for same parameter count |
| Memory Usage | More predictable | Can be optimized through expert offloading |
| Inference Complexity | Straightforward | Requires routing overhead and memory management |
| Hardware Requirements | Well-optimized on current hardware | Benefits from specialized hardware support |
| Scalability Ceiling | Limited by compute availability | Can scale to trillions of parameters |
| Deployment Flexibility | Easier to deploy | More complex deployment pipeline |
| Specialization | General knowledge across all parameters | Specialized knowledge in different experts |
| Implementation Complexity | Lower | Higher due to routing and load balancing |
7. Beyond Basic MoE: Advanced Research Directions
The field of MoE research continues to evolve rapidly:
7.1 Hierarchical Expertise
- Multi-level Routing: Adding hierarchy to the routing decision (e.g., first selecting a domain, then an expert within that domain)
- Expert Clusters: Grouping related experts to enable more efficient communication patterns
- Progressive Specialization: Starting with general experts that gradually specialize during training

7.2 Dynamic Expert Architectures
- Expert Growth: Adding new experts during training when existing ones saturate
- Expert Merging: Combining redundant experts to improve efficiency
- Architecture Search for Experts: Automatically discovering optimal expert network structures
- Heterogeneous Experts: Using different architectures for different experts based on their specialization
7.3 Hybrid Approaches
- MoE + LoRA: Combining parameter-efficient fine-tuning with expert specialization
- MoE + Retrieval: Augmenting expert computation with retrieved information
- Adaptive Computation Time: Dynamically adjusting the number of experts based on input complexity
- MoE + Reinforcement Learning: Using RL to optimize routing decisions
7.4 Distillation and Compression
- Expert Distillation: Transferring knowledge from MoE models to smaller dense models
- Selective Distillation: Creating task-specific models from generalist MoE systems
- Routing Knowledge Transfer: Preserving routing decisions in compressed models
- Expert Pruning: Systematically removing redundant or underutilized experts
8. Ethical Considerations and Limitations
As with any powerful AI technique, MoE raises important ethical considerations:
8.1 Fairness and Bias
- Expert Specialization Bias: Experts may develop uneven capabilities across different demographics or languages
- Routing Bias: Routers might systematically direct certain types of inputs to specific experts
- Representation Imbalance: Popular domains may receive more expert capacity than niche ones
- Evaluation Challenges: Standard benchmarks may not detect domain-specific performance disparities
8.2 Environmental Impact
- Training Efficiency: While MoE improves computational efficiency, the push toward larger models may still increase overall energy consumption
- Hardware Requirements: Specialized hardware for MoE deployment may have significant manufacturing footprints
- Life Cycle Assessment: The environmental impact across the full lifecycle of MoE models requires careful evaluation
8.3 Technical Limitations
- Catastrophic Forgetting: Specialized experts may be more vulnerable to forgetting when retrained
- Robustness Concerns: Expert specialization may create specific vulnerability patterns
- Generalization Challenges: Over-specialization can potentially limit cross-domain generalization
- Explainability Issues: The routing decisions add another layer of complexity to model interpretation
Conclusion: The Future of Scalable AI
Mixture of Experts represents a fundamental shift in how we approach neural network scaling. By moving from a paradigm where every input traverses the same parameters to one where computation is conditionally routed through specialized pathways, MoE offers a middle ground between the specialized efficiency of smaller models and the generalist capabilities of massive ones.
As hardware, software frameworks, and algorithmic innovations continue to evolve, we can expect MoE architectures to play an increasingly central role in large-scale AI systems. The next generation of MoE models will likely feature:
- More sophisticated routing algorithms that better balance specialization with generalization
- Efficient deployment solutions that minimize the operational complexity of MoE systems
- Novel applications that leverage expert specialization for domain-specific tasks
- Integration with other efficiency techniques like quantization, distillation, and sparse attention
By intelligently routing computation through specialized experts, MoE points toward a future where AI systems can continue to scale in capability without proportionally increasing their computational demands—a critical consideration as we push the boundaries of what’s possible with artificial intelligence.
Further Reading and Resources
- Papers:
- Implementations:
- Blogs and Tutorials:
By carefully implementing and tuning an MoE approach—alongside complementary techniques like quantization, distillation, and efficient routing—researchers and engineers can build AI systems that effectively balance the competing demands of model capacity, computational efficiency, and performance across diverse tasks.