Key Takeaways
- Zero-shot is the acid test. For discriminative tasks like MMLU, it delivers nearly identical accuracy to N-shot while halving evaluation latency. The extra examples are often just expensive noise.
- N-shot is a tax on time and tokens. It bloats prompts and inflates wall-clock time for marginal, if any, accuracy gains on non-generative tasks.
- Generative tasks are the exception. For benchmarks like MATH that need structured output, a single, well-chosen example is non-negotiable. It’s not about teaching the model to think, but teaching it the grammar of the expected answer.
- Reproducibility is born from simplicity. Zero-shot has fewer moving parts. Fewer cherry-picked examples means less variance, cleaner experiments, and more honest results.
Why Speed & Reproducibility Matter
We’ve graduated from academic tinkering to industrial-scale model development. The game is no longer about a handful of researchers running a single script; it’s about production-grade model farms where a single evaluation sweep across dozens of benchmarks burns millions of tokens and stretches CI pipelines to their breaking point. When you’re iterating on checkpoints or alignment techniques daily, latency is the enemy. Brittle, over-engineered prompts are the friction that grinds progress to a halt.
The lowest-hanging fruit isn’t a new optimizer; it’s operational efficiency.
I recently revisited my own evaluation harness with a simple, almost heretical question:
Do I really need those five in-context examples for MMLU?
The answer, it turns out, is a resounding no. Here’s the data, and a framework for cutting the fat from your own pipeline.
Zero-, One- and N‑shot in One Minute
Side-note: I call the k-example regime N-shot-a nod to this blog’s own philosophy of hitting the target on the first try.
| Setting | What the prompt contains | Typical usage |
|---|---|---|
| Zero‑shot | Only the task query | The honest baseline; discriminative tasks |
| One‑shot | One worked example | Format priming; teaching the output grammar |
| N‑shot (k > 1) | k Q‑A pairs before the query | High-stakes generative tasks where one example is not enough |
My rule: keep k ≤ 1 unless you have overwhelming, empirical evidence that more examples move the needle.
Experimental Setup
from lm_eval import evaluator, tasks, models
model = models.get_model("hf", pretrained="Qwen/Qwen2_1_5B")
task_list = ["mmlu", "math_hard"]
# Zero‑shot evaluation
results_zero = evaluator.simple_evaluate(
model=model,
task_list=task_list,
num_fewshot=0,
)
# Five‑shot (MMLU default)
results_five = evaluator.simple_evaluate(
model=model,
task_list=task_list,
num_fewshot=5,
)All runs were executed on a single A100 80 GB with vLLM serving in greedy mode. The harness version is the October 2024 commit of EleutherAI/lm‑evaluation‑harness.
Accuracy
| Task | Zero‑shot | One‑shot | Five‑shot |
|---|---|---|---|
| MMLU | ≈ 47 % | 47–48 % | 48 % |
| MATH (Hard) | 0 % | 4 % | 8 % |
The takeaway for MMLU is stark: the score barely flinches. We’re burning tokens for a single percentage point of uplift, a gain that’s well within the noise margin of a rerun.
MATH, in contrast, is a different beast. It jumps from a flat zero to non-trivial accuracy once it sees a single example. Here, the shot isn’t just helpful; it’s essential for teaching the model the required output grammar. The zero-shot model simply doesn’t know to produce the Final Answer: <value> string the parser is looking for.
Evaluation Latency
| Task | Zero‑shot | Five‑shot |
|---|---|---|
| MMLU | 1× | 2× |
| MATH (Hard) | 1× | 0.8× |
Counter-intuitively, the evaluation for MATH even speeds up. The N-shot template forces the model to be terse, preventing it from rambling through a long chain-of-thought and hitting the generation token limit. It’s a clear case of constraint breeding efficiency.
A Mental Model for Choosing k
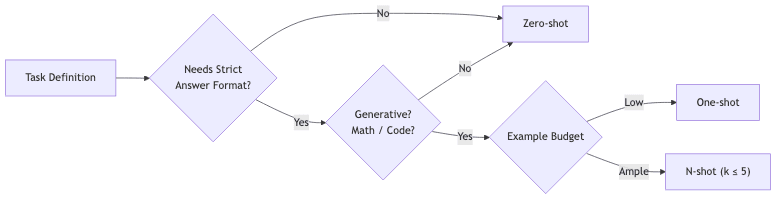
- If the benchmark is a multiple-choice exam scoring log-probabilities of fixed answers (MMLU, ARC, HellaSwag), go zero-shot. You’re testing reasoning, not format mimicry.
- If the benchmark relies on parsing generated text (MATH, HumanEval), you need at least one shot to provide the required output structure.
- Stop adding shots the moment the accuracy gains flatten or your context window starts to groan. Anything more is computational vanity.
Reproducibility First
N-shot introduces a dirty variable: selection variance. Change one example in your prompt, and your headline metric can swing by a few points. This is the art-and-craft part of benchmarking that has no place in rigorous science. While harnesses like lm-eval mitigate this by hard-coding exemplars for some tasks, many published papers conveniently omit their exact shot selection process.
Unless you are prepared to open-source every character of your prompt, zero-shot is the only honest baseline for claims that need to be bullet-proof. It replaces craft with rigor.
Practical Checklist
| 🔍 Question | Action |
|---|---|
| Multiple-choice task? | Use zero-shot. Period. |
| Chasing a leaderboard? | Re-use their shots verbatim for comparability. No creativity needed. |
| Iterating fast? | Default to zero-shot. Only add shots if accuracy is unacceptably low. |
| Need a parseable output? | Use one high-quality shot to show the format. |
Conclusion
In 2024, there is no reason to blindly pay the N-shot tax. It’s a holdover from an era of less capable models and less disciplined engineering. Zero-shot should be your default. It is faster, cleaner, and more honest. N-shot is a tactical lever, to be pulled only when absolutely necessary-primarily for generative tasks that need to be taught a specific output grammar.