1. Defining Perplexity: An Intuitive Approach
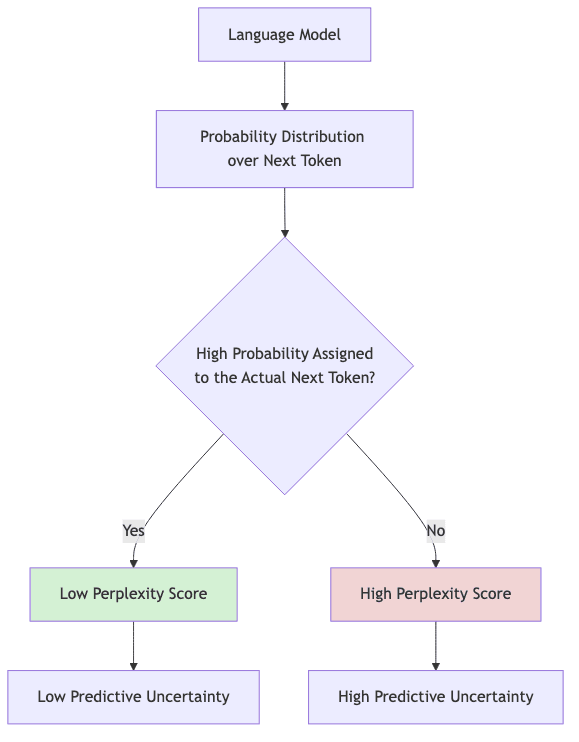
- The Guessing Game Analogy Imagine you’re forced to play a game: predict the next word in a sentence, over and over. If you’re any good, you won’t need to consider every word in the dictionary for each slot. Perplexity quantifies this intuitive idea—it represents the effective branching factor the model faces at each decision point. A perplexity of 10 means the model is, on average, as uncertain as if it were choosing uniformly from 10 possibilities. Fewer effective choices imply a better grasp of the language’s structure.
- The Confidence Connection When a language model assigns high probability to the correct next word (the one that actually appears in the text), it’s exhibiting confidence. Perplexity flips this around: lower perplexity equates to higher confidence, reflecting a better underlying language model. It’s not just confidence; it’s a lack of crippling uncertainty.
- Why “Perplexity”? The name itself is apt. It captures the model’s state of being “confused” or “puzzled” by the input text. A model scoring low perplexity rarely finds itself bewildered by the sequence—it anticipates, having learned the patterns, the clichés, the grammatical constraints, the flow of the language.
2. Mathematical Formulation: Under the Hood
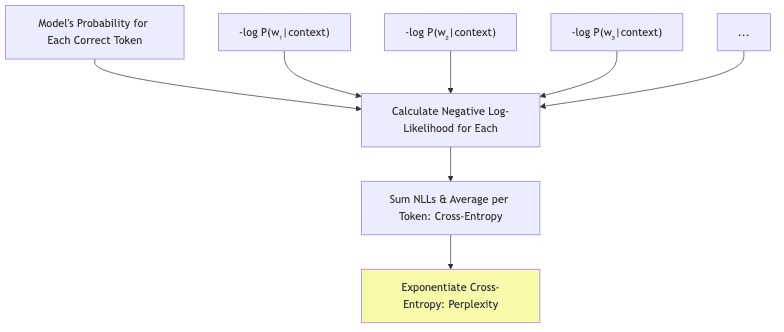
Behind the intuition lies the unforgiving math, rooted firmly in information theory. If you’re comfortable with symbols, here’s the essence: For a sequence of tokens- Negative Log-Likelihood (NLL) First, sum the negative logarithms of the probabilities the model assigned to each correct token in the sequence. This is the total “surprise” or NLL:
A higher NLL means the model found the actual sequence more improbable (more surprising).
- From NLL to Cross-Entropy Average this total surprise over the number of tokens, N. This gives the average negative log-likelihood per token, which is equivalent to the cross-entropy between the empirical distribution of the data and the model’s predictions:
- From Cross-Entropy to Perplexity Finally, exponentiate the cross-entropy. This transforms the average log probability back into the “per-token probability space”:
3. Example Calculation: Perplexity in Action
Let’s ground this with a toy example. Our hyper-simplified model sees the sequence “language model”.- Probability assigned to “language” (first word):
- Probability assigned to “model” given “language”:
 Compare this:
Compare this:
- A perfect model (assigns probability 1.0 to correct tokens): Perplexity = 1.0 (the theoretical floor).
- A model guessing uniformly from a 100-word vocabulary: Perplexity = 100 (the ceiling of pure ignorance for that vocab size).
- Modern LLMs on diverse text: Perplexities often range from ~10 to ~30, sometimes lower on specific domains or with very large models.
4. Why Perplexity Matters: Applications and Importance
So, why bother tracking this number? It turns out to be pragmatically useful in several ways, especially for the engineers building these things:- Training Signal: It’s the loss function’s close cousin. Minimizing cross-entropy (and thus perplexity) is often the direct optimization objective during training. Watching perplexity drop tells you the model is learning something about language structure.
- Model Comparison and Benchmarking: It provides a standardized ruler. Given the same dataset and tokenization, comparing perplexity scores gives a rough measure of which model has a better statistical grasp of the language. It’s the classic way to claim your architecture is better than the last guy’s.
- Domain Adaptation Assessment: It’s a reality check for generalization. Train a model on news, test it on legal documents—if perplexity skyrockets, the model hasn’t bridged the domain gap.
- Data Quality Indicator: It can be an early warning system. If perplexity on validation data suddenly jumps during training or monitoring, it might signal data corruption, distribution shift, or other pipeline issues.
- Efficiency Evaluation: It helps assess bang for buck (or FLOP). Comparing perplexity against model size (parameters) or compute cost offers insight into modeling efficiency. How much predictive power do you gain per unit of resource?
| Application | Role of Perplexity | Example Scenario |
|---|---|---|
| Training | Optimization Target | Monitoring the perplexity curve descent during model training |
| Benchmarking | Comparison Metric | Comparing perplexity of Model X vs. Model Y on WikiText-103 |
| Domain Adaptation | Transfer Quality Check | Measuring perplexity jump when applying a web-trained model to code |
| Monitoring | System Health Indicator | Alerting when production perplexity unexpectedly degrades |
| Model Efficiency | Cost-Benefit Analysis | Plotting perplexity vs. parameter count across model scales |
5. Recent Advancements and Considerations
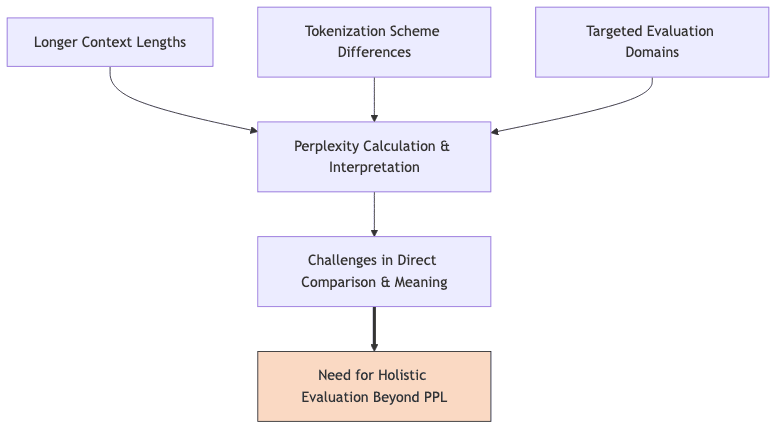
The game has changed with massive models and context windows, adding layers of complexity to interpreting perplexity:- Context Length Dynamics: LLMs now ingest contexts stretching to millions of tokens. Calculating perplexity reliably requires careful handling of these long sequences (often via sliding windows). Interestingly, perplexity typically decreases as context length grows, confirming that more context helps prediction, up to a point.
- The Perplexity-Performance Gap: This is the elephant in the room. While lower perplexity generally correlates with better performance on downstream tasks (like question answering or summarization), the link isn’t perfect. Two models with identical perplexity can have vastly different reasoning abilities or factual recall. Perplexity is necessary, but far from sufficient.
- Perplexity and Hallucination: The smooth talker problem. A model might generate fluent, plausible-sounding text (low perplexity) that is completely fabricated. Low perplexity doesn’t prevent hallucination; sometimes, it might even enable confident falsehoods. This necessitates separate fact-checking mechanisms.
- Specialized Evaluation Contexts: Measuring perplexity on broad corpora gives an average. Increasingly, researchers probe specific weaknesses by measuring perplexity on targeted datasets—mathematical proofs, rare historical facts, ambiguous sentences—to get a more granular view of capabilities.
- Tokenization Effects: Comparing perplexity across models using different tokenizers (e.g., BPE vs. WordPiece vs. SentencePiece, with different vocab sizes) is notoriously tricky. A model breaking words into smaller units naturally faces an easier prediction task per token, affecting the raw perplexity score independently of true language understanding. Apples and tokenized oranges.
- Beyond Average Perplexity: The average perplexity hides the distribution. Does the model excel on common phrases but fall apart on rare words? Analyzing perplexity variance or focusing on high-perplexity tokens can reveal more about model robustness and failure modes.
6. Code Example: Computing Perplexity in Practice
Theory is fine, code is better. Here’s a conceptual look at calculating perplexity using PyTorch, first with a toy model, then with a real one.import torch
import torch.nn as nn
import math
# Simplified setup
vocab_size = 20
embedding_dim = 8
hidden_dim = 16
class ToyLanguageModel(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim):
super(ToyLanguageModel, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.rnn = nn.RNN(embedding_dim, hidden_dim, batch_first=True)
self.fc = nn.Linear(hidden_dim, vocab_size)
def forward(self, x, hidden=None):
emb = self.embedding(x)
output, hidden = self.rnn(emb, hidden)
logits = self.fc(output) # shape: [batch, seq_len, vocab_size]
return logits, hidden
# Instantiate model and loss (summed NLL)
model = ToyLanguageModel(vocab_size, embedding_dim, hidden_dim)
# Use reduction='sum' to get total NLL before averaging
loss_fn = nn.CrossEntropyLoss(reduction='sum')
# --- Toy Example Calculation ---
# Input sequence (batch size = 1, sequence length = 3)
# Assume input indices are [2, 5, 10]
input_seq = torch.tensor([[2, 5, 10]])
# Target sequence (shifted by one)
# Assume target indices are [5, 10, 3]
target_seq = torch.tensor([[5, 10, 3]])
# Forward pass to get logits
logits, _ = model(input_seq) # Output shape: [1, 3, vocab_size]
# Reshape for CrossEntropyLoss which expects [N, C] input
logits_flat = logits.view(-1, vocab_size) # Shape: [3, vocab_size]
targets_flat = target_seq.view(-1) # Shape: [3]
# Calculate total negative log-likelihood (the loss value)
total_nll = loss_fn(logits_flat, targets_flat)
n_tokens = targets_flat.numel() # Number of tokens = 3
# Compute perplexity: exp(average NLL)
perplexity = math.exp(total_nll.item() / n_tokens)
print(f"Toy Model Perplexity: {perplexity:.4f}")- Model Output: Get logits (unnormalized scores) for each possible next token.
- Loss Calculation: Use Cross-Entropy loss, typically summing the NLL across tokens.
- Input/Target Shift: Ensure targets are the actual next tokens for the given inputs.
- Averaging and Exponentiation: Divide total NLL by the number of tokens, then exponentiate.
- Memory: For large models and long texts, compute loss in batches or use techniques like gradient checkpointing if calculating during training. For inference, process text in chunks.
- Tokenization: Be consistent. Perplexity is only comparable if calculated on the exact same text using the exact same tokenizer. Normalizing by words instead of tokens is sometimes done for subword models, but adds complexity.
- Numerical Stability: Calculations are often done in log-space until the final exponentiation to avoid underflow/overflow issues with tiny probabilities.
- Padding: Ensure padding tokens are ignored in the loss calculation.
CrossEntropyLossoften has anignore_indexparameter for this.
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
import math
# Load a pre-trained model and tokenizer
model_name = "gpt2" # Example: replace with your model
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
model.eval() # Set model to evaluation mode (disables dropout, etc.)
device = "cuda" if torch.cuda.is_available() else "cpu"
model.to(device)
# Text to evaluate
text = "Perplexity measures how well a probability model predicts a sample."
encodings = tokenizer(text, return_tensors="pt").to(device)
input_ids = encodings.input_ids
# --- Method 1: Using Model's Built-in Loss Calculation ---
# When labels are provided, HF models often return the cross-entropy loss directly
with torch.no_grad(): # Disable gradient calculations for inference
outputs = model(input_ids=input_ids, labels=input_ids)
# The loss returned is the *average* NLL per token
avg_nll = outputs.loss.item()
perplexity_hf_loss = math.exp(avg_nll)
print(f"Perplexity (from HF loss): {perplexity_hf_loss:.4f}")
# --- Method 2: Manual Calculation (Chunking for Long Texts) ---
# Useful for very long texts that don't fit in memory
def calculate_perplexity_chunked(model, tokenizer, text, max_length=1024, stride=512):
encodings = tokenizer(text, return_tensors="pt")
all_ids = encodings.input_ids[0] # Get the tensor of token IDs
total_nll = 0.0
total_tokens = 0
for i in range(0, all_ids.size(0), stride):
begin_loc = max(i + stride - max_length, 0)
end_loc = min(i + stride, all_ids.size(0))
trg_len = end_loc - i # may be different from stride on last loop
input_ids_chunk = all_ids[begin_loc:end_loc].unsqueeze(0).to(device)
target_ids_chunk = input_ids_chunk.clone()
# For causal LM, targets are usually the same as inputs, loss calculation handles shift
# We mask out the context part for loss calculation
target_ids_chunk[:, :-trg_len] = -100 # -100 is the default ignore_index for CrossEntropyLoss
with torch.no_grad():
outputs = model(input_ids_chunk, labels=target_ids_chunk)
# outputs.loss is already the average NLL for the *valid* target tokens
log_likelihood = outputs.loss * trg_len # Reconstruct total NLL for the chunk
total_nll += log_likelihood.item()
total_tokens += trg_len
if total_tokens == 0: return float('inf') # Avoid division by zero
perplexity = math.exp(total_nll / total_tokens)
return perplexity
# Example usage for long text (replace with actual long text)
# long_text = "..." * 1000
# perplexity_chunked = calculate_perplexity_chunked(model, tokenizer, long_text)
# print(f"Perplexity (Chunked): {perplexity_chunked:.4f}")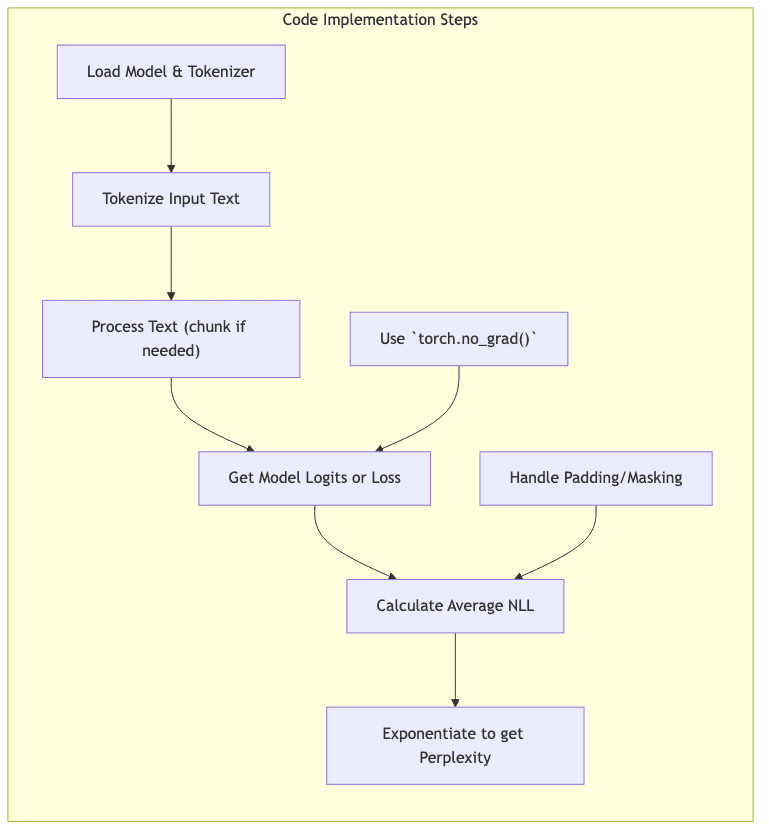
7. Beyond Perplexity: The Broader Evaluation Landscape
Perplexity is foundational, but it’s not the whole game. Evaluating modern LLMs requires a multi-pronged approach, looking beyond statistical fit to actual utility and safety:- Task-Specific Benchmarks: Can the model do useful things? Suites like GLUE, SuperGLUE, MMLU, and BIG-bench test capabilities ranging from natural language inference to common sense reasoning and complex instruction following. Performance here often matters more than raw PPL.
- Factual Accuracy: Is the model constantly making things up? Metrics and datasets like TruthfulQA try to quantify reliability and the tendency to generate plausible-sounding misinformation (hallucinations).
- Robustness Evaluations: How easily does the model break? Testing performance against adversarial inputs, out-of-distribution data, or ambiguous prompts reveals brittleness.
- Human Preferences: Does the output feel right to a human? Reinforcement Learning from Human Feedback (RLHF) explicitly optimizes models based on human judgments of helpfulness, harmlessness, and honesty—qualities perplexity doesn’t directly capture.
- Generation Quality: Is the generated text actually good? Metrics assessing coherence, diversity, avoiding repetition, and adhering to specific styles are crucial for generative applications.

8. Conclusion: The Enduring Value of Perplexity
Through multiple revolutions in NLP—from n-grams fighting for scraps of probability mass to gargantuan transformers commanding petaflops—perplexity has endured. Its virtue lies in its direct, interpretable link to the model’s fundamental task: predicting the next token. It measures the irreducible uncertainty the model faces when confronted with language. As models become more complex and their applications more ambitious, perplexity alone is clearly insufficient. We need the full suite of task benchmarks, safety checks, and human evaluations to understand what we’ve truly built. Yet, dismissing perplexity entirely would be a mistake. It remains a vital diagnostic during development, a sanity check on training progress, and a core indicator of how well a model has internalized the statistical essence of the data it consumed. So, the next time you see a paper boasting a new state-of-the-art perplexity score, you’ll know what it signifies: a better statistical model of language, likely more confident in its predictions. You’ll also know the crucial follow-up questions: Does that improved prediction translate to better reasoning? Is it more truthful? Is it safer? More useful? Knowing how surprised your model is by the world remains a damn good starting point, but it’s only the beginning of the story.Further Reading & Resources
- Information Theory, Inference, and Learning Algorithms by David MacKay (For the theoretical underpinnings)
- Stanford CS224N: Natural Language Processing with Deep Learning (Lecture notes often cover perplexity)
- Hugging Face Transformers Documentation (For practical implementation details)
- On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? (Discusses limitations of metrics like perplexity)
- HELM: Holistic Evaluation of Language Models (An example of a broad evaluation framework)