Introduction
AI gallops ahead, leaving a tangled mess of data questions and legal tripwires in its wake. Forget “responsible data usage” as a platitude; survival for anyone building or deploying these systems—from tech behemoths to scrappy startups and academics—demands grappling with actual legal compliance. The landscape is a constantly shifting patchwork of legislation, precedent, and often contradictory best practices governing how data is scraped, stored, processed, and ultimately used to train and deploy models.
It’s about understanding the fundamental tensions between innovation, privacy, intellectual property, and societal impact. This guide dissects the key battlegrounds at the intersection of AI, data governance, and law, offering a pragmatic look at the frameworks and necessary defenses for building AI in the real world.
1. The Global Regulatory Maze: A Fragmented Reality
Forget a unified rulebook. The international regulatory environment for AI and data is a chaotic quilt, stitched together from wildly different philosophies and priorities. Navigating this requires understanding the distinct hazards of each territory:

United States
- The Fair Use Gamble: The bedrock for many LLMs scraping the public web. “Fair use” is invoked, often aggressively, but it’s a notoriously fuzzy doctrine now facing serious court challenges. Relying on it feels increasingly like betting the company on a legal coin flip.
- Sectoral Patchwork: No grand AI law here. Instead, a tangle of domain-specific rules: HIPAA for health data (don’t mess this up), COPPA for kids’ data (seriously, don’t mess this up), FCRA for credit info. Compliance means juggling multiple, sometimes overlapping, requirements.
- State-Level Chaos: California (CCPA/CPRA), Colorado, Virginia, and others are writing their own privacy rules, creating a compliance nightmare for anyone operating across state lines. Fifty different shades of regulation.
European Union (EU)
-
GDPR’s Long Shadow: The heavyweight champion of data protection. Forget nuance; GDPR demands:
- Explicit consent or clear legal basis. Ambiguity is your enemy.
- Data minimization: Use only what you need. Hoarding is dangerous.
- Right to explanation for AI decisions (good luck implementing that meaningfully).
- Penalties are real and painful: up to 4% of global annual revenue. Enough to make CFOs weep.
-
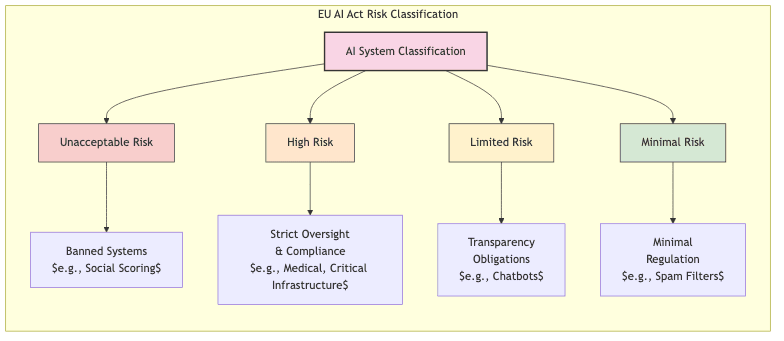
The AI Act Ambition: A landmark attempt to categorize AI by risk, essentially creating a tiered system of bureaucratic hoops:
- Unacceptable risk: Banned outright. Think social scoring by governments.
- High risk: Drowning in compliance burdens. Think critical infrastructure, medical devices.
- Limited risk: Transparency required. Think chatbots disclosing they aren’t human.
- Minimal risk: Mostly left alone. Think spam filters.
For LLMs, this means forced transparency about training data (potentially revealing proprietary sources or legally dubious scraping) and vague constraints on outputs. A lawyer’s full employment act in the making.
United Kingdom
- Adrift post-Brexit, the UK mirrors GDPR mostly, but talks a big game about being “innovation-friendly” (read: potentially lighter touch, TBD).
- Their National AI Strategy carves out specific text/data mining exceptions for research, but commercial use quickly bumps into licensing walls.
China
- PIPL: China’s GDPR equivalent, but interwoven with state security objectives. Data is personal but it’s also potentially strategic.
- Targeted AI Rules: Ahead of the curve in regulating specific applications like recommendation algorithms and deepfakes – reflecting state priorities.
- Data Security Law: Strict rules on data classification and, crucially, cross-border transfers. Training global models on Chinese data? Prepare for pain.
Japan
- Tends towards government-industry hand-holding (“collaboration”) for AI development.
- APPI handles personal data, but the overall vibe is less adversarial than the EU or US litigiousness.
- “Society 5.0” initiatives try to balance tech optimism with ethics, but the practical impact remains to be seen.
Australia
- “Fair dealing” offers less wiggle room than US “fair use” for using copyrighted works.
- The Privacy Act governs personal data use.
- Courts are starting to grapple with AI output liability, adding uncertainty.
| Region | Key Regulations / Doctrines | Approach to AI | Typical Penalties / Risks |
|---|---|---|---|
| United States | Fair Use (Contested), HIPAA, COPPA, FCRA, State Laws | Sector-specific, Litigious | Varies wildly, potentially huge lawsuits |
| European Union | GDPR, AI Act | Comprehensive, Risk-Based Bureaucracy | Up to 4% global revenue, operational limits |
| United Kingdom | UK GDPR, National AI Strategy | “Innovation-friendly” (aspirational) | Similar to EU, evolving |
| China | PIPL, Data Security Law, Specific AI Rules | State Control, National Security Focus | Severe fines, business suspension, data localization mandates |
| Japan | APPI, Society 5.0 | Collaborative, Less Adversarial | Administrative orders, fines |
| Australia | Privacy Act, Fair Dealing (Narrow) | Case-by-case, Evolving Case Law | Civil penalties, reputational damage |
2. The Original Sin: Data Sourcing and Licensing
Where your data comes from dictates the legal radioactivity of your AI. This isn’t just about quantity; it’s about provenance and permission. Get this wrong, and everything downstream is tainted.
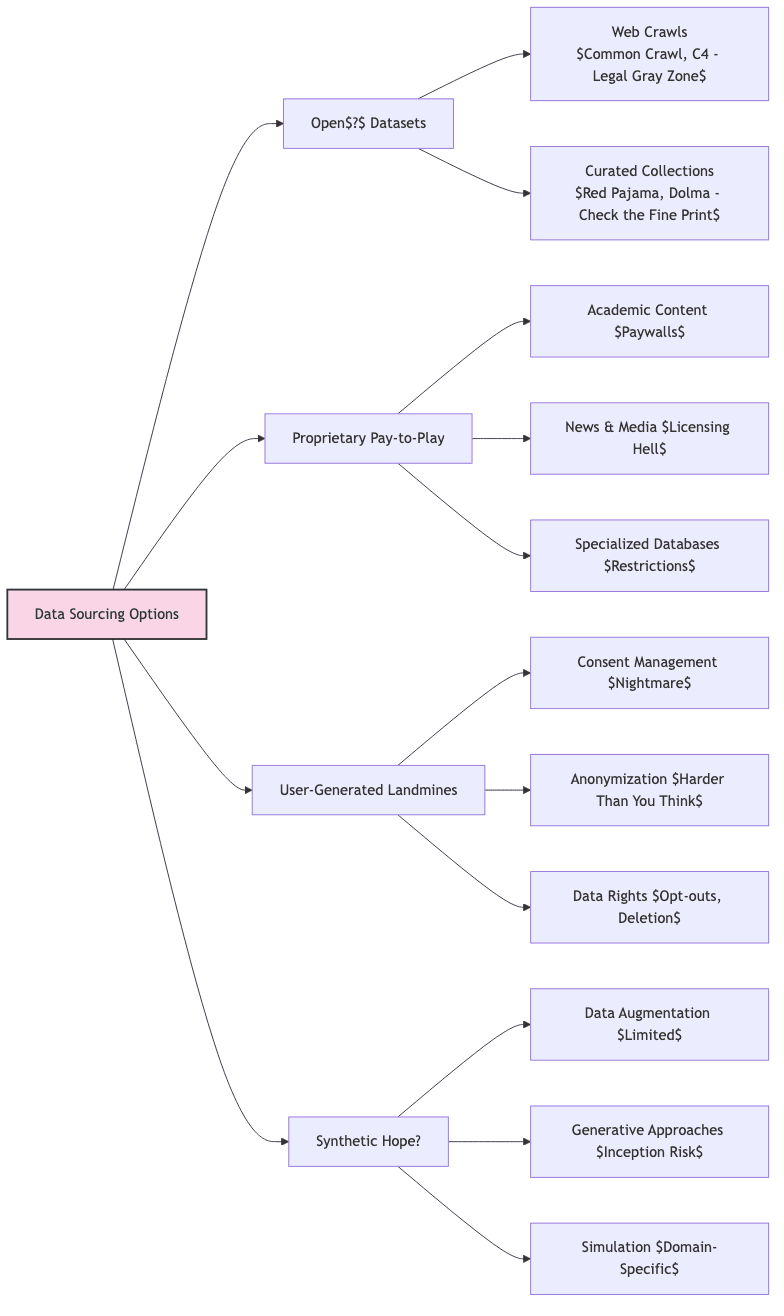
Open(?) Datasets
- Web Crawl Repositories:
- Common Crawl: The internet’s messy attic, scraped wholesale. Widely used, legally dubious foundation for many LLMs. Contains everything, including copyrighted material, personal data, and toxic sludge.
- C4: Google’s attempt to clean the Common Crawl stables. Better, but still inherits the original sin of the crawl.
- Curated Collections:
- Red Pajama, Dolma, Refined Web: Attempts to build “cleaner” datasets, often by replicating or filtering existing ones. Noble goal, but always dependent on the underlying source licenses.
- License Necromancy: Don’t skim the licenses. CC-BY is golden. Anything else (CC-NC, CC-SA, custom licenses) imposes potentially fatal restrictions on commercial use or model sharing. Assume nothing is truly “open” without verification.
Proprietary and Subscription Sources
- Academic/Scientific Content: Publishers guard this fiercely. Using Elsevier or JSTOR for training requires explicit, often expensive, licenses.
- News and Media: Want to train on news archives? Get ready to pay licensing fees and navigate complex restrictions on how derived models can be used (e.g., no competing news generation).
- The Terms of Service Trap: Scour the ToS of any data provider. Many explicitly forbid “machine learning,” “data mining,” or “automated processing.” Violate these at your peril.
User-Generated Landmines
- Consent Theater: Your privacy policy must explicitly mention AI training if you use user data. Getting meaningful, informed consent is hard. Tracking it is harder.
- Data Rights Management: You need systems to honor opt-outs and deletion requests (the “right to be forgotten”). This isn’t optional under GDPR and similar laws.
- Anonymization’s False Promise: Truly anonymizing rich user data is incredibly difficult. Naive approaches (stripping names/emails) often fail, leaving re-identification possible. Robust anonymization requires expertise and careful validation.
Synthetic Data: The Hopeful Alternative?
- Data Augmentation: Useful for beefing up small datasets, but doesn’t solve the core problem if your seed data is flawed.
- Generative Approaches: Using AI to generate training data. Reduces reliance on risky sources, but risks model “inbreeding” or inheriting biases from the generator model.
- Simulation: Powerful for specific domains (robotics, finance) where realistic environments can be modeled. Generates clean, controllable data, but applicability is limited.
ETL (Extract, Transform, Load) – The Unsung Plumbing
- Specialized Tools: Frameworks like
unstructuredhelp parse messy real-world data while trying to implement safeguards. Essential for dealing with diverse formats. - Data Laundering Pipelines: Robust processes are for removing sensitive PII, filtering toxic content, and attempting to mitigate bias. This is non-trivial engineering.
- Provenance is Everything: Keep meticulous records of where data came from, how it was transformed, and what got filtered out. When the lawyers or regulators come knocking, you’ll need this audit trail.
3. The Downstream Mess: Model Deployment and Usage Risks
Getting the data legally is just the start. How your model behaves in the wild opens a whole new Pandora’s Box of legal and ethical risks.
Bias, Fairness, and the Specter of Discrimination
- Garbage In, Garbage Out, Discrimination Lawsuit: Models trained on biased data will produce biased outputs. It is bad for PR (ask Google!) but it can also violate anti-discrimination and civil rights laws.
- Audit Relentlessly: Don’t just test on benchmarks. Use diverse, adversarial prompts. Probe for biases against protected characteristics. This needs to be ongoing.
- Frameworks for Defense: Use tools to document and measure fairness, not as a cure-all, but as evidence of due diligence:
- OpenAI’s
evals - Hugging Face Model Cards
- Google Model Cards Toolkit
- Microsoft Responsible AI Dashboard
- OpenAI’s
Privacy Leaks and Model Memorization
- The Blabbing Model: LLMs can, and do, memorize chunks of their training data, including sensitive personal information. A seemingly innocuous prompt can trigger regurgitation.
- Damage Control Strategies:
- Differential Privacy: Add mathematical noise during training to limit memorization. A formal guarantee, but often comes at a steep cost to utility. The privacy budget ε is the knob controlling this trade-off.
- Model Distillation: Train smaller models that are less likely to overfit and memorize specific examples.
- Prompt Filtering: Block prompts designed to extract training data. An arms race.
- Output Filtering: Scan model outputs for PII or known sensitive patterns before showing the user. Imperfect.
Differential privacy aims to ensure the output distribution doesn’t change much if one individual’s data is added or removed:
Where is the algorithm,
are datasets differing by one record,
is any output set, and
is the privacy budget (smaller
= more privacy, less utility).
Explainability Theater vs. Accountability
- “Show Your Work” Demands: GDPR and the upcoming AI Act demand explanations for AI decisions, especially high-stakes ones.
- Retrofitting Transparency: Techniques trying to make black boxes interpretable:
- Chain of Thought (CoT): Forcing the model to “think step-by-step.” Can be brittle.
- Retrieval-Augmented Generation (RAG): Grounding answers in specific documents. Better, but relies on the quality of the retrieval and the source documents.
- Reason + Act (ReAct): Logging the model’s internal reasoning and external actions. Useful for debugging, maybe for regulators.
- Documentation as Defense: Consistent logging and clear (even if simplified) explanations are crucial for demonstrating process, even if true “explainability” remains elusive.
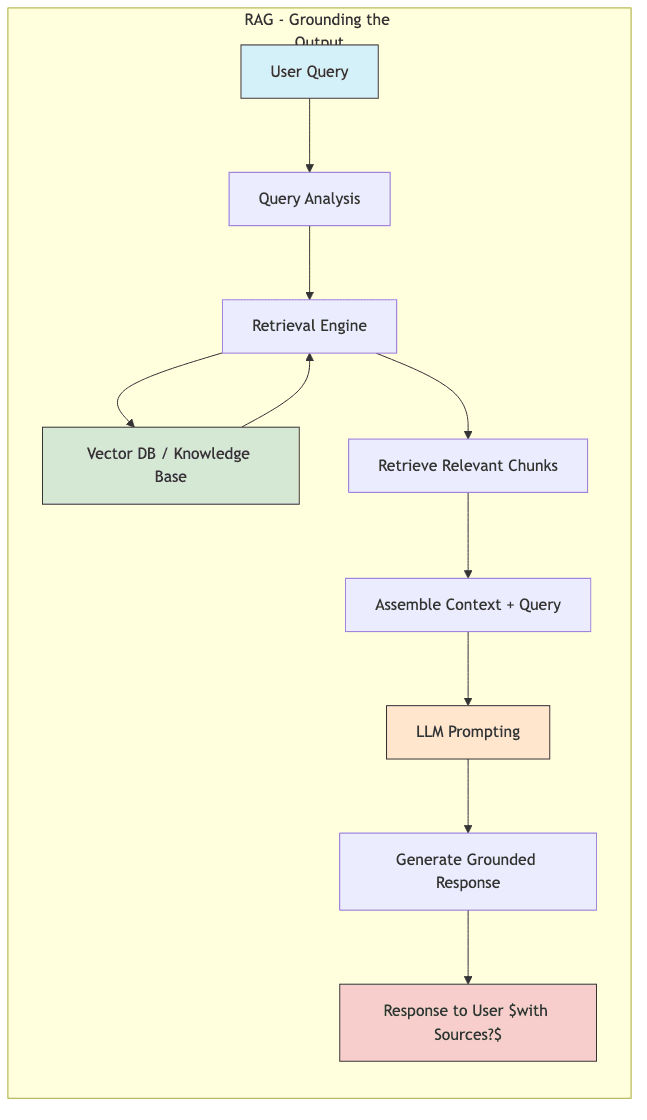
The Copyright Boomerang
- Infringing Outputs: Models trained on copyrighted data might generate outputs substantially similar to protected works. This is the core of several major lawsuits.
- Watermarking Hopes: Technical efforts to invisibly mark AI content exist, but effectiveness and adoption are uncertain. Detection is hard.
- Who Pays the Piper?: Is the model provider liable? The company deploying it? The end-user prompting it? The law is still figuring this out, jurisdiction by jurisdiction. Assume liability could splash onto you.
Safety, Harm, and Unintended Consequences
- Content Moderation is Non-Negotiable: You need robust filters and moderation systems to block harmful, illegal, or abusive outputs. This is complex and requires constant updating.
- Dual-Use Nightmares: How could your benevolent AI be twisted for malicious purposes? Think about potential misuse and build in guardrails (even if imperfect).
- When Things Go Wrong: Have a plan. How do you handle reports of harmful outputs? How do you update the model? How do you communicate failures?
4. Practical Armor: How Not to Get Sued (Immediately)
Theory is nice. Survival requires practical defenses. Build your compliance framework like you’re preparing for siege:
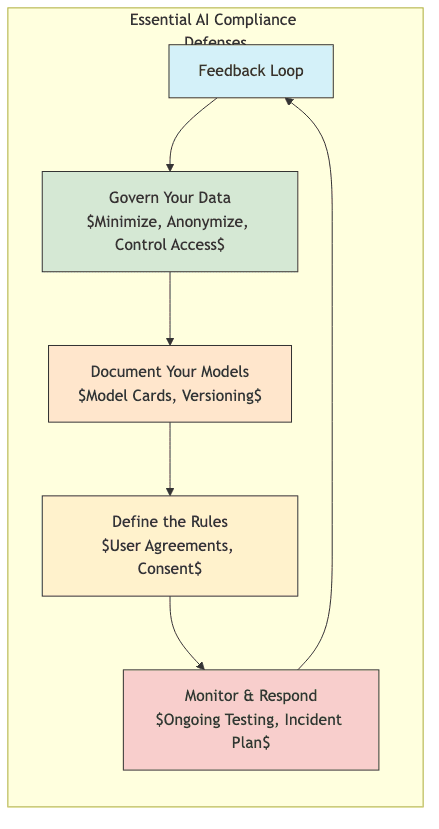
Conduct a Ruthless Data Inventory
- Source Forensics: Document every single data source used for training or fine-tuning. No exceptions. Where did it really come from?
- License Mapping & Auditing: Attach specific license terms to each source. Assess compatibility with your intended use. Identify conflicts before they become legal battles.
- Risk Triage: Categorize data sources by risk (e.g., public domain = low, scraped personal data = high, clearly licensed = medium). Focus mitigation efforts where the danger is greatest.
Implement Iron-Clad Data Governance
- Data Minimization Habit: Collect only what’s necessary. Retain it only as long as necessary. Data hoarding is a liability multiplier.
- Serious Anonymization Protocols: Make it more than just
strip names out. Use robust techniques:- Named entity recognition (NER) for PII detection.
- Regex for standard identifiers (emails, phone numbers, CC#s).
- Consider k-anonymity, l-diversity, t-closeness, or differential privacy for aggregate outputs or sensitive datasets, understanding their trade-offs.
- Need-to-Know Access Controls: Restrict data access technically (permissions) and organizationally (policies). Least privilege is the goal.
K-anonymity requires each record to be indistinguishable from others based on quasi-identifiers (attributes that could collectively identify someone):
Where is the dataset,
are the quasi-identifiers. This helps, but isn’t foolproof (e.g., against homogeneity attacks).
Develop a Defensible Model Documentation System
- Model Cards as Standard Practice: Standardize documentation for every significant model version:
- Training data specifics (sources, cleaning, filtering).
- Architecture details.
- Performance metrics (overall and sliced by demographic groups).
- Known limitations, biases, failure modes. Be honest.
- Appropriate uses, and critically, inappropriate uses.
- Rigorous Version Control: Track model iterations, data changes, code updates. You need to reconstruct why a model behaves the way it does.

Establish Clear User Agreements and Disclosures
- Terms of Service (The Fine Print Matters): Clearly define acceptable use, prohibited activities, and limitations of liability (within legal bounds).
- Real User Consent: If collecting user data for training, get explicit, informed consent. Burying it in a 50-page ToS might not cut it legally.
- Transparency is Key: Clearly disclose when users interact with an AI, not a human. Manage expectations.
Create Monitoring and Incident Response Playbooks
- Continuous Vigilance: Regularly test deployed models against new adversarial attacks, emerging biases, and shifting societal norms. Complacency is fatal.
- Feedback Channels That Work: Make it easy for users to report problems. Take reports seriously.
- Fire Drills: Have clear protocols for responding to incidents – from minor glitches to major ethical failures or security breaches. Who does what? How is it escalated? How do you remediate?
5. The Fog of War: What’s Coming Next in AI Governance
The ground is still shifting. Predicting the future is a fool’s game, but here are the likely directions of the regulatory winds:

Standardization Efforts (The Slow Grind)
- ISO & Friends: International bodies like ISO (ISO/IEC JTC 1/SC 42) are churning out AI standards. Expect slow, consensus-driven progress.
- Industry Self-Regulation(?): Consortia (Partnership on AI, Responsible AI Institute) are creating certifications. Useful signalling, but teeth may vary.
- Technical Specs: Look for emerging standards around model cards, data provenance trails, and safety benchmark methodologies.
Enhanced Oversight (More Eyes Watching)
- The Rise of the AI Auditor: Independent third-party audits will likely become common, perhaps mandatory for high-risk systems.
- Regulatory Sandboxes: Governments offering controlled environments to test new AI under supervision. A potential pathway, but limited scale.
- Mandatory Impact Assessments: Expect requirements to formally assess risks before deploying AI in critical areas (hiring, lending, healthcare).
The Privacy Tech Arms Race
- Federated Learning: Training models on decentralized data without pooling it. Promising, but complex to implement and doesn’t solve all privacy issues.
- Secure Multi-Party Computation (SMPC): Collaborating on data analysis without revealing raw data. Computationally expensive.
- Homomorphic Encryption: Computing on encrypted data. The holy grail? Still largely impractical for complex AI training.
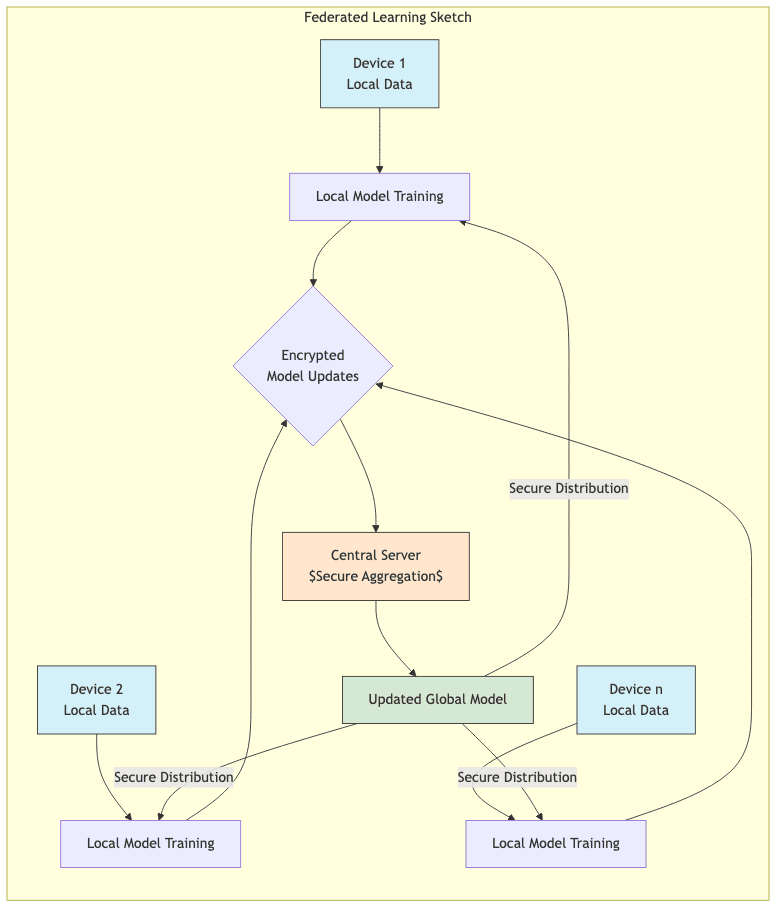
International Coordination (Herding Cats)
- Seeking Harmony: Efforts like the OECD AI Principles aim for common ground, but translating principles into binding law across borders is hard.
- Data Transfer Headaches: Expect continued friction and evolving mechanisms (like EU-US data pacts) for legally moving data internationally.
- Global Ethics Convergence: Slow movement towards shared high-level ethical ideas, but implementation details will remain fiercely local.
Algorithmic Transparency Demands
- More Disclosure Pressure: Regulators and the public will increasingly demand to know what data models were trained on and how they work.
- Better Explainability Tools: Research continues, but truly explaining complex models remains a fundamental challenge. Expect incremental progress, not magic.
- Data Subject Rights: Growing legal basis for individuals to know if/how their data was used in AI training and potentially object or demand removal.
Conclusion
Building and deploying AI today is definitely an engineering challenge, but, it’s also a high-stakes navigation through a minefield of legal obligations, ethical ambiguities, and shifting governance demands. Organizations that treat compliance as an afterthought are courting disaster.
Responsible AI development means wrestling with these issues from day one. It requires meticulous data sourcing, robust governance, continuous evaluation of risks like bias and privacy leaks, and a proactive stance towards evolving regulations. This isn’t about stifling innovation; it’s about building sustainably and avoiding catastrophic legal or reputational implosions.
The most resilient AI systems won’t just be technically powerful; they will be built on a foundation of demonstrable compliance and a clear-eyed understanding of their potential impact. Treating responsible practices as core engineering discipline, not just a legal hurdle, is the only viable path forward.
This landscape changes frighteningly fast. This article reflects the state as of the date above, but it’s not legal advice. Always consult with qualified legal counsel familiar with your specific jurisdiction and use case before making critical decisions.