Introduction
Large Language Models (LLMs) like GPT-4, LLaMA, and Claude are notorious for occasionally producing “hallucinations” — outputs that veer into the creative, sometimes shedding the shackles of factual correctness or consistency altogether. While this is a liability when you need straight answers, this raw, often unhinged creativity isn’t just a bug; it’s a potential feature, waiting to be harnessed for problems that resist brute-force computation or conventional thinking.
Enter FunSearch (Function Search). It represents less a paradigm shift and more a pragmatic realization: stop treating LLM creativity as solely a flaw and start weaponizing it within a controlled environment. The core idea isn’t revolutionary, but its effective implementation is potent: pair the LLM’s generative chaos with a brutal filter of evaluation that can objectively tell signal from noise.
At its heart, FunSearch is an evolutionary loop stripped bare:
- Generation: The LLM spews out candidate solutions, nudged by a prompt.
- Evaluation: An unforgiving external system (a compiler, a test suite, a physics engine, whatever fits the domain) stress-tests these candidates against cold, hard criteria.
- Feedback: The evaluation results – the errors, the failures, the near-misses – are fed back into the loop.
- Refinement: The process iterates, hopefully climbing towards something useful before the compute budget runs out.
This isn’t magic. It’s directed evolution, using the LLM as a mutation engine and the evaluator as the selection pressure. And it’s proving its worth on thorny problems – algorithm discovery, mathematical exploration, optimization tasks where the search space is vast and the solutions non-obvious.
1. Core Concept and Workflow
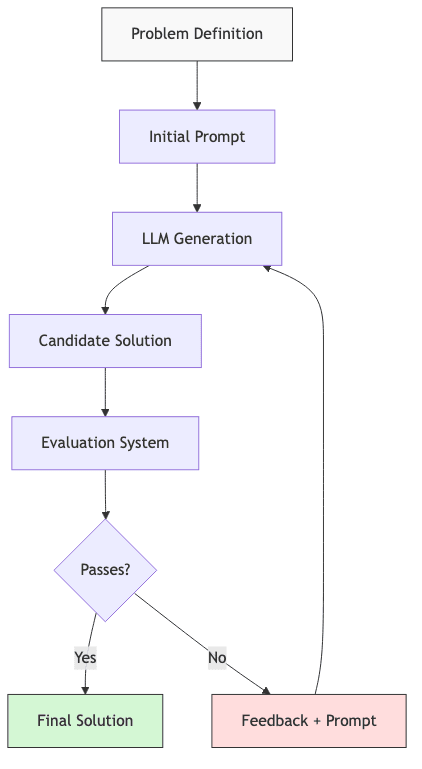
The FunSearch Process
Let’s break down the loop:
- Problem Definition
- You start by stating the problem clearly. Not wishy-washy goals, but a concrete task – typically framed as code to write, a proof to construct, or an optimization target to hit.
- Crucially, you define how you’ll know if you’ve won. Explicit evaluation criteria: correctness, speed, resource usage, whatever matters. No objective function, no search.
- LLM Generation Phase
- Armed with the problem description, the LLM generates a batch of potential solutions.
- You can steer this generation with examples, constraints, or the wreckage of past attempts.
- Rigorous Evaluation
- This is where reality bites. A separate system – could be simple test cases, a complex simulator, a formal verifier – assesses each candidate without mercy.
- For code: Does it compile? Does it pass tests? How slow is it?
- For proofs: Is it logically sound? Does it actually prove the thing?
- Structured Feedback
- The evaluator does more than just saying “pass/fail”. It provides specific, actionable feedback. What broke? Where did it fall short?
- Compiler errors, failing test cases, performance numbers, identified logical gaps – this becomes fodder for the next round.
- Guided Regeneration
- The original prompt gets augmented with the feedback from the last failure. “Try again, but don’t make this mistake.”
- The LLM takes another swing, hopefully incorporating the critique.
- Iteration and Convergence
- The generate-evaluate-feedback loop repeats. It stops when:
- A solution finally passes all checks. Victory.
- You hit a predefined iteration limit. Failure (or time to rethink).
- Progress stalls – the model keeps making the same mistakes. Failure (or time to rethink).
- The generate-evaluate-feedback loop repeats. It stops when:
High-Level Flow Diagram
The process visualized:
2. Implementation Deep Dive: Practical FunSearch
Talking is cheap. Here’s a Python skeleton showing how you might bolt together a FunSearch system for code generation. It’s a functional blueprint you could adapt.
import subprocess
import json
import time
import random
from typing import Dict, Tuple, List, Optional, Any
# In a real implementation, you would use an actual LLM API
# Example with OpenAI (you would need to install the openai package)
# NOTE: Ensure you handle API keys securely, not hardcoded like this example.
import openai
class FunSearch:
"""
A concrete implementation of the FunSearch approach for code generation
tasks, using an evaluation-based feedback loop. This demonstrates
the core mechanics.
"""
def __init__(
self,
api_key: str,
model: str = "gpt-4", # Or choose your weapon: gpt-3.5-turbo, claude-3-opus-20240229, etc.
max_iterations: int = 5,
temperature: float = 0.7, # Dial up for more 'creative' mutations
timeout_seconds: int = 10 # Don't let bad code hang forever
):
"""
Initialize the FunSearch system.
Args:
api_key: Your LLM provider API key. Handle this responsibly.
model: Model identifier (e.g., "gpt-4-turbo").
max_iterations: How many shots does the LLM get?
temperature: Controls randomness. Higher values mean more exploration (and potential nonsense).
timeout_seconds: Max execution time per test case for generated code.
"""
# Consider abstracting the LLM provider for flexibility
try:
openai.api_key = api_key
except ImportError:
print("Warning: OpenAI library not found. LLM generation will fail.")
# Potentially raise an error or use a dummy implementation here
self.model = model
self.max_iterations = max_iterations
self.temperature = temperature
self.timeout_seconds = timeout_seconds
self.history = [] # Keep track of the evolutionary trajectory
def generate_solution(self, system_prompt: str, user_prompt: str) -> str:
"""
Calls the LLM to generate a candidate solution.
Args:
system_prompt: Sets the LLM's persona and overall task.
user_prompt: The specific problem + feedback history.
Returns:
Generated code as a string (hopefully).
"""
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}
]
# Inject past attempts and feedback to guide refinement
# This turns it into a conversation where the LLM 'learns' from mistakes
for entry in self.history:
# We only add the assistant's proposed solution and the user's feedback on it
messages.append({"role": "assistant", "content": entry["solution"]})
# The feedback acts as the next user message in the conversation history
messages.append({"role": "user", "content": f"Evaluation Feedback:\n{entry['feedback']}"})
try:
response = openai.ChatCompletion.create(
model=self.model,
messages=messages,
temperature=self.temperature,
max_tokens=2048 # Adjust as needed for complexity
)
# Basic error handling for API response
if response.choices:
return response.choices[0].message.content
else:
print("Warning: LLM response did not contain expected choices.")
return "# Error: Empty response from LLM"
except Exception as e:
print(f"Error during LLM API call: {e}")
# Return a placeholder or raise the exception depending on desired robustness
return f"# Error: API call failed - {e}"
def evaluate_python_solution(
self,
code: str,
test_cases: List[Dict[str, Any]]
) -> Tuple[bool, str, Dict]:
"""
Evaluates generated Python code against defined test cases.
This is the critical 'fitness function'.
Args:
code: The Python code string spat out by the LLM.
test_cases: A list of dicts, each with 'input' and 'expected' output.
Returns:
Tuple: (overall_success_bool, feedback_string, detailed_results_dict)
"""
# Basic check for potentially harmful code patterns before execution
# This is NOT a substitute for proper sandboxing in production!
if any(keyword in code for keyword in ["os.system", "subprocess.run", "eval(", "exec("]):
print("Warning: Potential unsafe code detected. Skipping evaluation.")
return False, "Evaluation skipped due to potentially unsafe code.", {"passed": 0, "failed": len(test_cases), "errors": [{"type": "Safety Check Failed"}]}
# Use a temporary file for execution isolation (basic)
temp_filename = "candidate_solution.py"
try:
with open(temp_filename, "w") as f:
f.write(code)
except IOError as e:
return False, f"Failed to write temporary file: {e}", {"passed": 0, "failed": len(test_cases), "errors": [{"type": "File IO Error"}]}
results = {
"passed": 0,
"failed": 0,
"errors": [],
"execution_times": []
}
# Run each test case in a separate subprocess for isolation & timeout
for i, test in enumerate(test_cases):
test_input = test.get("input", "")
expected_output = str(test.get("expected", "")) # Ensure expected is string
try:
start_time = time.time()
process = subprocess.Popen(
["python", temp_filename], # Execute the temporary file
stdin=subprocess.PIPE,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
text=True,
encoding='utf-8' # Specify encoding
)
# Send input, get output/error, enforce timeout
try:
stdout, stderr = process.communicate(
input=str(test_input), # Ensure input is string
timeout=self.timeout_seconds
)
except subprocess.TimeoutExpired:
process.kill() # Kill the process if it times out
stdout, stderr = "", f"Timeout Error: Execution exceeded {self.timeout_seconds} seconds"
results["failed"] += 1
results["errors"].append({
"test_case": i,
"type": "Timeout",
"message": stderr.strip()
})
continue # Move to next test case
execution_time = time.time() - start_time
results["execution_times"].append(execution_time)
# Check for runtime errors first
if process.returncode != 0 or stderr:
results["failed"] += 1
error_message = stderr.strip() if stderr else f"Process exited with code {process.returncode}"
results["errors"].append({
"test_case": i,
"type": "Runtime Error",
"message": error_message
})
continue # Move to next test case
# Compare stdout with expected output (strip whitespace)
actual_output = stdout.strip()
if actual_output == expected_output.strip():
results["passed"] += 1
else:
results["failed"] += 1
results["errors"].append({
"test_case": i,
"type": "Output Mismatch",
"expected": expected_output,
"actual": actual_output
})
except Exception as e: # Catch broader exceptions during process handling
results["failed"] += 1
results["errors"].append({
"test_case": i,
"type": "Evaluation Error",
"message": str(e)
})
# Clean up the temporary file
try:
import os
os.remove(temp_filename)
except OSError as e:
print(f"Warning: Could not remove temporary file {temp_filename}: {e}")
# Compile results into overall success and feedback string
success = results["failed"] == 0 and results["passed"] > 0 # Ensure at least one test case exists and all passed
if success:
feedback = f"Success! All {results['passed']} test cases passed."
if results["execution_times"]:
avg_time = sum(results["execution_times"]) / len(results["execution_times"])
feedback += f" Average execution time: {avg_time:.4f} seconds."
elif results["passed"] + results["failed"] == 0:
feedback = "No test cases were provided or executed."
else:
feedback = f"Failed {results['failed']} out of {results['passed'] + results['failed']} test cases.\nIssues:\n"
for error in results["errors"][:3]: # Limit feedback length
feedback += f"- Test Case {error['test_case']} ({error['type']}): "
if error['type'] == "Output Mismatch":
feedback += f"Expected '{error['expected']}', Got '{error['actual']}'\n"
elif 'message' in error:
feedback += f"{error['message']}\n"
if len(results["errors"]) > 3:
feedback += f"... and {len(results['errors']) - 3} more errors.\n"
return success, feedback.strip(), results
def search(
self,
problem_description: str,
test_cases: List[Dict[str, Any]]
) -> Dict:
"""
Runs the main FunSearch loop.
Args:
problem_description: The initial problem statement.
test_cases: List of test cases for the evaluator.
Returns:
A dictionary summarizing the search results, including the best
solution found (if any) and the full history.
"""
system_prompt = (
"You are an elite Python programmer. Write correct, efficient, "
"and readable Python code solving the user's problem. "
"Pay close attention to the requirements and any feedback provided "
"from previous failed attempts. Output ONLY the Python code, "
"without any explanations, comments outside the code, or markdown formatting."
)
# Store the initial problem description for reference if needed
initial_problem_desc = problem_description
best_solution = None
best_results = None
self.history = [] # Reset history for a new search
print(f"Initiating FunSearch: Max {self.max_iterations} iterations.")
current_prompt = initial_problem_desc # Start with the original prompt
for iteration in range(self.max_iterations):
print(f"\n--- Iteration {iteration + 1}/{self.max_iterations} ---")
# 1. Generate
print("Generating candidate solution...")
# Pass the potentially augmented prompt
code = self.generate_solution(system_prompt, current_prompt)
# Basic check: did the LLM return code or just commentary?
# A more robust check would involve AST parsing or similar.
if not code or not any(c in code for c in ['def ', 'import ', 'print(', 'class ']):
print("Warning: Generated output doesn't look like Python code. Skipping evaluation.")
feedback = "Invalid response: The generated output was not valid Python code. Please provide only Python code."
success = False
results = {"passed": 0, "failed": len(test_cases), "errors": [{"type": "Invalid Generation"}]}
else:
print(f"Generated Candidate:\n{'-'*20}\n{code[:500]}...\n{'-'*20}") # Preview code
# 2. Evaluate
print("Evaluating candidate...")
success, feedback, results = self.evaluate_python_solution(code, test_cases)
print(f"Evaluation Result: {'Success' if success else 'Failed'}")
print(f"Feedback: {feedback}")
# 3. Record
attempt = {
"iteration": iteration + 1,
"prompt_used": current_prompt, # Record the prompt that led to this
"solution": code,
"success": success,
"feedback": feedback,
"results": results
}
self.history.append(attempt)
# 4. Check for success
if success:
print("\n✅ Found successful solution!")
best_solution = code
best_results = results
break # Exit the loop
# 5. Prepare for next iteration (if not successful and not last iteration)
if iteration < self.max_iterations - 1:
# Augment the prompt with the feedback from this failed attempt
current_prompt = (
f"{initial_problem_desc}\n\n" # Start from the original problem desc
f"Based on previous attempts, here's feedback to incorporate:\n"
f"- Attempt {iteration + 1} Feedback: {feedback}\n\n"
"Generate a revised Python solution addressing these issues. Remember to output ONLY the code."
)
else:
print("\nMaximum iterations reached.")
# Compile final results
final_outcome = {
"success": best_solution is not None,
"best_solution": best_solution,
"best_results": best_results,
"iterations_used": len(self.history),
"history": self.history # Include the full history for analysis
}
# Clean up history slightly for readability if needed
# for attempt in final_outcome["history"]:
# del attempt["prompt_used"] # Can make history very long
return final_outcome
# Example usage block:
if __name__ == "__main__":
# IMPORTANT: Replace with your actual API key or use secure key management
# Avoid committing keys to version control. Use environment variables or secrets management.
import os
API_KEY = os.environ.get("OPENAI_API_KEY", "your_openai_api_key_here_if_not_set_in_env")
if "your_openai_api_key_here" in API_KEY:
print("WARNING: Using placeholder API Key. Please set the OPENAI_API_KEY environment variable.")
# Decide if you want to exit or proceed with a potentially non-functional key
# exit()
funsearch = FunSearch(
api_key=API_KEY,
model="gpt-4-turbo", # Use a capable model
max_iterations=3, # Keep iterations low for demo
temperature=0.7
)
# A slightly more interesting problem than factorial
problem = """
Write a Python program that reads a list of integers from stdin (space-separated)
and outputs the largest sum of a contiguous sub-array.
Example Input: -2 1 -3 4 -1 2 1 -5 4
Example Output: 6 (from the sub-array [4, -1, 2, 1])
Requirements:
1. Handle empty input (output 0).
2. Handle input with only negative numbers (output the largest single negative number).
3. Must read from stdin and print only the final integer result to stdout.
4. Implement Kadane's algorithm or an equivalent efficient approach.
5. Handle potential non-integer inputs gracefully (e.g., print "Invalid input").
"""
test_cases = [
{"input": "-2 1 -3 4 -1 2 1 -5 4", "expected": "6"},
{"input": "1", "expected": "1"},
{"input": "5 4 -1 7 8", "expected": "23"},
{"input": "-1 -2 -3 -4", "expected": "-1"},
{"input": "", "expected": "0"}, # Test empty input
{"input": "1 2 three 4", "expected": "Invalid input"}, # Test invalid input
{"input": "0 0 0 0", "expected": "0"},
]
result = funsearch.search(problem, test_cases)
# Final report
print("\n" + "="*30 + " FINAL REPORT " + "="*30)
if result["success"]:
print(f"SUCCESS: Solution found in {result['iterations_used']} iterations.")
print("\nFinal Optimal Solution:")
print(result["best_solution"])
print("\nPerformance details (example):")
print(f"Passed {result['best_results']['passed']} test cases.")
if result['best_results']['execution_times']:
avg_time = sum(result['best_results']['execution_times']) / len(result['best_results']['execution_times'])
print(f"Average execution time: {avg_time:.6f} seconds")
else:
print(f"FAILURE: No successful solution found after {result['iterations_used']} iterations.")
# Find the attempt that passed the most tests, if any
if result["history"]:
best_attempt = max(result["history"], key=lambda x: x["results"].get("passed", 0))
passed_count = best_attempt["results"].get("passed", 0)
total_count = len(test_cases)
print(f"\nBest attempt (Iteration {best_attempt['iteration']}) passed {passed_count}/{total_count} test cases.")
print("Code from best attempt:")
print(best_attempt["solution"])
else:
print("No attempts were made or recorded.")
print("="*74)This code provides a more robust structure, including basic history injection for conversational refinement, subprocess execution for evaluation, and timeout handling. Remember, production use requires much more sophisticated sandboxing and error handling.
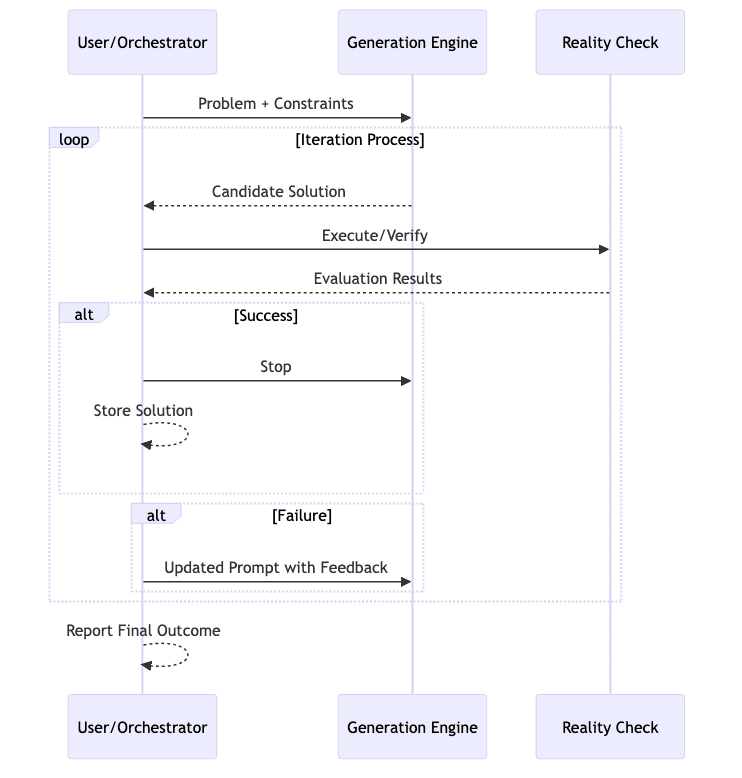
Visualization of the Iteration Process
Think of it like climbing a hill in the fog. Each step (generation) might go up or down. The evaluator tells you the altitude change (feedback). You keep trying steps informed by the last outcome.
3. Real-World Applications and Breakthroughs
FunSearch is more than a fun theoretical curiosity. It’s been used to achieve tangible results that were difficult or impossible otherwise:
Bin Packing Algorithms
The canonical example. DeepMind researchers pointed FunSearch at the notoriously tricky bin packing problem (fit items into the minimum number of bins). The system didn’t just rediscover known heuristics; it found a new, surprisingly effective packing strategy for certain scenarios, outperforming established human-designed algorithms. This highlights its potential for finding non-intuitive solutions in vast search spaces.
Mathematical Conjectures
It’s been deployed to hunt for counterexamples or discover supporting patterns for mathematical conjectures, particularly in combinatorics. While not replacing mathematicians, it acts as a powerful exploration tool, rapidly testing hypotheses or configurations that would be tedious or impossible for humans.
Circuit Design Optimization
Engineers are exploring FunSearch-like loops to optimize electronic circuit layouts. The LLM proposes designs, and a simulator evaluates performance (speed, power consumption, area). This can uncover novel configurations missed by traditional optimization tools or human intuition.
Drug Discovery
In computational chemistry, variants of this approach generate potential molecular structures aiming for specific therapeutic properties. Evaluation involves complex simulations of chemical interactions and predicted biological activity.
These toy problems demonstrate the potential to accelerate discovery in fields limited by combinatorial complexity or the difficulty of exploring unconventional ideas.
4. Resource Optimization Strategies
Running these evolutionary loops isn’t free. LLM calls cost money and time, and complex evaluations can be computationally brutal. Making FunSearch practical often requires aggressive optimization:
Model Quantization and Optimization
- Quantization (Int8/Int4, etc.): Trading a bit of numerical precision in the LLM for significant speedups and reduced memory usage. Often a good trade-off for generative tasks.
- Pruning/Sparsification: Making the LLM itself smaller by removing less important weights.
- Knowledge Distillation: Training a smaller, faster “student” model to mimic the behavior of a larger, slower “teacher” model.
- Example Snippet (Conceptual – requires libraries like
transformers,bitsandbytes):# Using transformers with bitsandbytes for 8-bit loading from transformers import AutoModelForCausalLM, AutoTokenizer model_id = "mistralai/Mistral-7B-Instruct-v0.1" # Example model # Load model with 8-bit quantization model = AutoModelForCausalLM.from_pretrained( model_id, load_in_8bit=True, # Enable 8-bit quantization device_map="auto" # Let transformers handle device placement ) tokenizer = AutoTokenizer.from_pretrained(model_id) # Now use this quantized model in your FunSearch loop # Note: Performance might degrade slightly, but inference is faster/cheaper
Batch Processing and Parallelization
- Don’t generate one solution at a time. Ask the LLM for multiple candidates (
n > 1in API calls). - Evaluate these candidates in parallel using multiple processes or threads.
- Cache evaluation results. If the LLM proposes the same (or functionally identical) flawed solution twice, don’t waste time re-evaluating it.
Evaluation Optimization
- Early Stopping: If a candidate fails basic checks (e.g., doesn’t compile, fails trivial test cases), kill the evaluation early.
- Progressive Evaluation: Start with easy test cases, only moving to harder/slower ones if the basics pass.
- Optimize the Evaluator: Profile your evaluation code. Sometimes the bottleneck isn’t the LLM, but a slow test suite or simulator.
5. Advanced Techniques and Extensions
The basic loop is just the start. Researchers are pushing FunSearch further:
Multi-Agent FunSearch
Instead of one LLM doing everything, use specialized agents:
- Generator: Focuses on diverse, creative proposals.
- Critic: Trained to spot likely flaws before expensive evaluation.
- Refiner: Good at fixing specific errors identified by the critic or evaluator.
- Evaluator: The objective judge. This mimics specialized roles in human teams.
Self-Improvement Mechanisms
Making the system learn how to search better:
- Meta-learning: Analyze the history of successful/failed searches to bias future generation towards promising patterns.
- Curriculum Learning: Start the search on simpler versions of the problem, gradually increasing difficulty, using solutions from easier stages to bootstrap harder ones.
- Memory/Retrieval: Store good code snippets, useful patterns, or successful sub-solutions from past runs and allow the LLM to retrieve and reuse them.
Hybrid Symbolic-Neural Approaches
Combining the LLM’s fuzzy creativity with the rigor of symbolic methods:
- LLM generates potential solution structures or high-level plans.
- Formal methods (SAT/SMT solvers, theorem provers, model checkers) verify parts of the solution or fill in precise details.
- Leverages the strengths of both worlds: exploration and verification.
6. Limitations and Ethical Considerations
FunSearch isn’t a silver bullet. Be aware of the sharp edges:
Computational Costs
- This can get expensive, fast. Many LLM calls, potentially heavy evaluation loads. Cost scales with problem complexity and desired solution quality.
- The environmental footprint isn’t negligible if run at scale.
Solution Verifiability
- Just because a solution passes your tests doesn’t mean it’s correct or safe in all cases. Especially true for complex domains.
- For critical systems (finance, medicine, infrastructure), formal verification or extensive real-world validation is non-negotiable after FunSearch finds a candidate. Don’t blindly trust the output.
Intellectual Property Questions
- The messy reality: Who owns a solution discovered via FunSearch? The user who wrote the prompt? The LLM provider? Is it a derivative work?
- Current IP law wasn’t designed for this. Attribution and licensing are murky and likely require careful consideration, especially for commercial use.
Conclusion and Future Directions
FunSearch provides a powerful framework for turning the unpredictable creativity of LLMs into a directed search process. By implementing a tight loop of generation and rigorous evaluation, we can coax these models into discovering genuinely novel solutions to problems that were previously intractable or required immense human effort. It’s about harnessing chaos with control.
The trajectory seems clear:
- Tighter Domain Integration: Coupling FunSearch loops directly with specialized tools like CAD software, physics simulators, formal methods tools.
- Adaptive Evaluation: Systems that learn what constitutes a “good” solution or develop more efficient evaluation strategies over time.
- Cross-Domain Learning: Transferring patterns or heuristics learned in one FunSearch application (e.g., algorithm design) to bootstrap search in another (e.g., materials science).
- Human-in-the-Loop Collaboration: Experts guiding the search, providing high-level insights, or validating tricky intermediate steps, working symbiotically with the automated loop.
As LLMs get smarter, faster, and cheaper, techniques like FunSearch will likely move from research curiosities to standard tools in the arsenal of anyone tackling complex computational problems. It’s not about replacing human ingenuity (yet), but augmenting it, allowing us to explore solution spaces more effectively.
The patterns here provide a starting point. The real challenge, and opportunity, lies in adapting and refining this core loop for your specific domain and constraints. Start building.