Executive Summary
Training the behemoths of modern AI – your GPT-class models, the PaLMs, the endless parade of LLMs – slams headfirst into the unforgiving wall of hardware limits. Chief among them: GPU memory. This finite resource dictates the sheer size of the neural networks we can realistically wrestle into existence. Microsoft Research’s ZeRO (Zero Redundancy Optimizer) isn’t magic; it’s a pragmatic, almost brute-force, attack on memory redundancy in distributed training. By cleverly partitioning model states across GPUs, ZeRO allows engineers to train models with parameter counts scaling into the billions, even trillions. This piece dissects how ZeRO works, its manifestation in DeepSpeed, and why it became table stakes in the escalating arms race of large-scale AI.
The Memory Challenge in Distributed Training
Before ZeRO, let’s appreciate the fundamental headache. When you’re trying to teach a neural network anything non-trivial, three culprits hogging precious GPU RAM dominate the scene:
- Model parameters: The actual weights and biases. The network itself.
- Gradients: The calculus breadcrumbs needed to update those parameters during backpropagation.
- Optimizer states: The extra baggage carried by optimizers like Adam – momentum terms, variance estimates, etc. – often surprisingly bulky.
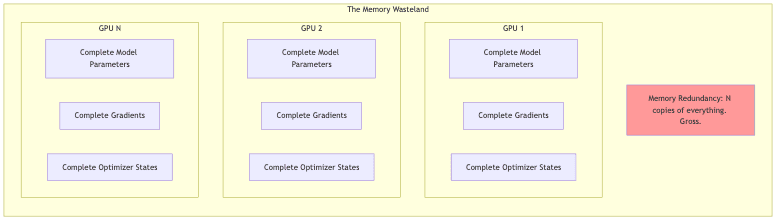
Naive data parallelism is simple, sure, but obscenely wasteful. Every GPU gets a full copy of everything: parameters, gradients, optimizer state. It’s like photocopying the entire library for every reader. Fine for modest models, but utterly unsustainable when your model ambitions swell beyond the confines of a single GPU’s memory capacity. Yes, model parallelism exists, carving the model itself across devices, but it often brings its own flavor of communication hell and architectural migraines.
ZeRO: A Staged Approach to Memory Optimization
ZeRO doesn’t try to solve world hunger in one go. It’s a staged assault, progressively slicing up different parts of the training state across your available GPUs. Each stage builds on the last, offering deeper cuts into memory usage.
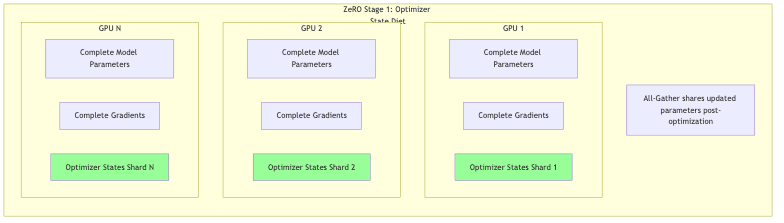
ZeRO Stage 1: Optimizer State Partitioning
Concept: Stop duplicating the optimizer state everywhere. Keep parameters and gradients replicated for now.
How it works:
- Optimizers like Adam are memory hogs, often demanding 2-4x the memory of the parameters they’re optimizing.
- ZeRO-1 makes the embarrassingly obvious first move: stop copying the optimizer state everywhere. Each GPU holds only its designated slice (1/N) of these states.
- During the optimization step, each GPU tends to its own garden, updating only its assigned chunk of optimizer states.
- The updated parameters, however, still need to be shared. All GPUs get the final result via an all-gather operation.
Memory Savings: Can reclaim up to 4x the parameter memory footprint compared to basic data parallelism, often with negligible performance impact. Low-hanging fruit, elegantly picked.
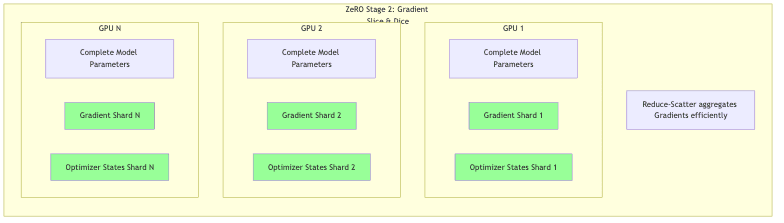
ZeRO Stage 2: Gradient Partitioning
Concept: Now attack the gradients too. Only optimizer states and gradients are partitioned.
How it works:
- Basic backpropagation still requires each GPU to compute gradients for its local batch against the full (replicated) model parameters.
- But instead of keeping all those gradients locally, ZeRO-2 has each GPU immediately discard the gradients it’s not responsible for. It only retains the 1/N slice relevant to the parameters it will eventually update (via its optimizer state shard).
- This avoids the naive “everyone calculates everything, then we average” approach. Clever use of reduce-scatter operations aggregates the necessary gradient information directly onto the GPU that needs it, minimizing transient memory bloat.
Memory Savings: Slashes memory usage further, potentially up to 8x versus standard data parallelism, usually with only a modest increase in communication overhead if engineered correctly.
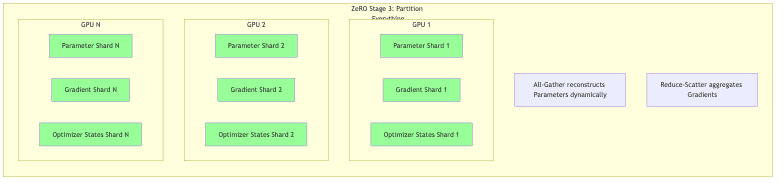
ZeRO Stage 3: Parameter Partitioning
Concept: The final frontier. Partition everything: optimizer states, gradients, and the model parameters themselves.
How it works:
- Stage 3 goes for the jugular. Each GPU now only holds a 1/N slice of the actual model parameters.
- This necessitates a complex dance during forward and backward passes. Parameters materialize just-in-time via all-gather communication when needed for a computation, then vanish from memory shortly after.
- This requires sophisticated communication scheduling to hide latency and keep the GPUs fed. It’s often paired with activation checkpointing (recomputing activations instead of storing them) to truly maximize memory savings.
Memory Savings: The payoff is potentially ludicrous – memory reduction proportional to the number of GPUs (up to Nx, where N is GPU count). This is what unlocks models with trillions of parameters, blowing past the memory capacity of any single device.
ZeRO-Offload: Extending Memory Capacity Beyond GPUs
What if you don’t have racks upon racks of A100s? ZeRO-Offload is the pragmatic answer for the slightly less resource-endowed. It extends the ZeRO partitioning idea by shuffling data off to the comparatively sluggish CPU RAM when it’s not immediately needed on the GPU. Optimizer states, or even idle parameters (in ZeRO-3 Offload), can be parked on the host. This lets you train bigger models on fewer GPUs, but naturally, you pay a performance penalty for the constant PCIe bus traffic. It’s a trade-off, but often a necessary one – a lifeline for those not operating at hyperscaler budgets.

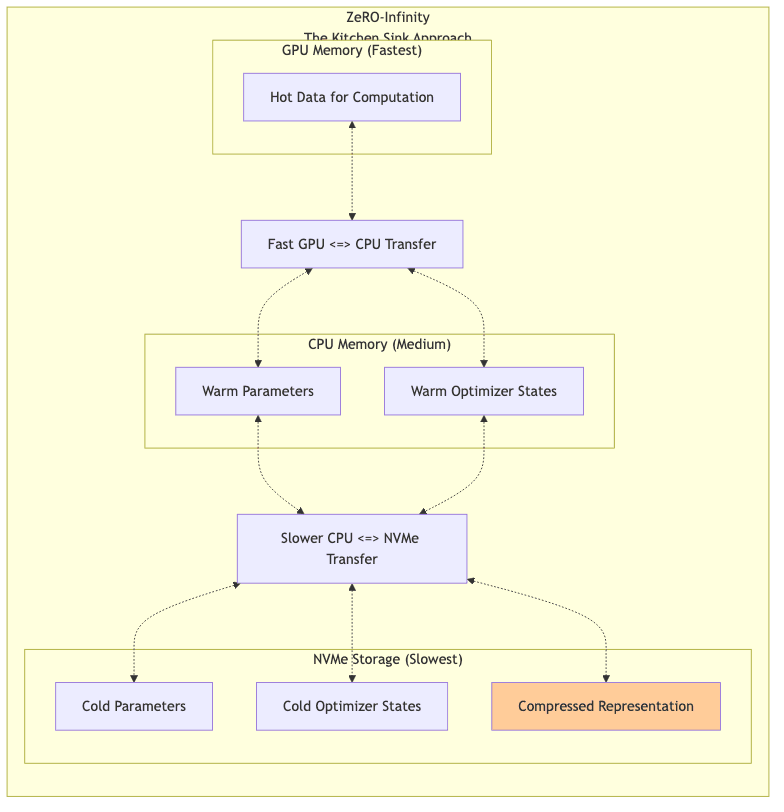
ZeRO-Infinity: Breaking All Memory Barriers
Pushing the absurdity further, ZeRO-Infinity throws everything into the mix: GPU memory, CPU RAM, and even pokey NVMe storage. It treats these as tiers in a memory hierarchy, intelligently shuffling data between them based on anticipated need, often using compression for data resting in the slowest tiers. This is a complex dance of data shuffling and compression, allowing labs to claim they can train planet-sized models on hardware that feels almost inadequate for the task. The performance implications can be significant, but it makes seemingly impossible scale possible, albeit perhaps slowly.
Practical Implementation with DeepSpeed
All this partitioning sounds like an integration nightmare. Thankfully, Microsoft packaged it into DeepSpeed, an open-source library designed to handle the grubby details. Configuring ZeRO becomes a matter of setting flags in a JSON file.
{
"train_batch_size": 64,
"gradient_accumulation_steps": 2,
"fp16": {
"enabled": true,
"loss_scale": 0,
"initial_scale_power": 16
},
"zero_optimization": {
"stage": 2, // Which ZeRO stage (1, 2, or 3)
"contiguous_gradients": true, // Memory fragmentation optimization
"overlap_comm": true, // Hide communication latency
"reduce_scatter": true, // Use efficient gradient reduction
"reduce_bucket_size": 5e8, // Tune communication packet size
"allgather_bucket_size": 5e8 // Tune communication packet size
},
"steps_per_print": 2000,
"wall_clock_breakdown": false
}Key flags:
- stage: The main knob, controlling the level of partitioning (1, 2, or 3).
- contiguous_gradients: Helps memory allocation efficiency.
- overlap_comm: Tries to run communication in parallel with computation – crucial for performance.
- reduce_scatter/allgather_bucket_size: Tuning parameters for communication efficiency, highly dependent on network topology.
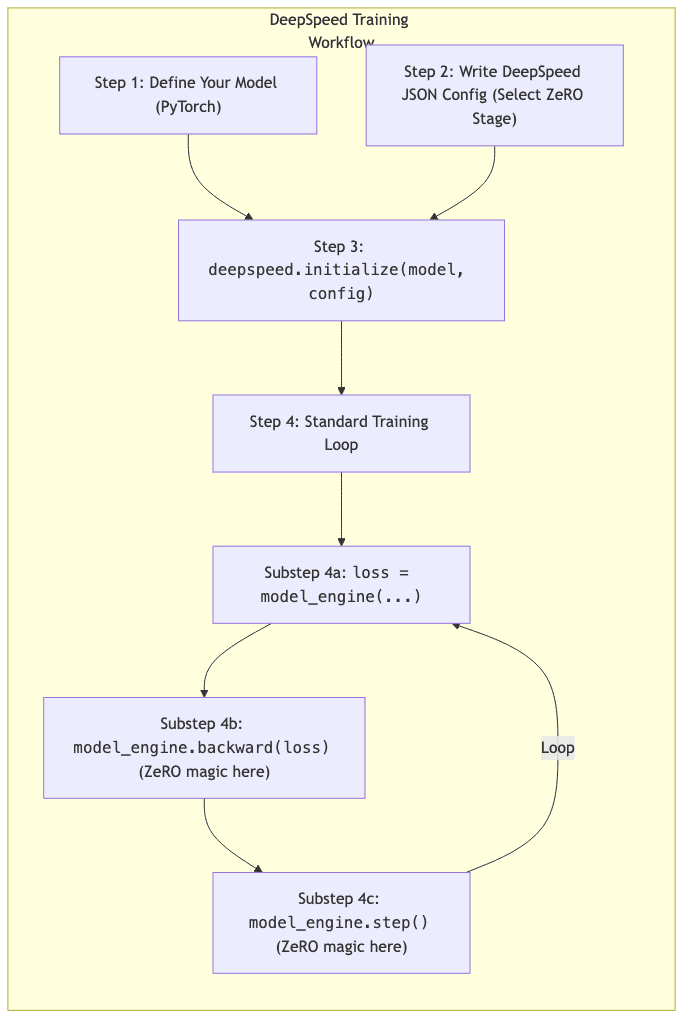
Integrating DeepSpeed into your PyTorch training script is typically straightforward:
import deepspeed
import torch
from transformers import GPT2LMHeadModel, GPT2Config
# Assume you have your model defined
model_config = GPT2Config.from_pretrained("gpt2-large") # Example
model = GPT2LMHeadModel(model_config)
# DeepSpeed's `initialize` wraps your model and optimizer
model_engine, optimizer, _, _ = deepspeed.initialize(
model=model,
model_parameters=model.parameters(),
config="ds_config.json" # Path to your config file
)
# Your training loop looks mostly normal
for batch in data_loader:
# Forward pass using the DeepSpeed engine
loss = model_engine(batch["input_ids"], labels=batch["labels"]).loss
# Backward pass is handled by DeepSpeed
model_engine.backward(loss)
# Optimizer step is handled by DeepSpeed
model_engine.step()DeepSpeed abstracts away the communication and partitioning logic during the backward and step calls.
Performance Considerations and Best Practices
ZeRO isn’t free magic. Its efficiency hinges on several factors:
Communication Optimization
This is paramount. ZeRO involves lots of communication.
- Fast Interconnects: NVLink (within a node) or InfiniBand (across nodes) aren’t optional luxuries; they’re prerequisites for decent performance, especially at Stage 3. Ethernet will crawl.
- Overlap: Enabling
overlap_commis usually a win, hiding communication latency behind computation. - Bucket Sizes: Tuning
reduce_bucket_sizeandallgather_bucket_sizeis crucial. Too small, and you’re flooded with tiny packets; too large, and you introduce pipeline bubbles. Needs experimentation based on hardware.
Training Stability
Scaling up brings its own challenges:
- Mixed Precision (FP16/BF16): Not just recommended; it’s practically required. It halves memory for parameters, gradients, and activations, synergizing perfectly with ZeRO.
- Gradient Accumulation: A standard trick to simulate larger batch sizes without linearly increasing memory. Works fine with ZeRO.
- Learning Rate Scheduling: Warmup periods become even more critical with large effective batch sizes.
- Loss Scaling: Essential for FP16 to prevent gradients from vanishing (underflow) or exploding (overflow). DeepSpeed handles dynamic loss scaling automatically.
Monitoring and Debugging
Distributed systems are hard to debug. DeepSpeed offers some help:
- Wall Clock Breakdown: Can help pinpoint bottlenecks (computation vs. communication vs. parameter gathering).
- Memory Logging: Useful to verify ZeRO is actually saving memory as expected.
- Autotuning: DeepSpeed includes features to try and automatically find decent communication tuning parameters.
Real-World Impact and Case Studies
ZeRO quickly became the scaffolding for the parameter count wars that defined the early 2020s:
- Megatron-Turing NLG (530B parameters): A poster child for ZeRO enabling massive scale across thousands of GPUs.
- BLOOM (176B parameters): Leveraged ZeRO (via DeepSpeed) for its open, multilingual model training effort.
- Countless Academic and Industry Labs: Reported being able to train models 2-10x larger on their existing hardware simply by adopting ZeRO/DeepSpeed.
It fundamentally changed the economics and feasibility of training truly enormous models, enabling research and products that were computationally unthinkable just a few years prior. ZeRO enabled models whose sheer scale grabs headlines, whether or not that scale translates directly to proportional intelligence or utility.
Comparison with Other Approaches
How does ZeRO stack up against the other parallelization tricks?
| Technique | Memory Efficiency | Communication Cost | Implementation Complexity | Key Idea |
|---|---|---|---|---|
| Data Parallel | Low | Low | Low | Replicate model, shard data |
| Model Parallel (TP) | Medium | High | High | Shard model layers/ops |
| Pipeline Parallel | Medium | Medium | High | Shard model stages temporally |
| ZeRO | High | Medium | Low (with DeepSpeed) | Shard Optimizer/Grad/Params |
| ZeRO + Offload | Very High | Medium-High | Medium | Shard + move to CPU/NVMe |
ZeRO offers a compelling sweet spot, especially Stages 1 & 2, providing significant memory savings with manageable complexity thanks to libraries like DeepSpeed. Stage 3 pushes memory savings to the max but demands careful tuning and fast interconnects.
Looking Ahead: The Future of ZeRO
The ZeRO story isn’t over. Research continues to refine the approach:
- Even smarter communication scheduling and overlap.
- Tighter integration with tensor and pipeline parallelism.
- Adaptations for non-NVIDIA hardware (though GPUs remain the focus).
- Optimized versions tailored specifically for the slightly different demands of inference or fine-tuning.
As long as the dominant strategy for “better AI” involves “throw more parameters and data at it,” optimizing memory and training efficiency will remain critical.
Conclusion
The Zero Redundancy Optimizer isn’t the magic bullet that solves AI, but it’s become indispensable plumbing for anyone operating at the scale frontier of deep learning. By methodically identifying and eliminating redundant memory usage across distributed GPUs, ZeRO fundamentally shifted the scaling limits. It democratized access to larger models to some extent, or at least lowered the insane entry cost previously required.
As models inevitably continue their relentless march towards larger sizes, technologies like ZeRO will remain essential cogs in the machine. It’s a testament to the relentless, often unglamorous, engineering required to make these giant models tractable, bridging the gap between algorithmic ambition and hardware reality. Whether you’re aiming for the next trillion-parameter headline or just need to squeeze a bit more batch size onto your cluster, ZeRO provides a battle-tested strategy.
References
- Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, Yuxiong He. (2020). “ZeRO: Memory Optimizations Toward Training Trillion Parameter Models.” arXiv:1910.02054.
- Samyam Rajbhandari, et al. (2021). “ZeRO-Offload: Democratizing Billion-Scale Model Training.” arXiv:2101.06840.
- Jeff Rasley, et al. (2020). “DeepSpeed: System Optimizations Enable Training Deep Learning Models with Over 100 Billion Parameters.” KDD ’20.
- Samyam Rajbhandari, et al. (2021). “ZeRO-Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning.” arXiv:2104.07857.