Key Takeaways
- SEAL grants models a primitive form of autonomy, letting them generate their own finetuning data-“self‑edits”-and learn on the fly, post-deployment.
- The architecture is a clever dance: an outer reinforcement learning (RL) loop acts as the strategic brain, deciding what kind of learning helps, while an inner supervised finetuning (SFT) loop performs the tactical update.
- The proof is in the performance: on difficult reasoning and knowledge tasks, SEAL doesn’t just inch past baselines; it surpasses synthetic data from GPT-4 class models, using its own intelligence.
- Crucially, this isn’t a monolithic solution. It’s a lightweight, model‑agnostic framework using LoRA, making it more of a surgical tool than a sledgehammer.
- The path isn’t clear. Catastrophic forgetting and the brutal economics of self-reflection are the twin dragons guarding the gate to true continual learning.
Introduction
The next leap for large language models (LLMs) won’t come from brute-force scale or ever-larger static corpora. It will come from granting them the ability to keep learning after deployment. We stand at the precipice of moving from inert, pre-trained artifacts to dynamic systems that adapt to new information.
Enter Self‑Adapting Language Models (SEAL)-a framework from MIT’s Improbable AI Lab that gives an LLM the machinery to write its own training material, grade the outcome, and permanently burn the lesson into its weights.
The traditional fine‑tuning pipeline is a top-down affair, assuming a human hand curates the data, selects the hyperparameters, and presides over the entire ritual. SEAL inverts this. The model itself proposes a change-a micro-dataset and an optimization recipe-applies the update, and then interrogates itself: did that actually help? If the change improved performance, the policy that generated the edit is reinforced. If not, the idea is discarded. This is less like a student taking notes and more like a system developing its own metabolic process for knowledge assimilation.
Let’s dissect how it works.
How SEAL Works
A Two‑Loop Learning Scheme
The architecture is built on two nested loops: an outer loop that learns how to learn, and an inner loop that executes the learning.
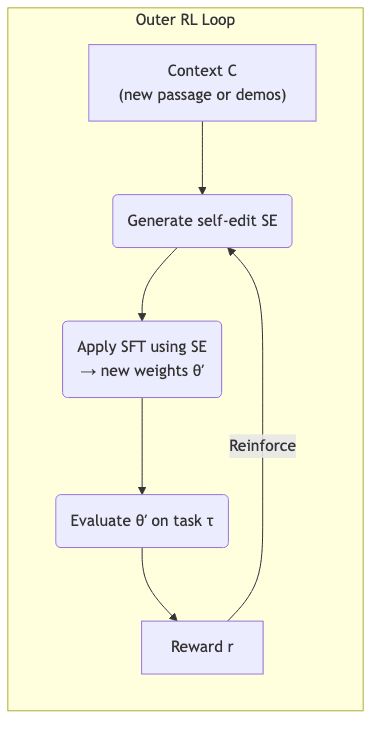
At a high level, the process is starkly logical:
- Context
Carrives – this could be a newswire passage, a research paper, or a few-shot problem demonstration. - The model’s current policy
π_θgenerates a “self-edit”SE. It’s a model-generated piece of text that might contain distilled facts, synthesized Q&A pairs, or even a JSON object specifying hyperparameters for its own update. - A Supervised Finetuning (SFT) process updates the model using this self-edit, yielding a new set of LoRA weights
θ′. - This updated model
θ′is immediately evaluated on a downstream taskτ-answering a question whose answer lies in the new context, or solving a reasoning puzzle. - A sparse reward
rof +1 is granted if performance improved. The policy is then nudged via reinforcement learning to favor edits that produce such rewards.
Formal Objective
The outer RL objective seeks to optimize the expected reward over the distribution of possible self-edits:
A stop-gradient is applied to the reward function r, allowing it to be treated as a fixed signal when training the policy π_θ.
Self-Edit Formats
The self-edit itself is just text, a remarkably flexible medium.
| Domain | Example Self‑Edit | Insight |
|---|---|---|
| Knowledge Integration | Bullet list of logical implications distilled from a passage. | The model learns to distill signal from noise, generating edits far more concise-and thus more learnable-than the raw source text. |
| Few-shot Learning | JSON specifying augmentation toggles, learning rate, and epochs. | The model is learning the meta-skill of how to configure its own training process for that task. |
Because the interface is pure text, the technique is fundamentally model-agnostic. There are no hardcoded assumptions about prompt formats or model architecture.
Experimental Highlights
1. Knowledge Incorporation (SQuAD‑No‑Context)
The task: read a passage and answer a question about it, without having seen the passage during pre-training.
| Method | Accuracy (%) |
|---|---|
| Frozen Qwen‑2.5‑7B | 32.7 |
| Finetune on passage | 33.5 |
| Passage + GPT‑4 synthetic | 46.3 |
| SEAL (2 RL rounds) | 47.0 |
The nearly 14-point lift over naïve finetuning is impressive, but the real story is the slight edge over synthetic data generated by a far larger, more capable model like GPT-4. This demonstrates a crucial principle: it is more effective for a model to teach itself in a way it understands than to be spoon-fed lessons from a more intelligent, external teacher. The model generates data in its own “native tongue.”
2. Few‑Shot Abstract Reasoning (ARC subset)
The task: solve abstract reasoning puzzles from a handful of examples, a process known as Test-Time Training (TTT).
| Method | Success Rate |
|---|---|
| Plain in‑context | 0 % |
| Test‑Time Training (manual) | 20 % |
| SEAL | 72.5 % |
| Oracle (hand‑tuned) | 100 % |
Here, a ~1-billion-parameter Llama derivative learns to configure its own TTT pipeline almost as effectively as a human expert. This is a powerful existence proof for meta-learning: the model isn’t just solving the puzzle; it’s learning how to set up the conditions for solving the puzzle.
The Architectural Merits
- Breaking Free from the Static Corpus: A SEAL-enabled model is no longer tethered to its last pre-training run. It can absorb new information from the world as it happens, a foundational step toward genuine continual learning.
- Surgical Precision with LoRA: By using lightweight LoRA adapters, updates are computationally cheap, modular, and reversible. You can stack, prune, or selectively activate edits, rather than performing monolithic and destructive retraining.
- A Universal Toolkit, Not a Siloed Solution: The paper demonstrates success on models from both Meta and Alibaba. In principle, any autoregressive LM can be equipped with SEAL, making it a portable capability, not a proprietary feature.
- A Glimpse into the Machine’s Reasoning: Because self-edits are human-readable text, they offer a rare, interpretable window into the model’s “thinking.” You can audit what the model believes is a useful way to represent new knowledge.
The Unresolved Ghosts
- The Specter of Amnesia: Sequential edits can overwrite or degrade previously learned knowledge. This is catastrophic forgetting, the bane of continual learning. The SEAL framework doesn’t solve this; future iterations will likely need explicit regularization or memory rehearsal buffers.
- The Brutal Economics of Self-Reflection: The current process is compute-hungry. Every candidate self-edit requires a mini-finetune and evaluation. For this to be practical, smarter pruning of candidate edits or the use of smaller proxy models will be essential.
- The Pandora’s Box of Self-Modification: Allowing a model to alter its own weights is a new frontier for security and alignment. It creates an attack surface for sophisticated jailbreaks or adversarial manipulations that we are ill-equipped to handle.
- The Unlearned Art of Timing: Today, the decision of when to trigger a self-edit is manual. A truly autonomous system would need to learn this as well, folding the scheduling decision into its policy. When is a piece of information important enough to warrant an update?
Playing with the Code
The authors provide an open-source implementation. Running a demo is straightforward, assuming you can get the dependencies in order.
# clone the official repo
$ git clone https://github.com/Continual-Intelligence/SEAL.git
$ cd SEAL
# run a quick knowledge‑incorporation demo (requires Qwen‑7B)
$ bash scripts/demo_knowledge.sh \
--passage_file data/sample_passage.txt \
--question "Who was Kennedy's science adviser?"The repository is well-documented, with configurations for both knowledge and reasoning tasks. I found it simple enough to swap in a smaller Mistral model and observe the core learning dynamics, though replicating the paper’s exact figures requires the specified hardware and base models.
Why SEAL Matters
From personalized agents to domain-expert systems, the next wave of LLM deployments will slam into a data wall. They will need to learn more from their immediate interactions than from static, terabyte-scale data dumps. SEAL charts a viable course. It leverages the model’s own generative power twice: first to transfigure new information into a learnable format, and second to enact the update on itself.
This points toward a future of agentic self-improvement. Imagine a research assistant that doesn’t just summarize a new paper, but synthesizes its key claims into a set of testable Q&A pairs, finetunes itself on them overnight, and shows up the next morning fundamentally smarter about that domain. This is a move from construction to cultivation.
Closing Thoughts
SEAL does not solve continual learning outright. But it offers a compelling proof-of-concept that LLMs can be taught to write, and grade, their own homework. It recasts fine-tuning from an external, human-led process into an internal, model-driven capability.
The most profound implication is that we may be on the verge of treating learning not as a one-time construction event, but as a continuous metabolic function of an intelligent system. The goal is no longer just to build a machine, but to cultivate a mind that can grow itself.
All opinions are my own. This review is based on the paper “Self‑Adapting Language Models” (arXiv:2506.10943) and the open‑source implementation available at GitHub.