The Static Intelligence Problem
We’ve built digital monoliths. Our foundation models, for all their power, are largely static beasts. We train them for months, freeze their weights, and then spend the rest of their lifecycle trying to coax nuance out of them with elaborate prompting or by bolting on clumsy adapters. Each new task, each new domain, requires another LoRA, another set of weights, another layer of complexity. We’ve ended up with a digital garage full of specialized tools, when what we really want is a single, self-configuring master key.
This is the context into which Transformer² arrives. It’s less a new architecture and more a shift in philosophy: what if a model could diagnose a problem and reconfigure itself to solve it, all in the span of a single inference?
Key Takeaways
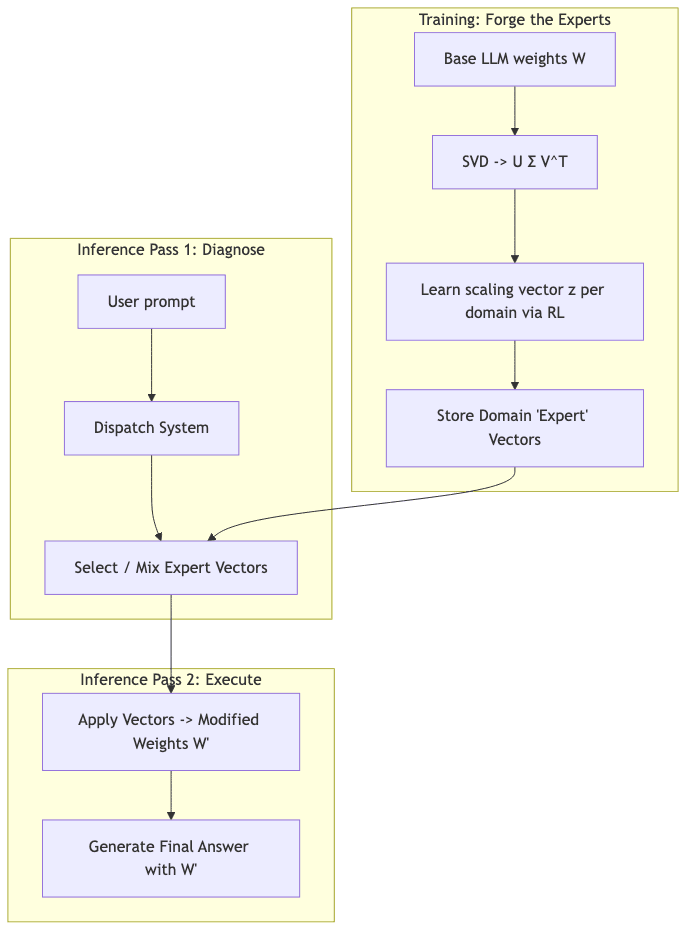
- The Two-Pass Gambit: Transformer² isn’t a single shot. It uses a first pass to analyze the incoming prompt, select a strategy, and then dynamically re-weights itself for a second, much smarter pass to generate the actual answer.
- Singular-Value Finetuning (SVF): Forget adding new layers. SVF finds the latent “knobs” already inside the model’s weight matrices (via SVD) and learns a tiny scaling vector to simply turn them up or down. It’s surgical, not additive.
- A Spectrum of Adaptability: The system can route tasks using simple prompt-based classification, a dedicated lightweight expert, or a sophisticated few-shot search, trading a little latency for a lot more accuracy.
- The Empirical Beatdown: On benchmarks like GSM8K and HumanEval, this approach consistently outperforms LoRA, using 10x fewer parameters and side-stepping the catastrophic forgetting that plagues other methods.
- Open for Business: The full PyTorch implementation is on GitHub, already pulling 1.1k stars and ready to run on Llama-3, Mistral, and even vision-language models.
Why We Needed to Move Beyond LoRA
Parameter-Efficient Finetuning (PEFT) was a necessary hack. Retraining foundation models is fiscally insane, so we found a workaround. But the moment you accumulate a zoo of LoRA adapters-one for coding, one for legal prose, one for customer support tone-you’re back to a familiar mess: too many weights, clunky composition, and a management nightmare.
Transformer² flips the entire perspective on its head. Instead of adding trainable matrices, it asks a question of almost insulting simplicity: can we simply dial up or down the latent capabilities that are already there?
Enter Singular Value Decomposition. The insight is that any weight matrix W can be factored into U Σ Vᵀ. The “essence” of the matrix-its primary directions of action-is captured in the singular values of Σ. If we learn to just scale those values with a tiny vector z, we can modulate the matrix’s behavior without rewriting it. We touch a handful of parameters (r of them) instead of the r·(m+n) needed for a low-rank update.
This is golden. A scaling vector is interpretable, composable, and keeps the matrix full-rank. It’s the set of fine-tuning knobs we should have had all along.
Anatomy of Transformer²
1. Singular-Value Finetuning (SVF)
To forge each “expert” vector z, the authors use reinforcement learning. The objective function effectively rewards the model for producing good answers (r(y)) while using a KL-divergence term as a leash, ensuring the adapted model π(θ_W') doesn’t stray too far from the base model’s π(θ_W) sanity. The only update is elegant:
.
2. The Dispatcher: The Brains of the Operation
- Prompt Engineering: The simplest route. Just ask the model to classify its own task:
code,math,reasoning, etc. - Classification Expert: A slightly smarter approach. A dedicated, SVF-tuned classification head does the routing.
- Few-shot CEM: The most powerful option. Treat the mixture weights of the experts as a search problem, optimizing them on-the-fly against a few examples from the prompt itself.
3. Two-Pass Execution: Diagnose, then Prescribe
- Pass 1 (Diagnose): The model analyzes the prompt and the dispatcher chooses or mixes the expert vectors to create the optimal weights
W'for the task at hand. - Pass 2 (Prescribe): The model executes the prompt using the newly adapted weights
W'to generate a superior answer.
Reproducing the Paper in 30 Lines
The elegance translates to practice. Getting this running is trivial.
# ── setup ──────────────────────────────────────────────────
# You'll need the repo's library and a base model
!pip install self-adaptive-llms transformers acceleratefrom transformers import AutoModelForCausalLM, AutoTokenizer
from self_adaptive_llms import load_svf, two_pass_infer
model_id = "meta-llama/Meta-Llama-3-8B-Instruct"
base = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto")
tok = AutoTokenizer.from_pretrained(model_id)
# Load pre-trained SVF experts (math / code / reasoning)
# These are just tiny scaling vectors
experts = {
"math": load_svf("experts/math.svf"),
"code": load_svf("experts/code.svf"),
"reasoning": load_svf("experts/reasoning.svf")
}
prompt = "Write a Python function that computes the nth Fibonacci number."
# The two_pass_infer function handles the routing and adaptation
print(two_pass_infer(base, tok, prompt, experts))The helpers load_svf and two_pass_infer are just thin wrappers around the repository’s core logic.
How Well Does It Work?
The numbers, pulled from their paper, speak for themselves.
| Backbone | Params Added | GSM8K ↑ | HumanEval ↑ | ARC-Chal ↑ | TextVQA ↑ |
|---|---|---|---|---|---|
| Llama-3 8B (base) | – | 75.9 | 61.0 | 80.6 | 31.4 |
| + LoRA | 6.8 M | 77.2 | 52.4 | 81.1 | 32.1 |
| + SVF | 0.58 M | 79.2 | 63.0 | 82.6 | 43.7 |
Numbers from the authors’ Table 1 & 2.
- The performance on vision-language tasks is where it gets really interesting: applying language-only experts still boosts scores on OK-VQA by a staggering 12 points. This suggests the “skills” are more abstract than their training domain.
- The training budget is just as compelling: SVF required less than 10% of the GPU-hours that LoRA demanded on the authors’ hardware.
Strengths
- Anorexic Adapters: A 70B Llama model needs less than 1MB of extra parameters per expert. That’s super efficient.
- Seeing the Levers: Because singular vectors often align with semantic concepts, you can actually interpret what you’re tuning. You’re dialing up “mathiness” or “code-awareness.”
- Portable Genius: In a surprising twist, experts trained on Llama-3 can be directly applied to Mistral-7B without retraining and still yield a small but measurable performance boost.
- Context Without the Cost: Unlike stuffing prompts with few-shot examples, the adaptation happens behind the scenes. The context window isn’t bloated with boilerplate.
Limitations & Open Questions
Every elegant solution has its edge cases. Here’s where the skepticism is warranted.
| ⚠️ | The Uncomfortable Truth |
|---|---|
| The Search-Time Tax | The CEM search over expert mixtures is cheap for a few shots, but it’s a one-time search. It’s unclear how this scales if you need to adapt to hundreds of micro-domains in real time. |
| The Routing Bottleneck | The whole system is only as smart as its dispatcher. A routing error sends the wrong specialist to the job. The paper’s confusion matrices still show a 3-5% mis-route rate, which is a non-trivial source of failure. |
| Garbage In, Amplified Garbage Out | SVF relies on amplifying capabilities that are already latent in the model. If your base model is weak or lacks a certain skill entirely, there’s nothing to amplify. |
| You Can’t Teach an Old Dog New Facts | Unlike a full finetune or even a LoRA, SVF cannot inject new knowledge. It can only remix and re-prioritize what the model already knows. |
When Should You Consider Transformer²?
- Enterprise & Multi-Tenant Systems: This is the obvious one. Serve hundreds of clients from a single model instance, using isolated, auditable, and cheap-to-store expert vectors for each.
- Edge Deployments: When your memory footprint is everything and on-device finetuning is a fantasy, shipping a few lightweight expert vectors is the only sane path.
- The Future of Continual Learning: This is the most exciting frontier. SVF vectors feel like composable “skills.” Can we evolve them? Combine them? Prune them? This is a rich playground for research.
Roadmap & Community Momentum
A GitHub repo crossing 1,000 stars in its first week is a signal that a nerve has been struck. The issue tracker is already buzzing with activity:
- 🖼 Multimodal Adapters: Volunteers are already working on SVF for audio and other vision tasks.
- 🔄 Faster Kernels: A pull request is in for a JAX-based
vmapimplementation of the CEM search, which should speed things up considerably. - 🧩 Model Merging: People are experimenting with merging SVF-adapted checkpoints, using tools like MergeKit to create broader, more capable experts from narrow ones.
Expect this to evolve rapidly, especially with the ICLR 2025 deadline looming.
Final Thoughts
Transformer² is the most elegant take on model adaptation I’ve seen this year. It moves beyond the brute-force approach of bolting on more parameters and instead embraces the idea of dynamically re-configuring the intelligence that’s already there. It treats expertise not as a static add-on, but as a first-class, composable object.
If you’re juggling multiple domains, modalities, or customers, this is more than just another paper to read. It’s a recipe to try. You might just find that your model already knows what to do-it was just waiting for you to turn the right knobs.