1. Why another reasoning paper?
The emergence of Large Reasoning Models (LRMs) like o1-preview and DeepSeek-R1 presented the community with a paradox: breathtaking capability shrouded in a black box of immense cost and proprietary data. The how remained an expensive mystery, accessible only to a small priesthood of well-capitalized labs.
This collaboration between Berkeley and Anyscale cuts through the mystique with a refreshingly pragmatic question:
Can we teach an open-source model to reason like a top-tier LRM, not by feeding it a universe of facts, but simply by showing it the choreography of complex thought?
The answer, it turns out, is a resounding yes.
2. The core hypothesis
The central thesis is that the global logical skeleton of a Chain-of-Thought (CoT) demonstration is what truly matters. The model isn’t memorizing arithmetic; it’s internalizing a sequence of valid logical moves-a kind of intellectual muscle memory.
If we view the learning process through the lens of a loss function, , at each token position t, the authors argue that the most valuable signal comes from the structural integrity of the reasoning chain, not the semantic correctness of each individual token.
Here, represents an indicator of structural consistency. The model is rewarded for learning how one step follows another, creating a coherent argument, regardless of the fine-grained details.
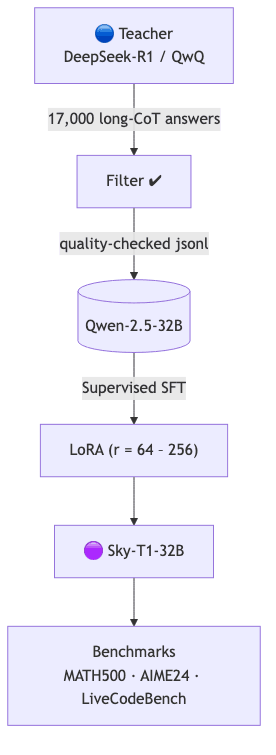
3. Distillation pipeline
Minimal training command
pip install skythought[train]
skythought.train \
--base_model Qwen/Qwen2.5-32B-Instruct \
--dataset r1-17k.jsonl \
--lora_r 128 --lora_alpha 256 \
--epochs 2 --batch_size 96 --lr 1e-4 \
--wandb_run "sky-t1-replica"Cost: 6 × A100 80 GB for 14 h ≈ $450 at current spot rates. An insultingly low price for this level of capability transfer.
4. Results at a glance
| Benchmark | Base Qwen‑2.5‑32B | +Long‑CoT SFT | +LoRA | OpenAI o1‑preview |
|---|---|---|---|---|
| MATH‑500 | 81.4 | 90.8 | 90.6 | 85.5 |
| AIME 2024 | 16.7 | 56.7 | 57.0 | 44.6 |
| AMC 2023 | 67.5 | 85.0 | 82.5 | 87.5 |
| OlympiadBench | 47.6 | 60.3 | 60.0 | 59.5 |
| LiveCodeBench | 48.9 | 57.0 | 56.2 | 59.1 |
A 40-point leap on AIME from just 17k examples is a testament to the sheer efficiency of teaching structure over raw knowledge.
5. Ablations: content vs. structure
| Perturbation | Δ AIME accuracy |
|---|---|
| Corrupt 50% digits | ‑3.3% |
| Wrong final answer | ‑3.2% |
| Remove all “Wait/But/Alternatively” tokens | ‑3.3% |
| Shuffle 67% of reasoning steps | ‑13.3% |
| Delete 100% of steps (keep final solution) | ‑27.4% |
The numbers tell a story as clear as day. The model can tolerate flawed content, but it cannot tolerate flawed logic. It learns rhetoric, not reality. Syntax, for the purpose of teaching reasoning, trumps semantics.
6. Ecosystem impact
- SkyThought repo (3.3k ★, 327 forks) provides code, training, evaluation, and even a Colab template for immediate experimentation [GitHub].
- The work has already inspired a wave of community reproductions and extensions, signaling a healthy, functioning open-source ecosystem.
- Academic consensus is shifting. This paper is now cited as key evidence that imperfect, structurally-sound demonstrations are remarkably effective teachers.
7. Limitations & open questions
- Generalisation beyond STEM. The focus on math and code is a natural starting point, but can this method teach nuanced legal or philosophical reasoning? Early MMLU results are modest, suggesting this is not a silver bullet for all domains.
- Inference-time verbosity. Teaching a model to “show its work” with long CoTs inherently increases latency. While follow-up work is exploring how to make reasoning more concise, the trade-off between clarity and speed persists.
- The risk of plausible nonsense. A model that masters the form of reasoning without deeply grounding in content is dangerous. It can generate arguments that sound persuasive but are fundamentally wrong. This elevates the need for robust, external verifiers from a “nice-to-have” to an absolute necessity.
8. Reproducing the findings
The SkyThought repo provides ready-made 🍱 recipes for 7B, 14B, and 32B models. For those with access to a few high-end GPUs (4×H100) and a bit of storage, replicating the core findings is a weekend project. This is the new frontier: not just reading about breakthroughs, but recreating them.
Pro-tip: set
--gradient_checkpointingto keep VRAM consumption manageable and use a tool like Weights & Biases to monitor your tokens/sec.
9. Final thoughts
This paper serves as a potent reminder of a principle that transcends machine learning and touches the core of pedagogy itself: how you teach is often more important than what you teach.
For practitioners, the lesson is clear and empowering. You don’t need a trillion-token dataset or a nation-state’s budget to build a powerful reasoning engine. Curate a small, structurally rich dataset, apply LoRA adapters with surgical precision, and you can create a model that rivals the giants.
The ability to reason is being democratized. Build accordingly.