Why GGUF?
GGUF is the answer to a question of pure pragmatism. It’s the binary container format for the GGML/llama.cpp ecosystem. It bundles everything-vocabulary, weights, metadata-into a single, self-contained artifact. This allows a model to be memory-mapped and streamed directly from disk with zero ceremony and zero extra tooling. No Python venv, no dependency hell. Just a model, ready to run. GGUF itself is not a quantizer; it is merely the vessel for the precision you choose to store.
K-Quantisation in a Nutshell
The elegance of K-Quantization (“K-Quants”) lies in its hierarchical attack. It doesn’t just club the whole tensor into submission. It carves the weights into super-blocks, which are then carved into smaller sub-blocks. This nesting allows for a more granular application of quantization, applying a tailored (scale, min) straitjacket to each piece.
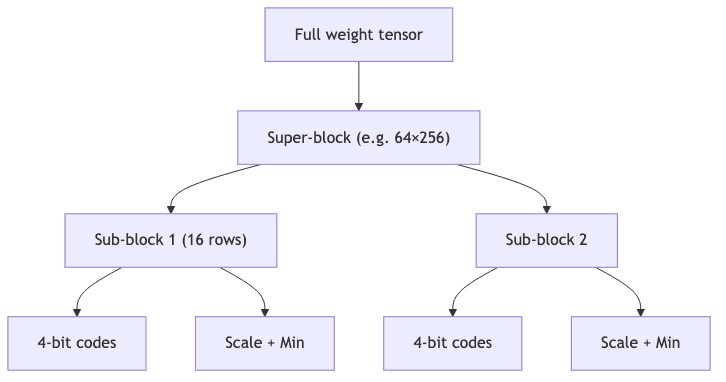
Each sub-block’s (scale, min) pair is packed into 8 bits or less, a design choice that enables brutally fast dequantization using SIMD instructions during inference.
The CLI Incantation
# Standard K-Quant
./llama.cpp/llama-quantize fp16.gguf q4_k_m.gguf Q4_K_M
# …or with an importance matrix
./llama.cpp/llama-quantize --imatrix imatrix.dat fp16.gguf q4_k_m_i.gguf Q4_K_MWhy Some Weights Matter More: The Importance Matrix
The premise that all weights are created equal is demonstrably false. Some parts of the neural substrate do more work than others; they fire more frequently or have an outsized impact on the final loss. Quantizing everything with the same blind force is wasteful.
The importance matrix (imatrix) is the tool for identifying this cognitive aristocracy.
- The
llama-imatrixtool performs a forward pass on a calibration corpus (a few thousand lines of representative text, like Wikipedia). - It records which weights are most “important” during this pass and writes a binary bitmap marking these high-value positions.
- In the subsequent quantization step, these marked weights are treated with more respect-either skipped or quantized to a higher precision (e.g., 8-bit)-preserving accuracy where it is most critical.
End-to-End Walk-through with Gemma-2 2B
1 · Forge the Tools
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp && GGML_CUDA=1 make && pip install -r requirements.txt2 · Procure and Prepare the Specimen
from huggingface_hub import snapshot_download
model_repo = "google/gemma-2-2b-it"
snapshot_download(model_repo, local_dir="hf_model", local_dir_use_symlinks=False)
!python llama.cpp/convert_hf_to_gguf.py hf_model --outfile fp16.gguf3 · Assemble Calibration & Evaluation Corpora
wget -q https://object.pouta.csc.fi/OPUS-Wikipedia/v1.0/mono/en.txt.gz
gunzip en.txt.gz && head -n 10000 en.txt > wiki_cal.txt
bash llama.cpp/scripts/get-wikitext-2.sh # -> wikitext-2-raw/4 · Compute the Importance Matrix
./llama.cpp/llama-imatrix -m fp16.gguf -f wiki_cal.txt -o imatrix.dat -ngl 995 · Quantise (With and Without the Matrix)
for m in Q4_K_S Q4_K_M; do
./llama.cpp/llama-quantize fp16.gguf ${m}.gguf $m
./llama.cpp/llama-quantize --imatrix imatrix.dat fp16.gguf ${m}_I.gguf $m
done6 · Perplexity Check
Perplexity is a measure of a model’s confusion. Lower is better. It quantifies how “surprised” a model is by a sequence of text. The formula is stark:
And the command to compute it is simple:
./llama.cpp/llama-perplexity -m Q4_K_M.gguf -f wikitext-2-raw/wiki.test.raw7 · CPU Throughput Benchmark
make clean && make # re-compile llama.cpp **without** CUDA
./llama.cpp/llama-bench -m fp16.gguf -m Q4_K_M.gguf -m Q4_K_M_I.gguf \
-m Q4_K_S.gguf -m Q4_K_S_I.gguf -n 128,256,512Note on Gemma-2 2B Model Data: The GGUF files for the Gemma-2 2B model (FP16, Q4_K_M, Q4_K_S, and their imatrix variants) used for the perplexity and throughput benchmarks reported below were sourced from community-provided pre-quantized models (derived from the official Gemma-2 2B). The official base GGUF from Google, google/gemma-2-2b-it-GGUF (a 10.5 GB FP16 GGUF), can be found on Hugging Face. The following results reflect performance using these specific community-quantized GGUF files.
Results
| Variant | File size (MiB)† | WikiText-2 perplexity | Throughput (tok/s, CPU)†† |
|---|---|---|---|
| FP16 | 6111 | 8.9 | 9.5 |
| Q4_K_S | 2016 | 9.3 | 19.9 |
| Q4_K_S + imatrix | 2016 | 9.2 | 19.8 |
| Q4_K_M | 2088 | 9.2 | 18.4 |
| Q4_K_M + imatrix | 2088 | 9.1 | 17.1 |
†File sizes as reported by llama-bench tool (converted from GiB to MiB). ††Throughput (tok/s) on a mid-range desktop CPU.
Observations
- The first, most brutal win is a ~3x reduction in the model’s disk and memory footprint. This is table stakes.
- The ‘M’ (medium) variant,
Q4_K_M, costs you an extra ~70 MiB but consistently buys back perplexity points, inching closer to the FP16 baseline. A reasonable price to pay. - The
imatrixis the real hero. For a near-zero cost in file size, it reliably shaves 0.1-0.15 points off the perplexity score. It’s the closest thing to a free lunch in this domain. - This precision doesn’t come for free. The imatrix variants trade ~1-2 tok/s of throughput for their improved accuracy. A classic engineering trade-off.
Practical Tips
- Isolate the Compute-Intensive Step. The
llama-imatrixcalculation is a one-off, embarrassingly parallel forward pass. Offload it to any CUDA-capable GPU you can find. Let the silicon do the grunt work. - Calibrate on a Relevant Corpus. The
(scale, min)0 learns what’s important from what you show it. Don’t feed it Wikipedia if you’re building a code-gen bot. Garbage in, garbage out. - Mind the Build Environment. Compiling large models with full optimizations (
(scale, min)1) and CUDA support is memory-hungry. Don’t be surprised if it eats >8GB of RAM. Use(scale, min)2 to offload BLAS operations if your system groans under the load. - Don’t Crush the Gnats. For tiny models (<1B parameters), aggressive quantization can be counterproductive. The overhead from the quantization metadata can begin to outweigh the benefits.
Closing Thoughts
The notion of running a multi-billion-parameter intelligence on a device powered by a battery was, until recently, absurd. Now, it’s a weekend project. This represents a fundamental shift in accessibility. The power to run, inspect, and modify these artifacts is no longer the exclusive domain of hyperscalers.
The workflow above is model-agnostic-I’ve repeated it for Llama-3 8B and Phi-3 Mini with similar gains. It demonstrates that the most significant barriers are often not a lack of compute, but a lack of applied ingenuity. Give it a spin, measure your own corpora, and see how far you can stretch those CPU cycles.
Happy hacking,