Key Takeaways
- Quadratic attention is the wall. For contexts beyond a few thousand tokens, it becomes an intractable computational demon. SPECTRE sidesteps this entirely, mixing tokens in the frequency domain with an almost insultingly efficient
complexity.
- Each attention head is surgically replaced with a single real FFT – spectral gate – inverse FFT trio. This makes it a drop-in transplant for existing Transformer checkpoints, not a ground-up architectural rewrite.
- A Prefix-FFT cache, an elegant echo of the classic KV-cache, enables constant-time autoregressive decoding while retaining full global context. The ghost of linear-growth latency has been exorcised.
- An optional Wavelet Refinement Module (WRM) acts as a scalpel, restoring the fine-grained locality that the broadsword of pure Fourier mixing can sometimes blur, all at negligible overhead.
- Empirically, SPECTRE doesn’t just keep up; it laps FlashAttention-2. At 128k tokens, it runs up to 7× faster – on commodity GPUs, no less.
1. Why Another Attention Alternative?
As sequence lengths swell to biblical proportions – think book-length summarisation, sprawling multi-turn dialogues, or 8K-token images – the quadratic cost of self-attention () becomes a tyrant, straining memory and latency to breaking points. The last few years have produced a menagerie of fixes: sparse kernels (Longformer), kernel tricks (Performer, Linformer), structured state spaces (Mamba), and IO-optimized exact kernels (FlashAttention-2). SPECTRE walks a different path, one paved by Cooley and Tukey back in 1965: frequency-domain mixing. And crucially, it does so adaptively, not with a fixed, blind filter like the early FNet.
2. The Core Idea in Two Lines
The core mechanism is almost painfully elegant.
- RFFT projects each head’s value matrix
onto the timeless, orthonormal Fourier basis.
- A content-adaptive diagonal gate
– produced by a tiny MLP that digests a global query descriptor – modulates each frequency component. This is the “smart” part.
- Inverse RFFT returns the mixed values to token space. And because the inputs are real, we only need to store
coefficients, thanks to Hermitian symmetry.
The complexity per head becomes for time and memory. In the real world, for any non-trivial
, this is functionally near-linear.
3. Architecture at a Glance
The data flow is clean, almost classical.
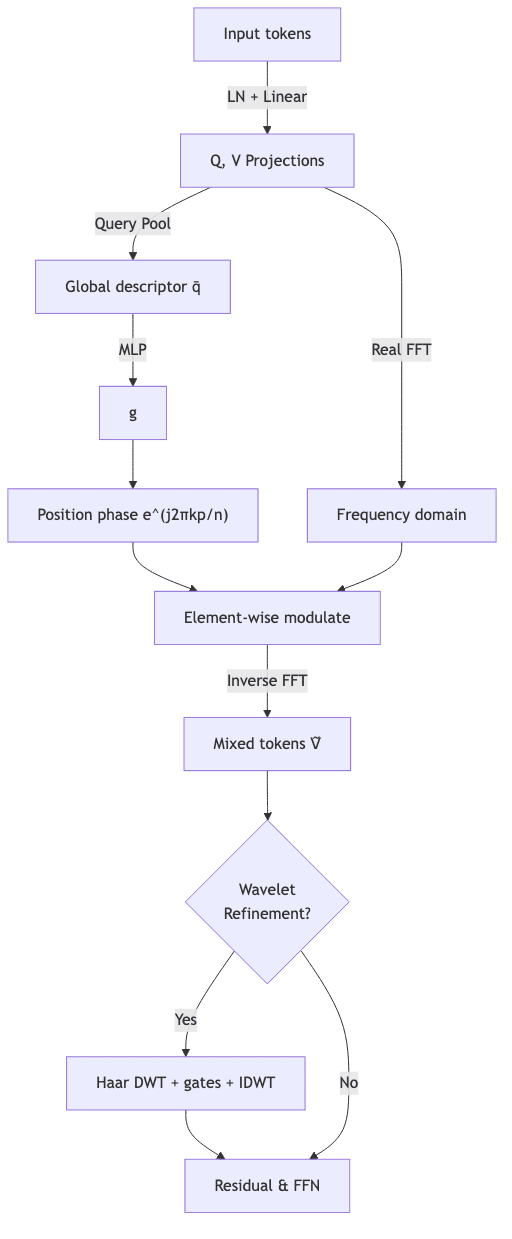
The WRM branch is a scalpel, not a sledgehammer, triggered only ~10% of the time to keep the average compute cost brutally low.
4. Prefix-FFT Cache: Streaming Without the Quadratic Penalty
This is where the engineering brilliance truly shines. During decoding, standard attention caches swell linearly with context length, slowing generation to a crawl. SPECTRE sidesteps this by caching non-redundant RFFT coefficients instead of raw key/value pairs.
- Prefill: A single, padded
-point RFFT over the initial prompt. This costs
, a one-time affair.
- Decode: For each new token, updating the cached spectrum requires just two complex multiplies per frequency bin. This is constant-time, slaying the beast of linear-growth latency regardless of the total context length.
In practice, time per output token (TPOT) plummets to 15µs, a full four times faster than FlashAttention-2 at a 32k context.
5. How Well Does It Work?
So, does this spectral sleight of hand actually work? The empirical results are brutal.
| Task / Metric | Baseline | SPECTRE | Speed‑up |
|---|---|---|---|
| PG‑19 perplexity | 39.4 (SDPA) | 39.0 (+WRM) | 3.3× throughput |
| ImageNet‑1k Top‑1 | 79.1 % (ViT‑B) | 79.6 % | 3× img/s |
| Latency @ 32 k | 97 ms (FA‑2) | 32 ms | 3× |
| Latency @ 128 k | 2 820 ms (FA‑2 est.) | ≈400 ms | ≈7× |
Numbers condensed from the paper; tests use a single NVIDIA A100-80GB.
6. Quick Start from GitHub
The authors, refreshingly, provide a clean reference implementation. No arcane rituals required.
from model import SpectreLM
lm = SpectreLM(
vocab_size=50257,
max_seq_len=128_000, # yes, that big
d_model=768,
n_layers=12,
n_heads=12,
use_wavelet=True,
)
logits, _ = lm(input_ids) # identical API to a HuggingFace GPT‑style modelThe repository also includes a PrefixFFTCache for constant-time generation and a SpectreViT vision backbone, demonstrating the idea’s portability.
7. Strengths & Limitations
👍 Pros
- No architectural butchery – it’s a drop-in replacement. You can fine-tune just the new gates, which constitute less than 6% of the parameters.
- Hardware-friendly – it leverages battle-hardened FFT kernels that have been optimized for decades, not some exotic, bespoke CUDA nightmare.
- Scales gracefully – latency remains stubbornly flat up to 32k tokens and beyond, laughing at context length.
👎 Cons / Open Questions
- The ghost of frequency aliasing on extremely long texts could blur subtle local patterns if the WRM is disabled. The universe is not perfectly sinusoidal.
- The paper whispers of gradient clipping for training very deep stacks (≫24 layers), suggesting that careful stabilization may be required at the far end of the scale.
- While constant-time, the per-token decode still touches a full
complex vector. Fused CUDA kernels or other specialized implementations could push this even further into absurd territory.
8. Relation to Contemporary Work
Where does SPECTRE fit in the crowded landscape of attention-slayers?
| Category | Representative | Complexity | Adaptive? | Caching |
|---|---|---|---|---|
| IO-optimised exact | FlashAttention-2 | ✔ | KV-cache | |
| Kernel approx. | Performer | ✔ | KV-cache | |
| State space | Mamba | – | Rolling state | |
| Spectral (SPECTRE) | This work | ✔ | Prefix-FFT |
SPECTRE carves out a compelling middle ground: it provides exact global mixing like attention, but at a sub-quadratic cost, and with a caching mechanism as simple and effective as the original KV scheme. It’s a pragmatic marriage of theoretical purity and engineering reality.
9. Final Thoughts
I’m genuinely impressed by how SPECTRE resurrects the FFT – a ghost from 1965, Cooley and Tukey’s masterstroke – for modern sequence modeling. It feels like finding a Roman aqueduct that, with minor retrofits, can outperform modern infrastructure. The Prefix-FFT cache in particular is a highlight: it marries spectral theory with practical engineering to deliver truly interactive long-context generation on hardware that most of us can actually access.
This method isn’t the final word on efficient transformers; the path forward likely involves hybrid mixers and learned, non-Fourier bases. Yet, for anyone wrestling with 64k-token prompts today, SPECTRE already offers a powerful, elegant, and shockingly effective solution. It proves that sometimes the most futuristic solutions have been hiding in plain sight for over half a century.
Give the repo a spin. See what ghosts you can summon.