The Reasoning Tax
Models that can actually think-the ones capable of chain-of-thought, self-correction, and genuine problem-solving-come with a hidden, punitive tax. Every step in a complex reasoning chain bloats the key-value (KV) cache, the model’s short-term memory. This isn’t a minor inconvenience; it’s a fundamental bottleneck. A model that generates a 30,000-token proof is, by its very design, strangling itself, devouring GPU memory and grinding throughput to a halt.
R‑KV – a redundancy-aware KV-cache compression method from Zefan Cai et al. (arXiv, GitHub) feels less like an incremental improvement and more like a necessary antidote. It’s a way to stop paying the reasoning tax. Here’s the breakdown of why it works and why it matters for anyone deploying thinking models in the real world.
The Bottom Line
- Radical Amputation, Not a Diet: R-KV can discard 90% of the KV cache while maintaining full accuracy on tough math-reasoning benchmarks.
- Pure Algorithmic Leverage: It’s completely training-free. You don’t touch the weights. It slots directly into your existing inference loop.
- Importance ➕ Redundancy: A joint score,
, weaponizes this distinction, explicitly punishing semantic clones.
- The Hardware Leash is Cut: Compression is dynamic. The cache never grows beyond a fixed budget, letting the model think for as long as it needs to without needing more hardware.
The Architectural Sin of the KV Cache
The explosion of the KV cache during autoregressive decoding is a self-inflicted wound. Every new token generated requires the model to attend over the entire history of key/value pairs. For a model like DeepSeek-R1 generating a 30k-token proof, a single inference can scarf down 4 GB of VRAM on an 8B parameter model, just for the cache. Longer thoughts mean linearly more memory and latency. It’s a naive architecture that simply doesn’t scale.
Previous attempts to fix this-PyramidKV, SnapKV-relied on a single, flawed heuristic: attention scores. Keep the tokens that were recently looked at the most. This is a blunt instrument. In complex reasoning, it preferentially keeps repetitive self-checks and internal monologues while potentially dropping a critical fact or premise mentioned thousands of tokens ago. It mistakes noise for signal. R-KV is smarter.
How R-KV Works
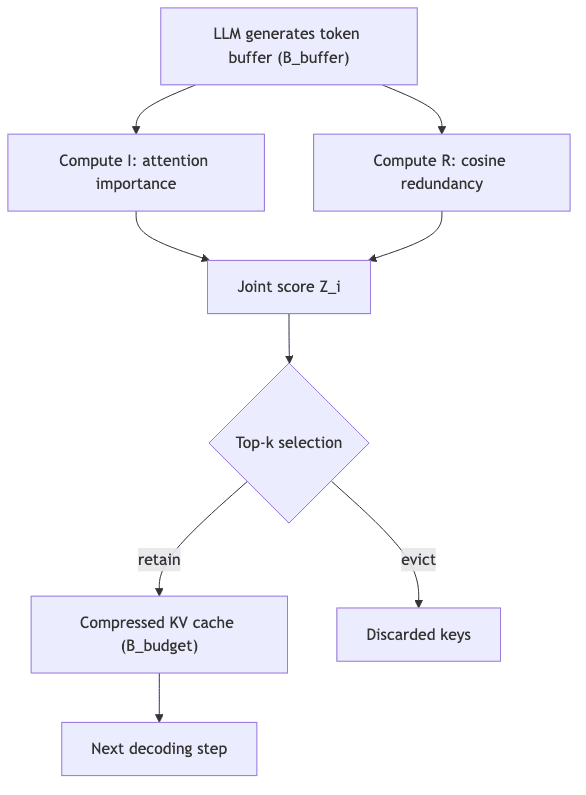
1. Decoding-Time Segmentation
R-KV operates with two fixed memory blocks:
- Buffer
(typically 128 tokens) catches the newest key/value pairs as they’re generated.
- Budget
is the fixed-size compressed history the model actually keeps.
Once the buffer is full, a selection process kicks in to decide what survives.
2. Attention-Based Importance 
For each key in the cache, the system calculates an importance score by averaging its attention weight across the last few queries. This asks the question: “What has the model found interesting recently?”
A local max-pooling window
smooths out noisy, spiky attention heads.
3. Redundancy Score 
This is the clever part. R-KV computes the cosine similarity between all key vectors. Tokens that are semantically similar to many others get a high redundancy score. It asks: “What has the model already said, just in different words?” To avoid deleting the most recent thoughts, the last few redundant tokens are spared.
4. Joint Selection
The final score combines both ideas. The elegance is in the subtraction. The tokens with the highest Z-scores-important but not repetitive-are kept, forming the compressed cache for the next step.
Remarkably, a single hyperparameter, λ=0.1, works consistently well across different models.
Hands-On Example
This isn’t theoretical. Bolting R-KV onto a standard HuggingFace model is trivial. Notice the lack of ceremony-no new weights, no fine-tuning. Just better cache management.
from rkv import RKVCacher # pip install rkv
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "deepseek-ai/deepseek-math-7b-instruct"
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype="auto")
tok = AutoTokenizer.from_pretrained(model_id)
cacher = RKVCacher(model, buffer_size=128, budget_size=1024, alpha=8, lambda_=0.1)
prompt = "Solve and explain: If 20% of a class of 30 are football players..."
inputs = tok(prompt, return_tensors="pt").to(model.device)
for step in range(4096):
out = model(**inputs, use_cache=True, past_key_values=cacher.kv)
next_token = out.logits[:, -1].argmax(-1)
cacher.update(next_token, out.past_key_values) # compress on‑the‑fly
if next_token.item() == tok.eos_token_id:
break
inputs = {"input_ids": next_token.unsqueeze(0)}The Payoff
| Dataset | Model | KV budget | Accuracy Δ | Memory saved |
|---|---|---|---|---|
| MATH‑500 | DeepSeek‑R1‑Llama‑8B | 10 % | –0.5 pp | 90 % |
| AIME 24 | DeepSeek‑R1‑Qwen‑14B | 25 % | +0.8 pp | 75 % |
The numbers on accuracy are impressive, but the real payoff is throughput. At a context length of 16k tokens, R-KV allows a single A100 to batch 9× more requests than a full, uncompressed cache. This translates to a raw 6.6× speedup. That’s the kind of leverage that changes the economics of deployment.
Positioning Against the Old Guard
- SnapKV and other attention-only methods now look primitive. They stumble badly on reasoning tasks, with accuracy collapsing to ~60% at a 10% cache budget because they can’t distinguish between repetition and importance.
- Lexico and Q-Filters are interesting but solve a different problem. They focus on compressing the initial prompt (prefill) and don’t address the compounding garbage generated during a long chain-of-thought.
- R-KV is the only one playing the right game: tackling CoT redundancy as it happens. It requires no changes to model weights and works seamlessly with optimized kernels like FlashAttention.
Practical Guidelines
- Don’t be a hero. Start with a conservative budget, like
for a 7-14B model. Measure your accuracy baseline, then shrink it. You can almost always go smaller.
- Find your λ, then leave it alone. A value between 0.05 and 0.15 is usually the sweet spot. Higher values give too much weight to noisy attention scores.
- Mind the overhead. The compression step has a cost,
. But since your budget is designed to be much smaller than the full sequence length, this cost is dwarfed by the savings in the main attention calculation.
- Don’t touch alpha. Always keep the last
tokens (default is 8). This is your guard rail against factual inconsistency. Lowering it is asking for trouble.
Limitations & The Next Frontier
This isn’t a silver bullet. The map still has uncharted territory.
- Integration with advanced schedulers like PagedAttention is not yet implemented.
- The cosine redundancy check assumes key embeddings are isotropic, but semantic space can drift during very long dialogues, which might fool the metric.
- The current implementation applies a single budget for the whole model. Per-layer or even per-head budgeting could unlock further gains. This is fertile ground for community contributions.
Final Thoughts
Let’s be clear. R-KV isn’t just another cache compressor. It’s the first one built with the right philosophy for the new wave of models that actually think. If you’re building, training, or serving models like DeepSeek-R1, Kimi, or Gemini, this is one of the biggest, easiest wins on the table this year.
Stop paying the reasoning tax. Shrink the cache, keep the brains.