Introduction
The hunger of Large Language Models (LLMs) for context – the ability to ingest and process ever-longer sequences of text – feels like one of the defining battles of this AI era. We see models like GPT-4, Claude, and LLaMA pushing boundaries, but the maximum context length they can handle dictates the very scope of their understanding and application. It’s the difference between a digital goldfish forgetting the start of a sentence and an AI capable of grasping the nuance of a novel or the complexity of sprawling codebase.
This piece dives into the messy reality of scaling context. We’ll dissect the technical hurdles, survey the arsenal of tricks and genuine innovations deployed to overcome them, and weigh the unavoidable trade-offs. Whether you’re building atop these giants or digging into the architectural bedrock, understanding this struggle is key to navigating where LLMs are headed.
1. Why Context Length Matters
1.1 Definition of Context Length
Let’s be precise. Context length (or context window) is the hard limit on the number of tokens an LLM can chew on in a single pass – both input prompt and its own generated output. A 2,048-token window means token 2,049 simply falls off the edge of the model’s world.
Think of it as the model’s effective short-term memory. It dictates how much history, how much evidence, how much world the model can perceive simultaneously.
1.2 Impact on LLM Capabilities
Why chase longer context? Because it unlocks fundamentally different capabilities:
- Tackling the Unwieldy: Summarizing entire books, analyzing lengthy legal documents, engaging in conversations that span hours or days, grokking thousands of lines of code – these tasks demand more than a fleeting memory.
- Escaping Digital Amnesia: Short context breeds incoherence. Models forget names, instructions, the plot. Longer context allows for genuine coherence, tracking long-range dependencies, and maintaining consistency.
- Weaving Complex Thought: Real reasoning often involves synthesizing information scattered across a wide expanse. Sufficient context is the canvas required for these more intricate cognitive feats.
But this power doesn’t come free. The computational universe imposes harsh taxes.
2. The Fundamental Challenge: Quadratic Attention Complexity
2.1 Understanding the O(N²) Problem
The culprit behind the context length struggle is the heart of the standard Transformer architecture: the self-attention mechanism. Its mathematical expression is elegant:
But baked into this elegance is a brutal reality. To figure out how much each token should “attend” to every other token, the model computes an attention score matrix for
input tokens. This means both memory footprint and computational cost explode quadratically as sequence length (
) increases. This
scaling is the unforgiving computational wall we keep slamming into.

Think about it: doubling context from 2K to 4K tokens means 4x the attention cost. Jumping to 32K tokens? That’s a 256x hit compared to 2K. The hardware simply buckles under this pressure.
2.2 Memory vs. Computation Trade-offs
The tyranny of the square hits us in two ways:
- Memory Bottleneck: Just storing those massive
matrices can overwhelm even beefy GPU memory.
- Compute Bottleneck: Even if you could store it, the sheer number of calculations skyrockets, making inference slow and training prohibitively expensive.
This fundamental constraint is a physics-like limitation driving the search for clever workarounds and alternative architectures.
3. Window and Local Attention Approaches
3.1 Core Concept of Local Attention
Faced with the wall, one pragmatic retreat is window attention (or local attention). The core idea is simple: assume, perhaps optimistically, that a token mostly needs to pay attention to its immediate neighbors. Instead of global visibility, each token
only looks at tokens within a fixed-size window
.

You sacrifice global vision for local clarity, betting that most meaning is made locally. This is often a reasonable gamble in natural language.
3.2 Prominent Local Attention Architectures
This core idea has spawned several influential architectures:
- Longformer (Beltagy et al., 2020): A hybrid approach. Most tokens use sliding windows, but designated “global” tokens (like special markers or task-critical positions) retain full visibility. A compromise seeking the best of both worlds.
- BigBird (Zaheer et al., 2020): Employs a clever mix of attention patterns: random connections, local windows, and global tokens. It aims to approximate the connectivity of full attention with linear scaling.
- Swin Transformer (Liu et al., 2021): Born in computer vision but influential in NLP, Swin uses hierarchical windows that shift across layers, enabling information to propagate across local boundaries over depth.
3.3 Advantages and Limitations
Advantages:
- Slashes memory complexity from the brutal (O(N^2)) to a manageable (O(N \times w)).
- Relatively easy to bolt onto existing Transformer setups.
- Plays well with parallel processing on modern GPUs.
- Effective when the “locality assumption” holds true.
Limitations:
- Directly modeling long-range dependencies becomes difficult or impossible without extra tricks.
- Finding the “right” window size (
) is often task-dependent guesswork.
- Can falter on tasks demanding true global understanding or synthesis across distant points.
For many applications, the efficiency gains outweigh the loss of global context, making local attention a workhorse technique.
4. Streaming LLM Approaches for Unlimited Context
4.1 The Streaming Challenge
Local attention extends the window, but what about tasks that are effectively infinite? Live conversations, real-time monitoring, processing endless log files – these demand a different philosophy. Fixed windows, however large, eventually overflow.
Streaming LLM techniques don’t try to hold everything at once. Instead, they process text in manageable chunks, passing relevant state forward like a baton in a relay race.
4.2 Transformer-XL and State Recurrence
Transformer-XL (Dai et al., 2019) pioneered this with segment-level recurrence:
- Process chunk #1 (segment).
- Cache key internal states (hidden activations, key/value pairs) from this chunk.
- When processing chunk #2, inject these cached states, giving it memory of the past.
- Repeat, letting information theoretically flow across an infinite sequence.
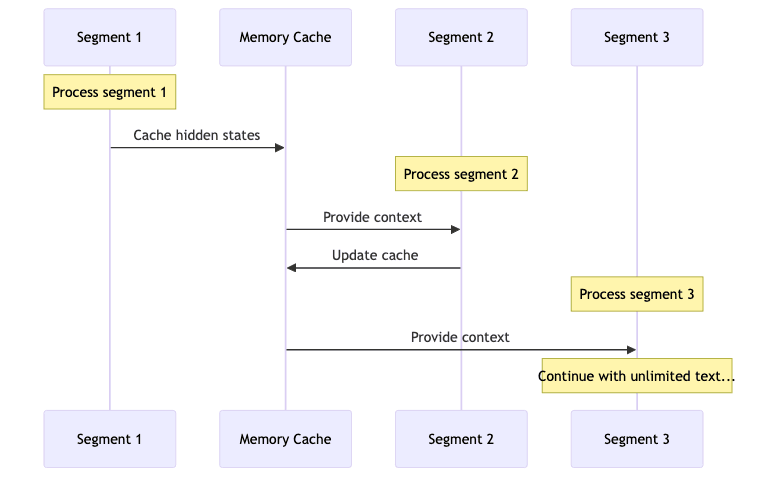
This allows the model to look beyond the current chunk without the quadratic cost of reprocessing the entire history.
4.3 Memory Tokens and Attention Sinks
Other streaming strategies focus on explicit memory mechanisms:
- Attention Sinks: Recent work showing that forcing attention to certain initial tokens (“sinks”) helps stabilize the model’s attention patterns when processing very long sequences in chunks, preventing catastrophic forgetting.
- Memory Tokens: Introducing special tokens whose embeddings are designed to act as a compressed summary of past context, updated as new information flows in.
- Recurrent Memory: Architectures explicitly blending Transformer layers with recurrent neural network components designed for long-term state maintenance.
4.4 Practical Considerations for Streaming LLMs
Streaming isn’t a free lunch. Key considerations include:
- Latency vs. Fidelity: Smaller chunks mean faster processing but risk dropping context between chunks. Larger chunks preserve more context but increase latency.
- State Management: Deciding what state to cache and pass forward is crucial and non-trivial.
- Training Complexity: Streaming models often need specific training procedures or fine-tuning to learn how to effectively use the recurrent connections or memory mechanisms.
Despite the hurdles, streaming represents the most viable path currently known for handling truly unbounded sequences.
5. Position Encoding Adaptations: The RoPE Case Study
5.1 Understanding Rotary Position Embeddings
Transformers, lacking inherent sequence awareness, need positional information injected. Rotary Position Embeddings (RoPE) emerged as an elegant and effective method, now popular in many leading LLMs.
Instead of adding positional vectors, RoPE rotates parts of the query and key vectors based on their position. For a dimension , pairs of coordinates
are rotated:
The angle is determined by the token’s position
.

5.2 Extending Context Through Frequency Scaling
The magic often lies in how is calculated, typically using frequencies:
Here, is the dimension index, and
is a base frequency scale. A key insight emerged: to make a model trained on, say, 2K context work reasonably well on 8K context, you can often just tweak
(usually making it smaller). This technique, often called “RoPE scaling” or “position interpolation,” effectively re-calibrates the positional sense of the model for longer sequences.
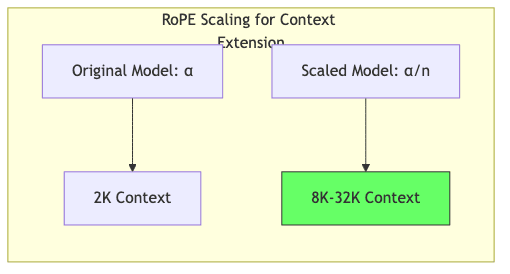
It’s almost disturbingly simple, yet surprisingly effective.
5.3 Implementation and Effectiveness
RoPE scaling has proven potent:
- Simple Scaling: Dividing
by a factor (like 2 or 4) often yields decent results for moderate context extensions.
- Fancier Scaling: Non-linear adjustments to
- Fine-tuning Helps: Even a small amount of fine-tuning on longer sequences after RoPE scaling can significantly solidify the gains.
- Model Dependent: Some architectures respond better to RoPE scaling than others.
The appeal is obvious: it’s often a post-hoc modification requiring minimal architectural surgery, sometimes even no retraining, making it a go-to trick for squeezing more context out of existing models. There’s an art to finding the right scaling factor.
6. Advanced Context Extension Techniques
6.1 Hierarchical Processing Approaches
Mimicking how humans tackle long texts, hierarchical methods process information at multiple scales:

- Local Processing: Use standard or window attention within small text chunks.
- Chunk Summarization: Generate condensed representations (summaries or embeddings) for each chunk.
- Global Processing: Apply attention over these chunk representations to capture document-level structure and meaning.
This creates levels of abstraction, allowing models to reason about massive documents without getting lost in the weeds.
6.2 Sliding Windows with Overlaps
A refinement on basic window attention is to make the windows overlap:

- Process the first window.
- The second window starts before the first one ended, including an overlapping region.
- Attention is computed within this new window.
- Repeat, sliding through the document.
The overlap provides continuity, smoothing the transitions between chunks and helping maintain coherence across window boundaries.
6.3 Efficient Implementation with FlashAttention
FlashAttention (Dao et al., 2022) isn’t strictly a context extension algorithm, but a masterclass in hardware-aware implementation that enables longer contexts. It tackles the memory bottleneck of attention computation:

- It avoids materializing the full
- Instead, it computes attention block-by-block, cleverly using the much faster on-chip SRAM.
- It computes the exact attention scores, just far more memory-efficiently.
FlashAttention dramatically reduces the memory footprint (though not the O(N²) compute complexity), making previously infeasible context lengths practical. It acts as a powerful enabler, often combined with other techniques like full attention (pushing its practical limit higher) or local attention (making them even more efficient).
7. Real-World Applications and Use Cases
The right tool depends on the job. Which context extension strategy fits which application?
7.1 Document Analysis and Summarization
Suitable approaches: Local + global attention (Longformer, BigBird), Hierarchical.
Why it works: Documents need both fine-grained detail (local attention) and high-level thematic understanding (global tokens or chunk representations).
Example implementation: Processing a 50-page research paper (approx. 25K tokens) to extract methodology, key findings, and limitations.
7.2 Conversational AI and Chat Systems
Suitable approaches: Streaming methods (Transformer-XL style), Attention Sinks.
Why it works: Conversations are inherently sequential and potentially unbounded. Recurrent state passing or maintaining key “sink” tokens allows context retention without quadratic cost over the entire history.
Example implementation: A chatbot that remembers user preferences and past interactions from conversations spanning multiple sessions over weeks.
7.3 Code Understanding and Generation
Suitable approaches: RoPE scaling + FlashAttention (for full visibility up to moderate lengths), Hierarchical approaches, potentially Local attention.
Why it works: Code often exhibits both local structure (within a function) and long-range dependencies (class inheritance, module imports). RoPE scaling retains full attention’s ability to capture arbitrary dependencies up to its limit, while hierarchical methods can handle larger codebases by abstracting components.
Example implementation: An AI pair programmer that analyzes a 15K-token file to suggest relevant completions or identify potential bugs based on dependencies across multiple functions and classes.
8. Comparative Analysis of Context Extension Methods
There’s no magic bullet; choosing involves understanding the trade-offs:
| Technique | Memory Usage | Global Context | Implementation Complexity | Typical Length Range | Best Use Cases |
|---|---|---|---|---|---|
| Full Attention + FlashAttn | (O(N^2)) (optimized) | Complete | Medium | 4K-16K+ | Tasks needing full global view, moderate length |
| Window/Local Attention | (O(N \cdot w)) | Limited | Medium | 8K-32K+ | Document processing where locality dominates |
| Longformer/BigBird | (O(N)) | Partial (global tokens) | Medium-High | 16K-64K+ | Long docs needing some global awareness |
| Streaming (Transformer-XL) | (O(L \cdot d))/chunk | Indirect (via state) | High | Theoretically unlimited | Continuous streams, chatbots, real-time processing |
| RoPE Scaling | Same as base | Same as base | Low (inference) | 2-8x original | Extending existing models easily |
| Hierarchical Approaches | Varies | Multi-level | High | 100K+ | Extremely long docs with natural hierarchical structure |
The optimal choice is deeply contextual, depending on the specific task, data characteristics, and available hardware.
9. Future Research Directions
The quest for longer context is far from over. Key frontiers include:
9.1 Ultra-Long Context (100K+ tokens)
Pushing into the hundreds of thousands or millions of tokens requires more radical approaches:
- Retrieval Augmentation: Letting attention focus locally but retrieving relevant snippets from a massive external context store.
- Explicit Neural Memory: Designing trainable memory modules separate from the main context window.
- Sublinear Attention: Algorithms aiming for (O(N \log N)) or even (O(N)) complexity, fundamentally breaking the quadratic barrier (though often with approximation trade-offs).
9.2 Hardware-Optimized Implementations
The interplay between algorithms and silicon is crucial:
- Tailored Kernels: Hand-optimized GPU code (like CUDA kernels) for specific sparse or efficient attention patterns.
- Distributed Attention: Splitting the attention computation cleverly across multiple GPUs or nodes.
- Precision Engineering: Using lower-precision arithmetic (like FP8) judiciously for attention calculations to save memory and speed up compute.
9.3 Training Dynamics for Extended Context
How models learn long context matters:
- Native Long-Context Training: Training models from scratch on very long sequences (computationally demanding but potentially more effective).
- Curriculum Learning: Starting training with short contexts and gradually increasing the length.
- Efficient Transfer: Developing better methods to adapt short-context models to long contexts without full retraining.
10. Practical Recommendations and Conclusion
10.1 Choosing the Right Approach
Navigating the options requires clear thinking:
- What does the task demand? Global synthesis or local pattern matching?
- What hardware can you throw at it? Memory is often the tightest constraint.
- How fast does it need to be? Real-time streaming vs. offline batch processing?
- How much engineering pain can you tolerate? Simple scaling vs. complex custom architectures?
10.2 Implementation Tips
- Iterate: Start with simpler methods (RoPE scaling, basic windowing) and benchmark before committing to complexity.
- Measure Carefully: The benefits of context extension can be task-specific; evaluate on relevant benchmarks.
- Combine Forces: Hybrid approaches often win (e.g., FlashAttention + Window Attention).
- Test Realistically: Performance on synthetic tasks might not translate perfectly to your specific data distribution.
10.3 Conclusion
Scaling context length is more than just a technical benchmark; it’s about fundamentally expanding the cognitive horizon of LLMs. The quadratic attention bottleneck remains a formidable challenge, but the ingenuity displayed in developing workarounds—from pragmatic local attention schemes and clever scaling tricks like RoPE, to hardware-aware optimizations like FlashAttention and fundamentally different paradigms like streaming—is impressive.
As these methods mature and new breakthroughs emerge, we’re steadily moving towards LLMs that can engage with information on the scale of human knowledge repositories – entire books, extensive codebases, lifelong conversations. This evolution promises richer understanding, more complex reasoning, and ultimately, more capable and useful AI. The struggle continues, but the trajectory is clear.
References
- Transformer-XL: Dai et al. (2019) – Segment-level recurrence for long-context language modeling.
- Longformer: Beltagy et al. (2020) – Combines local attention windows with global tokens.
- BigBird: Zaheer et al. (2020) – Sparse + global + random attention for linear scaling.
- FlashAttention: Dao et al. (2022) – IO-aware blockwise exact attention for memory efficiency.
- Rotary Embeddings: Su et al. (2021) – Original paper introducing RoPE.
- Memorizing Transformers: Wu et al. (2022) – Augmenting Transformers with a retrieval-based memory system.
- Attention Sinks: Xiao et al. (2023) – How position influences attention in very long context.