Key Takeaways
- QLoRA enables fine-tuning large models like Llama 3 8B on consumer GPUs by combining 4-bit quantization of base model weights with low-rank adapters (LoRA).
- Axolotl simplifies the QLoRA fine-tuning process, allowing you to manage the entire workflow through a single YAML configuration file.
- Careful configuration of parameters like sequence length, batch size, quantization settings, and LoRA specifics is crucial for successful training within typical memory constraints (e.g., 24GB VRAM).
- The fine-tuned adapter is significantly smaller than the full base model, making it portable, shareable, and efficient for deployment.
- Monitoring training logs for metrics like loss, gradient norm, and memory usage is essential for troubleshooting and ensuring a stable and effective fine-tuning run.
Prerequisites
Before we dive in, here’s the setup I used. You’ll need a similar environment to replicate the results.
| Component | Version I used | Notes |
|---|---|---|
| CUDA Toolkit | 12.2 | Any recent 12.x version should work. You can download it from the NVIDIA CUDA Toolkit website. |
| NVIDIA Driver | ≥ 535 | Required for FlashAttention 2. Check for the latest drivers on the NVIDIA Driver download page. |
| Python | 3.10 | Versions 3.9–3.11 are generally compatible. |
| GPU | RTX 4090 (24 GB) | A GPU with 16 GB of VRAM might work with a smaller batch size or sequence length. |
Tip: Verify that your GPU supports bfloat16. This format can halve the memory required for activations compared to FP32 and significantly accelerate matrix computations. Most modern NVIDIA GPUs (Ampere architecture and newer) support it. You can learn more about its benefits from resources like the BFloat16 Wikipedia article.
Why QLoRA?
The brute-force approach to fine‑tuning demands updating the entire parameter space of the base model:
where is the learning rate and
is the loss function. This is computationally punishing and requires VRAM far beyond the reach of most individual practitioners.
LoRA (Low-Rank Adaptation) executes a more elegant strategy. It freezes the vast expanse of the base model’s weights () and injects smaller, trainable rank decomposition matrices (
and
) into specific layers, typically the attention blocks. Only these new, lightweight matrices are updated during training, radically reducing the number of trainable parameters and the memory footprint.
QLoRA pushes this efficiency to its logical extreme. As detailed in the QLoRA paper by Dettmers et al., the methodology is a three-pronged attack on memory consumption:
- Quantization: The frozen, pre-trained model weights are quantized to a 4-bit representation (typically using a format like NF4 – NormalFloat4). This single step drastically shrinks the memory footprint of the base model.
- High-Precision Adapters: The LoRA adapter weights are maintained in a higher precision format, usually BFloat16 (
bf16), preserving the fidelity of the updates. - Double Quantization: An optional step that further reduces the memory overhead of the quantization constants themselves.
The result is a profound reduction in memory usage, making it feasible to fine-tune massive models (7B, 13B, and even larger) on a single, high-end consumer GPU. The Hugging Face PEFT library is the canonical resource for exploring these techniques further.
Installing Axolotl
Axolotl, a project from the OpenAccess AI Collective, streamlines this entire orchestration. Its source code is available on GitHub. Installation is clean.
git clone https://github.com/OpenAccess-AI-Collective/axolotl
cd axolotl
# It's good practice to create a virtual environment first
# python -m venv axolotl-env
# source axolotl-env/bin/activate
# Install with optional dependencies like FlashAttention-2 and DeepSpeed
# These are highly recommended for performance and efficiency
pip install packaging ninja
pip install -e '.[flash-attn,deepspeed]'
# If you're using a gated model from Hugging Face (like Llama 3),
# you'll need to authenticate.
huggingface-cli loginAnd that’s it. No labyrinthine setup process. Just a potent CLI tool driven by a single point of truth: the configuration file.
The Configuration File Explained
The heart of Axolotl is its YAML configuration. What follows is the entire llama3_wizardlm.yaml I used, with a breakdown of the strategic choices.
# --- Base Model Configuration --------------------------------------------
base_model: meta-llama/Meta-Llama-3-8B # Hugging Face model ID or local path
model_type: LlamaForCausalLM
tokenizer_type: Llama3TokenizerFast # Specify tokenizer for Llama 3
load_in_4bit: true # Enable 4-bit quantization for the base model
bnb_4bit_quant_type: nf4 # Use NormalFloat4 for quantization
bnb_4bit_compute_dtype: bfloat16 # Data type for computations (matrix multiplications)
bnb_4bit_use_double_quant: true # Use double quantization for better precision
bnb_config_kwargs:
llm_int8_has_fp16_weight: false # Not relevant for 4-bit, but good practice
# --- Dataset Configuration -----------------------------------------------
datasets:
- path: WizardLM/WizardLM_evol_instruct_70k # Path to the dataset on Hugging Face Hub
split: train # Which split of the dataset to use
type: sharegpt # Dataset format (Axolotl supports various types)
conversation: chatml # Conversation template (Llama 3 uses a specific one)
sequence_len: 512 # Maximum sequence length for input samples
pad_to_sequence_len: true # Pad shorter sequences to sequence_len
sample_packing: false # Set to true for effiency, false for clarity here
# Sample packing combines multiple short examples
# --- Adapter (LoRA/QLoRA) Configuration ----------------------------------
adapter: qlora # Specify QLoRA adapter
lora_r: 16 # Rank of the LoRA matrices (higher r = more params)
lora_alpha: 16 # Scaling factor for LoRA (often same as r)
lora_dropout: 0.05 # Dropout probability for LoRA layers
lora_target_modules: # Modules to apply LoRA to
- q_proj
- k_proj
- v_proj
- o_proj
- gate_proj
- up_proj
- down_proj
# --- Training Configuration ----------------------------------------------
micro_batch_size: 6 # Batch size per GPU
gradient_accumulation_steps: 4 # Accumulate gradients over 4 steps (effective batch size = 6*4 = 24)
num_epochs: 4 # Number of training epochs
learning_rate: 1.0e-4 # Initial learning rate
lr_scheduler: linear # Learning rate scheduler type (linear decay)
warmup_ratio: 0.1 # Percentage of training steps for warmup
optimizer: paged_adamw_8bit # Use paged AdamW optimizer (8-bit) for memory efficiency
bf16: auto # Use bfloat16 if available, otherwise fp16
fp16: false # Explicitly false if bf16 is preferred/auto
gradient_checkpointing: true # Enable gradient checkpointing to save memory
flash_attention: true # Use FlashAttention-2 for speed and memory savings
# --- Evaluation & Logging ------------------------------------------------
val_set_size: 0.05 # Use 5% of train data for validation if no dedicated test_dataset
logging_steps: 10 # Log metrics every 10 steps
eval_steps: 100 # Evaluate on the validation set every 100 steps
save_steps: 100 # Save checkpoint every 100 steps (can also use saves_per_epoch)
# saves_per_epoch: 1 # Alternative to save_steps
# --- Special Tokens & Output ---------------------------------------------
special_tokens:
pad_token: <|eot_id|> # Llama 3 needs explicit pad token; <|eot_id|> is often used
output_dir: ./outputs/wizardlm-llama3-8b-qlora # Directory to save model checkpoints and logs
strict: false # Less strict about config validation (use with caution)Why these choices?
load_in_4bit: true&bnb_...settings: This block is the core of QLoRA, instructing Axolotl to load the base model in 4-bit precision via thebitsandbyteslibrary.nf4(NormalFloat4) is the empirically superior quantization format, andbfloat16provides a good balance of speed and precision for the compute data type during matrix multiplications.datasets: We’re using theWizardLM_evol_instruct_70kdataset, a well-regarded set of instruction-following examples. Thesharegpttype andchatmlconversation template ensure the data is formatted correctly for Llama 3 Instruct models.sequence_len: 512: A pragmatic trade-off. Longer sequences capture more context but consume more VRAM. Crucially, Axolotl’s default behavior is to drop examples longer thansequence_len, so this value must be chosen with awareness of your dataset’s characteristics.lora_r: 16,lora_alpha: 16: These are common, effective starting points for QLoRA.rsets the rank (and thus, capacity) of the adapter, whilealphaacts as a scaling factor. The heuristic ofalpha = ris a solid baseline. A higherrincreases trainable parameters and potential model fidelity at the cost of VRAM.lora_target_modules: This is where we specify the surgical incisions. We aren’t performing open-heart surgery on the entire model; we are injecting our LoRA adapters precisely into the attention projections (q_proj,k_proj,v_proj,o_proj) and MLP feedforward layers (gate_proj,up_proj,down_proj)-the cognitive machinery of the transformer.micro_batch_size: 6,gradient_accumulation_steps: 4: This yields an effective batch size of 24.micro_batch_sizeis the knob to turn first when hitting VRAM limits.optimizer: paged_adamw_8bit: A memory-efficient optimizer frombitsandbytesthat pages optimizer states between GPU and CPU RAM, another critical memory-saving technique.flash_attention: true: When available, FlashAttention-2 provides a highly optimized, memory-efficient implementation of the attention mechanism, a key bottleneck.special_tokens: pad_token: <|eot_id|>: Llama 3’s tokenizer lacks a defaultpad_token. Failure to define one will break training. Using an existing special token like<|eot_id|>(end of turn) is a standard workaround.
Here is a conceptual overview of this configuration in action:
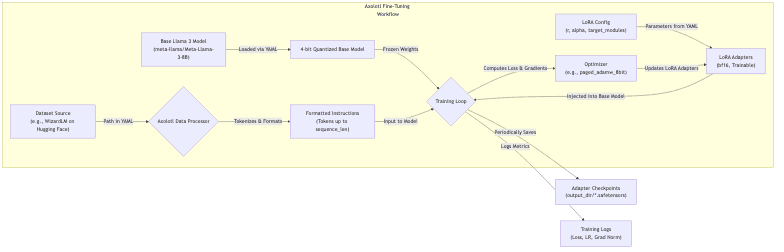
Launching Training
With the llama3_wizardlm.yaml configuration file in place, initiating the training run is a single command:
accelerate launch -m axolotl.cli.train llama3_wizardlm.yamlHugging Face’s accelerate library handles the underlying orchestration, even on a single GPU. Axolotl uses it to manage the process seamlessly, from parsing the YAML to downloading assets and executing the training loop.
Reading the Logs
Logs aren’t just machine-generated noise; they are the vital signs of your training run. Learning to read them is the difference between informed intervention and flying blind.
[2024-07-22 13:11:21,111] [INFO] [axolotl.load_model:734] [PID:6971] [RANK:0] GPU memory usage after model load: 5.311GB (+0.087GB cache, +0.542GB misc)
[2024-07-22 13:11:21,129] [INFO] [axolotl.load_model:785] [PID:6971] [RANK:0] converting PEFT model w/ prepare_model_for_kbit_training
[2024-07-22 13:11:21,133] [INFO] [axolotl.load_model:794] [PID:6971] [RANK:0] converting modules to torch.bfloat16 for flash attention
trainable params: 41,943,040 || all params: 8,072,204,288 || trainable%: 0.5196
...
{'loss': 1.1143, 'grad_norm': 0.4541325, 'learning_rate': 6.134969325153374e-06, 'epoch': 0.02}
{'loss': 1.1003, 'grad_norm': 0.538657, 'learning_rate': 1.2269938650306748e-05, 'epoch': 0.05}Key signals to monitor:
| Log Entry/Metric | Interpretation | Healthy Sign/Range |
|---|---|---|
| GPU memory after model load | VRAM consumed by the 4-bit quantized base model. For Llama 3 8B, this is around 5-6 GB. | Consistent with model size and quantization. |
| GPU memory before training | Total VRAM after all components are loaded. The delta from the post-load state shows the overhead of activations, etc. | Should be comfortably within your GPU’s VRAM limit. |
| Trainable % | The ratio of trainable LoRA adapter parameters to total model parameters. This confirms QLoRA is active. | Typically 0.1% to 1% for QLoRA. 0.52% here is good. |
loss (training) |
The primary metric being minimized. Should trend downwards over time, though fluctuations are normal. | A clear downward trajectory. |
eval_loss |
Loss on the validation set. This is your guard against overfitting. If train_loss falls while eval_loss rises, you’re overfitting. |
Ideally also trends downwards or stabilizes. |
grad_norm |
The norm of the gradients. A persistently high or exploding grad_norm (> 5-10) signals training instability. |
Stays within a reasonable range (e.g., 0.1-2.0). |
learning_rate |
Confirms your lr_scheduler is working as intended (e.g., warmup followed by linear decay). |
Follows the defined schedule. |
Pro‑tip: If you encounter sudden spikes in
lossorgrad_norm, investigate the data being processed at that step. Malformed or unusually long sequences in a batch can often be the culprit.
Inference with the Adapter
Upon completion, Axolotl saves the LoRA adapter weights (e.g., adapter_model.safetensors) to your output_dir. This lightweight adapter can then be loaded on top of the original base model for inference.
Option 1 – Axolotl’s Built-in Inference Server
Axolotl provides a simple Gradio-based chat interface for quick testing:
accelerate launch -m axolotl.cli.inference \
llama3_wizardlm.yaml \
--lora_model_dir="./outputs/wizardlm-llama3-8b-qlora/" \
--gradioThis command loads the base model, applies your trained adapter, and spins up a web UI at localhost:7860 for immediate interaction.
Option 2 – Programmatic Control with Hugging Face Transformers
For integration into applications, the transformers and peft libraries provide full control.
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import PeftModel
import torch
base_model_id = "meta-llama/Meta-Llama-3-8B"
adapter_path = "./outputs/wizardlm-llama3-8b-qlora/" # Path to your trained adapter
# Load the Llama 3 tokenizer
tokenizer = AutoTokenizer.from_pretrained(base_model_id, trust_remote_code=True)
# Ensure pad token is set, consistent with training
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token # Or <|eot_id|>
# Load the base model in 4-bit
model = AutoModelForCausalLM.from_pretrained(
base_model_id,
load_in_4bit=True,
torch_dtype=torch.bfloat16, # Or torch.float16
device_map="auto", # Automatically map model layers to available devices
trust_remote_code=True
)
# Load the LoRA adapter
model = PeftModel.from_pretrained(model, adapter_path)
# Optional: merge weights for a standalone model (requires more memory)
# model = model.merge_and_unload()
model.eval() # Set to evaluation mode
# Use the Llama 3 chat template for correct prompt formatting
messages = [
{"role": "user", "content": "Explain QLoRA in two sentences."},
]
prompt_input_ids = tokenizer.apply_chat_template(
messages,
return_tensors="pt"
).to(model.device)
print("Generating response...")
with torch.no_grad():
outputs = model.generate(
input_ids=prompt_input_ids,
max_new_tokens=128,
eos_token_id=tokenizer.eos_token_id,
do_sample=True,
temperature=0.7,
top_p=0.9
)
response_ids = outputs[0][prompt_input_ids.shape[-1]:] # Extract only the new tokens
response_text = tokenizer.decode(response_ids, skip_special_tokens=True)
print(f"User: Explain QLoRA in two sentences.")
print(f"Assistant: {response_text}")Crucially, you must use the same chat_template or prompt format that the model was fine-tuned on. Deviating from this will yield suboptimal, often nonsensical, results.
Common Pitfalls
Fine-tuning is a minefield of subtle configuration errors. Here are failure modes I’ve encountered or seen plague others:
- The Silent Data Killer: If
pad_to_sequence_len: falseandsample_packing: false, Axolotl doesn’t truncate oversized examples; it discards them entirely. This can lead to the silent, catastrophic loss of a significant chunk of your dataset.- Fix: Either increase
sequence_len(if VRAM permits), pre-process your dataset, or meticulously check Axolotl’s data processing logs to confirm the number of examples being used.
- Fix: Either increase
- Prompt Format Mismatch: Using a different chat template at inference time from the one used during training is a common and fatal error. Generation will be poor.
- Fix: Be disciplined. Ensure your
conversationformat in the YAML is strictly mirrored in your inference code.
- Fix: Be disciplined. Ensure your
- The Missing
pad_token: Llama 3’s tokenizer, like Llama 2’s, has no defaultpad_token. Without defining one inspecial_tokens, training will break with anindex out of rangeerror.- Fix: Always explicitly define a
pad_tokenin your Axolotl config for Llama 3.
- Fix: Always explicitly define a
- Gradient Explosion: A sign of instability, diagnosed by a
grad_normthat skyrockets and alossthat becomesNaN.- Fix: The first lever to pull is
learning_rate. Lower it. Consider a gentlerlr_scheduleror a longerwarmup_ratio. As a final backstop, enable gradient clipping by settingmax_grad_norm: 1.0in the YAML.
- Fix: The first lever to pull is
- Out Of Memory (OOM) Errors:
- Mid-training: The culprits are almost always
micro_batch_size,sequence_len, orlora_r. Reduce them, in that order. Ensuregradient_checkpointing: trueandflash_attention: trueare active. - During Model Load: This is rare for an 8B model on a 24GB GPU with 4-bit loading. If it happens, double-check your
bnb_config_kwargsand ensure no other processes are consuming VRAM.
- Mid-training: The culprits are almost always
- FlashAttention Drama: FlashAttention is notoriously sensitive to CUDA, PyTorch, and NVIDIA driver versions.
- Fix: Verify your environment meets the library’s requirements. If intractable issues persist, you can fall back by setting
flash_attention: false. Performance will degrade, but it’s a valid diagnostic step.
- Fix: Verify your environment meets the library’s requirements. If intractable issues persist, you can fall back by setting
Wrap‑up
Taming an 8-billion-parameter model like Llama 3 was, until recently, a game reserved for those with access to enterprise-scale cloud clusters. The potent combination of QLoRA’s memory alchemy and Axolotl’s declarative elegance hasn’t just lowered the barrier to entry; it’s effectively democratized a critical capability.
The result of this process, for my configuration, is a LoRA adapter with ~41.9 million parameters, weighing in at a mere 84 MB (41.9M params × 2 bytes/param for bf16). This compact artifact is trivial to share, version, and deploy, making personalized LLMs more tractable and accessible than ever before.
Take this configuration as a starting point. Adapt it. Experiment. The landscape of open-source AI is evolving at a ferocious pace, and tools like Axolotl are what empower us to be participants, not just spectators.
Happy fine‑tuning! 🚀
Further Reading
- QLoRA Paper: Dettmers, Tim, et al. “QLoRA: Efficient Finetuning of Quantized LLMs.” (arXiv:2305.14314)
- Axolotl Documentation: The official guide for Axolotl. (https://openaccess-ai-collective.github.io/axolotl/)
- Hugging Face PEFT Library: For more on Parameter-Efficient Fine-Tuning techniques. (https://huggingface.co/docs/peft/index)
- Hugging Face Transformers: The core library for working with transformer models. (https://huggingface.co/docs/transformers/index)
- Llama 3 Model Card: Essential reading for prompt formats and other details. (https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct)
I have updated this article a couple of times so the config should work fine. But if something doesn’t work, please let me know on LinkedIn or X.