Key Takeaways
- A yardstick grounded in economic reality. METR introduces the 50% task-completion time-horizon-the duration of a human task an AI agent can now reliably finish half the time. It cuts through the benchmark noise.
- The curve is exponential and steep. Horizon length has doubled roughly every 7 months, a pace that makes Moore’s Law look sluggish.
- The one-hour mark is about to fall. Frontier models like Claude 3.7 Sonnet and OpenAI’s o1 now chew through tasks that would occupy a skilled human for 40–60 minutes.
- It’s about architecture, not just scale. The gains come from superior agency-reliability, self-correction, and tool-use scaffolds-not merely throwing more parameters at the problem.
- The trajectory points to month-long autonomy. A straight-line extrapolation on this semilog plot puts ‘one-month agents’ on the board somewhere between 2028 and 2031.
Why This Paper Matters
For years, we’ve measured AI capability with proxies like MMLU or HumanEval-useful, but sterile. They capture atomic skills in a vacuum, collapsing the moment they meet the messy, multi-hour grunge work that defines actual engineering.
METR-staffed with alumni from the likes of Anthropic and Ohm Chip-attacks this gap head-on. By baselining human experts against a suite of real-world tasks, they translate model ability into the only currency that truly matters in the boardroom: man-hours.
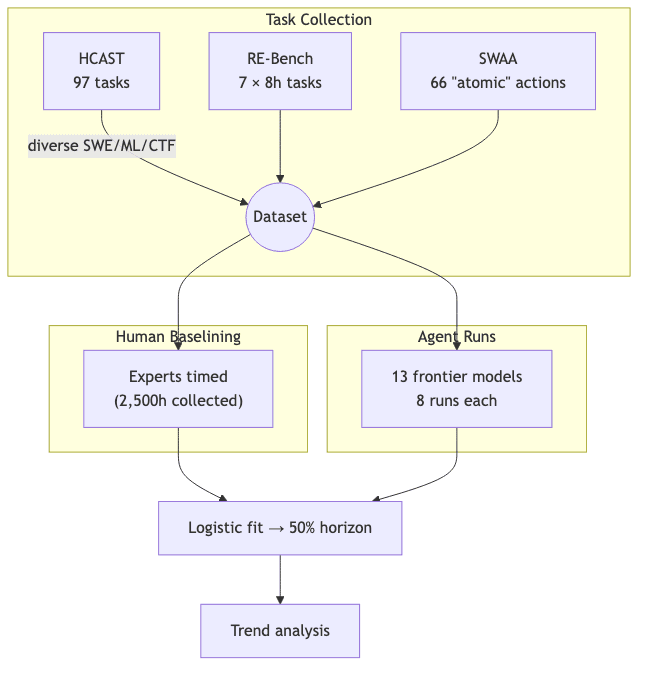
Diving Deeper
1 The Metric
Let be the geometric mean time a skilled human spends on task
. The probability that an agent with a given time-horizon
succeeds is fitted to a simple one-parameter logistic curve:
Solving for yields the horizon directly in minutes. No abstract scores, no fuzzy composites.
2 Data Highlights
| Model (release) | 50 % Horizon | Δ vs GPT‑4‑0314 |
|---|---|---|
| o1 (May 2025) | 39 min | ×6 |
| Claude 3.7 Sonnet (May 2025) | 59 min | ×9 |
| GPT‑3.5 (2023) | 0.6 min | baseline |
The regression line on a semilog plot boasts an
. A fit this clean on capability data is either a reporting error or something resembling a physical law.
3 Qualitative Leaps
- Error recovery: Modern agents don’t just fail; they learn from failure. They seldom get stuck in the same trivial
pip installloop. They re-plan. - Tool chains: Wrappers like Modular‑Public aren’t just tools; they’re the exoskeletons that give LLMs leverage. Horizon gains track the maturity of this scaffolding.
- Reasoned refusal: Older models would brute-force their way into dead ends. Newer agents exhibit a form of reasoned refusal on tasks with hidden pitfalls, a crucial sign of maturity.
4 External Validity & Messiness
The real world is messy. METR cross-validates against SWE‑bench Verified and a handful of in-house pull requests. The trend holds, though the variance increases with what they aptly call messiness factors-the friction of resource limits, dynamic environments, and ambiguous specs. Crucially, while both humans and AIs slow down in the mess, the slope of progress remains constant.
What Others Are Saying
- The EA Forum commends the metric for “bridging academic benchmarks and board‑room timelines,” sparking a familiar debate on whether the exponential curve can survive the end of pure compute scaling.
- Inevitably, LiveScience distilled this into a pop-science narrative: “AI’s attention span is doubling every few months,” a framing designed to maximize both public awe and corporate FOMO.
- Meanwhile, LinkedIn chatter has seized on the seven‑month doubling time as the perfect soundbite for executive decks.
For those who prefer verification over trust, the authors open-sourced the entire analysis pipeline at https://github.com/METR/eval-analysis-public. A refreshing nod to reproducibility.
My Take
The time‑horizon lens is refreshingly concrete, a welcome antidote to the usual firehose of abstract benchmark scores. It echoes theoretical concepts like Richard Ngo’s “effective step size” but grounds them in the brutal reality of billable hours. Two reflections:
- Capability ≠ Reliability. The paper’s honesty about tail performance is critical. The 80% completion horizon lags the 50% median by nearly an order of magnitude. This is the difference between a useful co-pilot and a tool you can trust to run overnight. Any product manager planning for full automation needs to internalize this gap and build robust human-in-the-loop workflows.
- Forecast uncertainty hides in trend shifts, not noise. The real uncertainty isn’t in the noise around the regression line; it’s in the longevity of the trend itself. The curve bends when a paradigm hits its limits. If breakthroughs in agentic architecture stall, this exponential ride flattens into an S-curve. Conversely, if agents begin designing their own reinforcement learning curricula, expect the curve to get even steeper.
Either way, METR has given us a dashboard to watch the bend unfold in real-time.
A Minimal Re‑Implementation
For the technically inclined, reproducing the core finding is straightforward. The following sketch shows how to derive the 50% horizon from their public data:
import pandas as pd, numpy as np
from scipy.optimize import curve_fit
def logistic(t, H, beta):
return 1 / (1 + np.exp(beta * (np.log(t) - np.log(H))))
df = pd.read_csv("agent_task_results.csv")
# df columns: model, human_time_s, success (0/1)
for model in df.model.unique():
subset = df[df.model == model]
popt, _ = curve_fit(logistic, subset.human_time_s, subset.success,
p0=[60, 6]) # initial guess: 1 min horizon
print(model, f"≈ {popt[0]/60:.1f} min")(check repo for full code)
Closing Thoughts
The journey from GPT‑2’s toddler-like focus in 2019 to o1 devouring 40-minute engineering tasks in 2025 is a staggering arc. The trajectory feels eerily reminiscent of the semiconductor industry’s golden age, but this time the y-axis isn’t transistor density; it’s knowledge‑worker hours being subsumed into the machine.
The actionable takeaway is stark. If you lead an engineering organization, start planning for agents that can autonomously handle day-long tickets within the next 18 months. The window to design the systems, guardrails, and human oversight for this new reality is closing, and fast.