The Key Insights
- A Third Axis of Scaling. We’ve been scaling models by adding parameters (going wider) or tokens (going longer). This work unveils a third dimension: thinking deeper. A small, recurrent core can iterate in latent space, achieving greater reasoning power without architectural bloat.
- A 3.5B Model That Hunts Bigger Prey. Huginn-0125, trained on a mere 800 billion tokens, consistently matches or beats 7B–12B parameter models on the hard stuff-math, code, abstract reasoning. It proves that raw size isn’t everything.
- Elegant Capabilities, No Extra Charge. Adaptive compute, KV-cache compression, continuous Chain-of-Thought, and self-speculative decoding emerge naturally from the architecture. These aren’t bolted-on features; they are inherent properties requiring zero additional fine-tuning.
- The Brutal Physics of Exascale Training. The paper candidly documents two failed training runs on the Frontier supercomputer, underscoring the fragility of depth-recurrence at scale. The stability they finally achieved was hard-won, a testament to the real engineering required.
- Glimpses of an Internal World. The latent state isn’t a black box. Its trajectories-orbiting, sliding, converging-hint at emergent, interpretable algorithms forming within the model’s “mind.”
Why a Third Axis of Scaling?
The dominant LLM narrative has been one of brute force. Progress has been measured by two primary levers: throwing more parameters at the problem or feeding the model longer chains of text. Both strategies are running into hard physical and economic walls-GPU memory limits, finite context windows, and the punishing cost of ingesting trillions of tokens. The industry is predictably hunting for alternatives, with test-time compute becoming the new frontier.
The Maryland–Livermore team posits a simple yet profound idea: what if reasoning doesn’t have to be verbal? What if a model could conduct its “thought process” internally, iterating silently on its own vector representations, exploring a combinatorial space far richer than a linear sequence of tokens could ever capture?
Anatomy of the Latent Recurrent-Depth Transformer
At its core, the model is an elegant modification of the standard decoder-only transformer, partitioned into three functional blocks. It’s less a radical reinvention and more a clever repackaging.
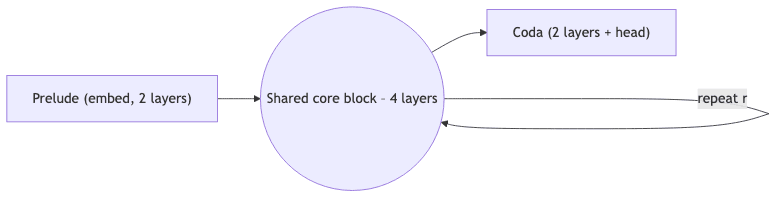
The magic lies in that central loop. The same 4-layer core is reused r times, creating a cognitive feedback loop. At inference, r becomes a direct knob for controlling how much compute-how much “thought”-is applied.
Mathematically, the flow is straightforward:
During training, r is sampled from a distribution, and back-propagation is truncated to the last 8 steps to keep the process computationally tractable. It’s a pragmatic nod to the realities of training such a deep, unrolled graph.
The Training Journey
This wasn’t a simple training run; it was an expedition.
- Hardware: 4096 AMD MI250X GPUs on ORNL’s Frontier, pushing up to 1.2 million tokens/second (an effective ~260 PFLOP/s).
- Software: The team had to hand-roll their own distributed routine to sidestep RCCL hangs and wrangle FlashAttention-2 via ROCm. This is the unglamorous, essential work of progress at the edge.
- Stability: This is where the real war stories lie. Two early training runs collapsed, with all tokens converging to an identical, useless state. Stability was only achieved after implementing a sandwich RMSNorm and a specific Takase initialization-a crucial, hard-won piece of engineering lore.
How Does Huginn Perform?
The results speak for themselves. Huginn consistently punches above its weight class, especially on tasks that demand reasoning over rote memorization.
| Benchmark | 7 B OLMo-0724 | Huginn-0125 (r = 32) |
|---|---|---|
| ARC-Challenge | 43.4% | 38.2% |
| GSM8K (flex) | 28.7% | 34.8% |
| HumanEval | 20.1% | 23.2% |
| MBPP | 25.6% | 24.8% |
Scores from lm-eval / BigCodeBench with zero-shot settings.
Huginn overtakes models with 2-3x its parameter count on reasoning benchmarks. The trade-off is clear: it lags on pure fact-recall tasks like OpenBookQA. Its memory capacity is modest, but its ability to think is demonstrably greater. This is a feature, not a bug.
Beyond Benchmarks: Zero-Shot Perks
The architecture yields several powerful capabilities that require no extra training-they are simply consequences of the design.
Adaptive Compute
By setting a simple KL-divergence threshold, the model learns to decide for itself how long to “think.” Simple questions exit the recurrent loop after ~5 steps; complex math problems might use 30 or more. It allocates compute intelligently, on demand.
KV-Cache Compression
Because the same core weights are used in every step, the key/value pairs from earlier steps remain compatible. This allows the model to cache only the last k steps, dramatically reducing the memory footprint of the KV-cache without any fine-tuning.
Continuous CoT & Self-Speculation
The final latent state from the previous token can be used to seed the initial state of the next token. This creates a silent, continuous “chain of thought” in latent space, which not only accelerates generation but also provides a perfect draft for speculative decoding.
What Emerges in Latent Space?
By projecting the latent trajectories into 2D, the authors reveal a fascinating inner world with distinct patterns of thought:
- Convergence: Common, unambiguous tokens settle into their final state almost immediately.
- Orbits: Numerals like 3 trace stable circles as the model appears to be “spinning up” an internal arithmetic module.
- Sliders: Certain tokens, particularly those related to moderation or safety, drift linearly, almost as if they are counting the recurrence steps.
Crucially, multiple random initializations converge to the same final state, satisfying the principle of path independence. The model finds the answer, regardless of where it starts its thought process.
Strengths & Limitations
| 👍 | ⚠️ |
|---|---|
| An elegant knob to trade wall-clock time for better reasoning. | Latent steps are not free; you still pay in FLOPs and latency. |
| Works with standard training data-no need for elaborate CoT exemplars. | A fragile beast to tame; requires careful initialization and normalization. |
| Lean and memory-friendly (3.5 B parameters). | Trades encyclopedic recall for reasoning; weaker on trivia vs larger models. |
| Emergent zero-shot features reduce engineering overhead. | The tooling (Flash-attn on ROCm, truncated-BPTT) is not yet mainstream. |
Quick Start
from transformers import AutoTokenizer, AutoModelForCausalLM
model_id = "tomg-group-umd/huginn-0125"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto", torch_dtype="auto")
question = "Summarise the Euclidean algorithm and prove its termination."
inputs = tokenizer(question, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=128, recurrent_steps=32)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))The custom inference script exposes --r to set recurrence globally, and patches for frameworks like vLLM are emerging.
Future Directions
The paper maps out a clear and compelling trajectory:
- Fusing Sparsity with Depth: Combine latent recurrence with a Mixture-of-Experts architecture. This could provide a path to scaling both compute and memory efficiency.
- Training the Thought Process: Apply Reinforcement Learning from Human Feedback (RLHF) directly to the latent trajectories, not just the final text output. Reward efficient and effective “thought,” not just the right answer.
- Architectural Transplant: Drop Huginn’s recurrent core into a larger, knowledge-rich base model like Llama. This could graft advanced reasoning capabilities onto a foundation of broad world knowledge.
Final Thoughts
Depth recurrence feels like the natural counterpart to the token-by-token recurrence we’ve been using all along. One turns the page; the other stops to think. Scaling up Test-Time Compute with Latent Reasoning offers convincing proof that thinking in vectors can close a significant reasoning gap without the bloat of ever-wider models.
I’m genuinely enthusiastic. This feels like a move away from brute-force scale and towards architectural elegance. But for latent reasoning to go mainstream, the community will need to rally: tooling must mature, evaluation norms must be established, and the hard-won lessons from training these fragile beasts must be shared.