Introduction
The world of artificial intelligence, obsessed as it is with rapid mutation, is undergoing a profound shift in its very foundations. For what feels like an eon in tech time, Nvidia’s CUDA ecosystem wasn’t just a platform; it was the platform. A necessary, powerful, yet undeniably restrictive bedrock upon which the modern AI edifice was built. We’ve been living in Nvidia’s world. But the ground is shifting. The arrival of PyTorch 2.0, OpenAI’s Triton, and a wave of open compiler technologies signals more than just technical progress; it’s the sound of walls cracking. We’re witnessing the potential end of an era defined by hardware lock-in, moving towards a future where AI development might actually become more accessible, more flexible—perhaps even more rational.
This isn’t merely about better compilers or faster code. It’s a fundamental realignment, a philosophical tilt towards openness in a field that grew up tethered to specific silicon. Let’s dissect this evolution, tracing how the AI software stack is being re-architected and what this implies for anyone trying to build the future.
The Historical Landscape: TensorFlow vs. PyTorch
The Rise and Fall of Framework Dominance
It wasn’t long ago that Google’s TensorFlow looked like the inevitable victor. It had the early start, the corporate muscle, the tight coupling with its custom Tensor Processing Units (TPUs). It seemed destined to dominate. Yet, observe the landscape now. The research community, the very engine of AI’s progress, staged a quiet, collective migration to PyTorch. It’s more than a minor preference shift; it was one of the most decisive framework upheavals in recent memory.
Why PyTorch Won the Hearts of Researchers
Why the exodus? It wasn’t market whimsy. PyTorch addressed fundamental frictions TensorFlow initially ignored:
- Intuitive “Eager Mode” Execution: TensorFlow’s original sin was its define-then-run graph model. Great for static production graphs, perhaps, but antithetical to the messy, iterative, print-statement-debugging reality of research. PyTorch executed immediately. You typed code, it ran. Simple. Profound.
- Pythonic Design Philosophy: PyTorch didn’t just tolerate Python; it embraced its dynamism. It felt less like wrestling a foreign paradigm and more like extending a familiar language. Code flowed more naturally for minds steeped in Python.
- Research-First Mentality: TensorFlow was seemingly built with Google-scale production in mind. PyTorch felt built for the grad student, the experimenter, the person trying to make something new work now.
- Community Momentum: Critical papers started dropping in PyTorch. Codebases were shared. The network effect kicked in, pulling the center of gravity away from TensorFlow. Research breeds research, and the lingua franca shifted.
By 2020, the narrative had flipped. Today, virtually every headline-grabbing generative AI breakthrough, from diffusion models painting surreal landscapes to the GPT lineage redefining language, stands on PyTorch’s shoulders. It became the default dialect for AI innovation.
The Compilation Revolution: PyTorch 2.0
PyTorch’s triumph came with a built-in tension. The very dynamism and Python integration that fueled its rise became performance bottlenecks at scale. Running pure Python, eagerly executing operations one by one, leaves mountains of optimization potential on the table. PyTorch 2.0, landing in 2023, represents the framework grappling with its own success – attempting to bridge the chasm between research flexibility and production efficiency.
TorchDynamo: Bridging Dynamic Code and Static Optimization
TorchDynamo is the clever, slightly audacious core of PyTorch 2.0. It’s a system designed to have its cake and eat it too. It watches your Python code run, grabs chunks of it just-in-time, and translates them into a static computational graph (the FX Graph) amenable to optimization. Its genius lies in its pragmatism:
- It intercepts Python bytecode on the fly.
- It navigates Python’s messy realities – control flow, complex data structures – without choking.
- It understands calls to external libraries.
- Crucially, when it encounters something truly inscrutable, it gives up gracefully, falling back to the familiar eager execution. No wholesale rewrite required.
This mechanism offers the illusion of seamlessness: develop with the immediacy of eager mode, deploy with the speed of compiled graphs.
PrimTorch: Simplifying the Operator Landscape
Supporting diverse hardware backends was becoming an operational nightmare for PyTorch. Its operator library had bloated to over 2,000 distinct operations. Every new chip, every aspiring accelerator vendor, faced the Herculean task of implementing this sprawling API. PrimTorch is the answer – an act of aggressive simplification:
- It distills the essential computational atoms from the 2,000+ operators down to roughly 250 “primitive” operations.
- Higher-level, complex operators are redefined as compositions of these primitives.
- This creates a vastly smaller, more manageable surface area for hardware vendors to target.
Suddenly, supporting PyTorch isn’t an insurmountable moat. This simplification is a direct assault on the de facto hardware monopoly enjoyed by those who could afford the massive engineering effort to support the full, complex PyTorch API.
TorchInductor: The Universal Compiler
TorchInductor is the final piece, taking the optimized FX graph (now expressed in PrimTorch primitives) and translating it into high-performance code for the target hardware. It’s not just a simple code generator; it incorporates sophisticated techniques:
- Intelligent memory planning to minimize costly data movement.
- Kernel fusion, merging multiple small operations into larger, more efficient ones.
- Pluggable interfaces to hardware-specific compilers.
- Critically, native support for multiple backend technologies, including OpenAI’s Triton.
The PyTorch 2.0 Compilation Pipeline: How It All Fits Together
This entire compilation dance happens largely behind the scenes, orchestrated by torch.compile():
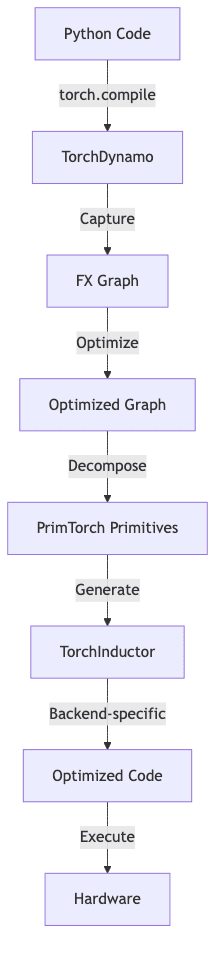
- Python Execution: Your standard PyTorch code executes.
- Graph Capture:
torch.compile()triggers TorchDynamo to intercept bytecode and build an FX graph. - Graph Optimization: Standard compiler optimizations are applied to the graph.
- Primitive Decomposition: Operators are broken down into their PrimTorch constituents.
- Hardware-Specific Compilation: TorchInductor generates code, potentially calling out to Triton for GPU kernels.
- Execution: The optimized code runs, ideally much faster.
TorchDynamo’s Graph Capture Process

The goal is laudable: maintain the cherished PyTorch developer experience while unlocking performance previously reserved for static graph frameworks.
OpenAI Triton: Democratizing GPU Programming
While PyTorch 2.0 reworks the framework level, OpenAI’s Triton targets the notoriously difficult layer below: actually programming the GPU silicon. For years, wringing maximum performance out of Nvidia GPUs meant mastering CUDA. This created a high priesthood of specialized programmers, a significant barrier to entry for optimizing novel algorithms or porting to new hardware.
Beyond CUDA: A New Programming Model
Triton offers a different philosophy, a higher level of abstraction over the raw hardware:
- Abstraction, Not Obscurity: It hides the painful low-level details – thread synchronization, shared memory management – without completely obscuring the underlying hardware parallelism.
- Automatic Memory Handling: The compiler takes responsibility for complex memory tiling and data placement, tasks requiring painstaking manual effort in CUDA.
- Expression-Oriented: It encourages thinking in terms of parallel operations on data blocks (tiles), closer to mathematical expressions than to low-level thread management.
Achieving Performance Without the Pain
The remarkable thing about Triton is that it achieves performance competitive with hand-tuned CUDA, without demanding the same level of specialized expertise:
- Triton-generated kernels for fundamental operations like matrix multiplication often hit 80-95% of the throughput of expert-crafted CUDA code.
- Algorithms requiring hundreds of lines of dense CUDA can often be expressed in a few dozen lines of Triton, improving readability and maintainability dramatically.
Flash Attention: A Triton Success Story
Flash Attention is the poster child for Triton’s impact. This algorithm revolutionized transformer training and inference by optimizing the notoriously memory-hungry attention mechanism. The core calculation is:
where ,
, and
are query, key, and value matrices, and
is the key dimension. Standard attention requires materializing the massive
attention matrix (where
is sequence length), leading to (O(N^2)) memory complexity. Flash Attention avoids this by computing attention block-by-block (tiling):

This reduces memory reads/writes significantly, cutting memory complexity to (O(N)). While the original Flash Attention was a complex CUDA implementation, the Triton version demonstrated:
- Drastically reduced code complexity.
- Improved readability and maintainability.
- Performance nearly identical to the CUDA original.
- Greater ease of modification, fueling further research into attention variants.
Triton made Flash Attention possible and (more importantly) accessible, accelerating progress across the entire field of large language models.
Performance Comparison: Traditional vs. Optimized Implementations
| Metric | CUDA Implementation | Triton Implementation |
|---|---|---|
| Lines of Code | ~500 (Illustrative) | ~100 (Illustrative) |
| Memory Complexity | (O(N^2)) | (O(N)) |
| Peak Memory Usage | Full attention matrix | Block-wise computation |
| Maintainability | Low (Requires CUDA Expert) | High (More Pythonic) |
| Hardware Portability | Tied to Nvidia/CUDA | Potentially broader support |
A Practical Example: PyTorch 2.0 and Triton in Action
Consider how these pieces fit together in a typical workflow:
import torch
import torch.nn as nn
# Define a simple neural network module.
class OptimizedNet(nn.Module):
def __init__(self):
super().__init__()
self.fc = nn.Linear(512, 512)
self.act = nn.ReLU()
def forward(self, x):
# Operations that can be fused for efficiency.
return self.act(self.fc(x))
# Instantiate and transfer the model to GPU.
model = OptimizedNet().to("cuda")
# Compile the model using PyTorch 2.0's compiler.
# Behind the scenes, TorchInductor might use Triton for the GPU kernel.
compiled_model = torch.compile(model)
# Generate some dummy input data.
input_data = torch.randn(32, 512, device="cuda")
# Run the compiled model.
output = compiled_model(input_data)
print("Output shape:", output.shape)What happens under the hood is far from simple:
torch.compile()triggers TorchDynamo to capture theforwardmethod into an FX graph.- Optimizers fuse the
nn.Linearandnn.ReLUoperations. - TorchInductor receives the optimized graph (likely decomposed into PrimTorch ops).
- If targeting an Nvidia GPU, TorchInductor can invoke Triton to generate a highly efficient fused kernel for the linear layer + activation.
- This compiled kernel executes, bypassing much of the Python overhead of eager mode.
For complex models, this silent optimization can boost performance by 30-80% or more, often with just that single torch.compile() line.
Broader Implications: Breaking the Hardware Monopoly
This isn’t just about shaving milliseconds off inference times. The combination of PyTorch 2.0’s simplified primitive set and Triton’s accessible GPU programming model represents a fundamental challenge to the status quo hardware landscape, particularly Nvidia’s long-held dominance.
Lowering Barriers to Hardware Innovation
The CUDA moat was deep and wide. Building competitive AI hardware meant not just designing silicon but also replicating a vast, complex software ecosystem. PyTorch 2.0 drastically lowers the toll bridge:
- New hardware needs to target ~250 primitives, not 2000+ operators. A tractable problem.
- Vendors can focus engineering effort on optimizing this core set.
- Silicon can potentially be co-designed around these primitives for maximum efficiency.
Fostering Competition and Specialization
A more open, less monolithic stack naturally breeds diversity:
- AI Accelerators Emerge: Companies gain a viable path to build chips specialized for inference, specific training regimes (like sparsity), or novel architectures, knowing they can plug into the dominant framework.
- Cloud Providers Differentiate: Custom silicon efforts (like Google TPUs, AWS Trainium/Inferentia) become more strategic, less hampered by the need to perfectly emulate the incumbent’s software stack.
- Research Exploration: Academia and open-source hardware projects can experiment more freely without the crushing burden of full framework support.
Challenges and Limitations
This transition, however promising, is not without friction.
Technical Hurdles
- Compilation Lag: The initial
torch.compile()call can take significant time as the graph is captured, optimized, and compiled. This “warm-up” cost is problematic for latency-sensitive or interactive uses. - Debugging Obscurity: Errors arising from the compiled code can be significantly harder to trace back to the original Python source compared to eager mode’s directness.
- Optimization Gaps: The compilers aren’t magic. Not every PyTorch operation or pattern is perfectly optimized yet; performance gains can be inconsistent.
Ecosystem Inertia
- Tooling Entrenchment: Years of CUDA dominance have built a vast ecosystem of profilers, debuggers, libraries, and workflows. Replicating this for new backends takes time.
- Expertise Scarcity: CUDA wizards are plentiful; Triton and TorchInductor experts are still relatively rare. Talent follows established paths.
- Library Dependencies: Many critical libraries (eg., for specific scientific domains) have direct CUDA dependencies, creating integration headaches.
The Path Forward: A More Open AI Infrastructure
Despite the hurdles, the trajectory seems clear. The AI software stack is inexorably moving towards greater openness, modularity, and hardware independence. Several forces are accelerating this:
Industry Collaboration
Major players, despite competing fiercely, recognize the benefits of shared infrastructure:
- Meta (PyTorch), Google (JAX/OpenXLA), and others are contributing to common compiler intermediate representations and technologies.
- Hardware vendors realize supporting open standards is key to gaining traction.
- Cloud providers push for heterogeneity to avoid single-source dependencies.
Practical Benefits for AI Developers
For those actually building models, this shift translates to tangible advantages:
- Easier Optimization: Performance gains without necessarily becoming a low-level GPU programmer.
- Hardware Choice: Freedom to select hardware based on cost, performance, or availability, not just CUDA compatibility.
- Reduced Lock-in: Less dependence on a single vendor’s roadmap and pricing.
- Focus on Innovation: More time spent on algorithmic breakthroughs, less on hardware-specific tuning.
Conclusion: The Dawn of a New Era
The move away from a CUDA-dominated world towards a more open, compiler-driven AI ecosystem is arguably one of the most fundamental infrastructural shifts since deep learning took flight. PyTorch 2.0 and Triton are dismantling old barriers and laying the groundwork for a different kind of future.
As these technologies mature, the landscape will likely feature:
- A wider array of specialized AI hardware competing on merit.
- Potentially significant gains in computational efficiency and power reduction.
- A broader base of developers capable of high-performance AI work.
- Innovation accelerating as the friction between algorithms and hardware lessens.
The future belongs to those who understand and adapt to this evolving stack. The era where one company dictated the terms for AI computation is drawing to a close. What emerges will be more diverse, more competitive, and ultimately, more powerful.