Key Takeaways
- The Original Sin: Vocabulary Drift. The practice of training a tokenizer on one corpus and the model on another creates inevitable blind spots. These under-trained (or glitch) tokens are the ghosts in the vocabulary, capable of derailing a model into hallucination and incoherence.
- A Systematic Hunt. Magikarp isn’t guessing; it’s a three-stage pipeline. It analyzes the tokenizer’s structure, identifies anomalous embeddings, and verifies its suspicions with targeted prompts. A methodical, automated purge.
- A Pervasive Flaw. This isn’t a niche problem. Modern architectures like Llama 2, Mistral, and GPT-J are littered with hundreds of these rogue tokens. Scale up the vocabulary, as with Gemma, and the number of confirmed glitches explodes into the thousands.
- The Payoff: Security and Sanity. Excising these tokens reduces input sizes, cuts inference costs, and, crucially, reinforces the model’s guardrails against exploits and jailbreaks. It’s basic engineering hygiene.
- The Tool is Public. The entire pipeline is open-sourced at
cohere-ai/magikarpand works with any Hugging Face model. There is no excuse for not using it.
1 Why Should We Care About Tokenization?
Byte-Pair Encoding (BPE) became the de-facto standard after GPT-2 made it ubiquitous in 2019. It was a pragmatic choice, drastically reducing sequence length. But this efficiency came with a hidden cost: it locked every subsequent model into a fixed vocabulary. This decision creates a dangerous potential for drift. When the vocabulary is learned on one dataset and the model is later trained on another, rare-or even non-existent-tokens can slip through the cracks. This is the original sin of many modern training pipelines.
The infamous
_SolidGoldMagikarptoken, which lends this work its name, is a perfect artifact of this process. It appears a handful of times, if at all, in many common corpora, yet it persists zombie-like in multiple tokenizers. Feed this token to a model that has never been properly trained on it, and you don’t get magic. You get garbage.
2 What Exactly Are Under‑Trained Tokens?
These are the ghosts in the machine’s vocabulary: tokens the model saw too rarely, or never at all, during pre-training. They are not random noise; they are artifacts of the training process and fall into a clear taxonomy:
- Partial UTF‑8 sequences – orphaned byte fragments.
- Unreachable tokens – vocabulary entries that can no longer be produced by the tokenizer due to merge‑rule side effects.
- Special/control tokens – added manually (e.g.
<unused_123>), intentionally skipped during training.
Left unaddressed, they are more than just benign quirks. They are a parasitic drain on embedding capacity, an unnecessary inflation of prompt lengths, and a potential attack surface for pushing the model outside its trained distribution.
3 The Magikarp Detection Pipeline
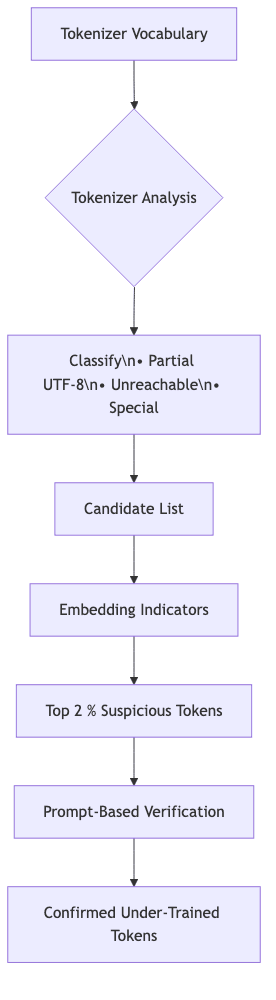
3.1 Tokenizer Analysis
The first stage is a cheap, structural sanity check. The pipeline walks the entire vocabulary and attempts to re-tokenize each entry. This immediately exposes merge-rule artifacts and byte fragments that the tokenizer can no longer physically produce. For large vocabularies, this simple filter can eliminate thousands of false positives before any model-heavy lifting begins.
3.2 Embedding‑Space Indicators
For the remaining candidates, we move from the tokenizer to the model’s own mind: its embedding space. The intuition is simple: tokens the model has never properly learned should have embeddings that are uninitialized or anomalous. We measure this anomaly. Let be the output embedding of token
and
the mean embedding of a small seed set of known unused tokens. The cosine distance indicator is:
This works because under-trained tokens haven’t been pushed and pulled by gradient updates into meaningful positions. They remain outliers. Low‑norm input embeddings work just as well for models with untied embeddings, providing another powerful signal.
3.3 Prompt‑Based Verification
Indicators can be noisy. The final stage is confrontational: we force the model to prove its knowledge. Every token flagged as highly suspicious is embedded in deterministic prompts that compel the model to repeat it. A well-trained model will do this with high confidence. An ignorant one will hesitate. If the predicted probability for the token remains near zero, its status as a glitch is confirmed. It has failed the test.
4 A Quick Python Walkthrough
from magikarp.fishing import fish
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "mistralai/Mistral-7B-v0.3"
model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto")
tok = AutoTokenizer.from_pretrained(model_id)
report = fish(model, tok) # returns a rich dict + writes Markdown report
print(report["stats"]) # {'vocab': 32000, 'candidates': 637, 'verified': 53}The complexity of the pipeline is abstracted away. The fish helper automatically discovers reference points for untied-embedding models and generates detailed Markdown reports suitable for committing directly to a repository. The diagnostic becomes a trivial, one-line addition to your workflow.
5 How Bad Is It in the Wild?
| Model | Vocab Size | Verified Under‑Trained |
|---|---|---|
| GPT‑2 Medium | 50 257 | 49 |
| GPT‑J 6B | 50 400 | 200 |
| Llama 2 7B | 32 000 | 20 |
| Mistral 7B v0.3 | 32 000 | 53 |
| Gemma 2B | 256 000 | 3 161 |
| Qwen 1.5 32B | 151 646 | 2 450 |
The table below uses Magikarp’s default 2 % threshold. The results are telling. Several clear patterns of decay emerge:
- Orphaned Bytes: Invalid UTF-8 sequences (often 0xF5–0xFF) are common offenders, representing fragments of characters the model never learned to assemble.
- Fossilized Fragments: The BPE merge process can leave behind intermediate tokens, like
_attRot, that become unreachable artifacts-fossils in the vocabulary. - Vestigial Tokens: Manually added special tokens (
<unused_123>), decorative emojis, or HTML tags that were part of the tokenizer’s training data but not the model’s, now serve no purpose.
6 Practical Recommendations
- Align Your Data. The most fundamental fix. Train your tokenizer on the exact same data distribution and pre-processing pipeline as the model itself. Avoid the original sin.
- Enforce Vocabulary Hygiene. Before training begins, unit-test the vocabulary. Re-encode every single token and assert that it can be perfectly reconstructed. Flag any unreachable artifacts from the start.
- Diagnose Early and Often. Run Magikarp after the first few pilot steps of a long training run. The immediate feedback can save you weeks of wasted compute on a model trained with a flawed vocabulary.
- Sanitize at the Edge. For models already in production, treat glitch tokens as hostile input. Strip or remap them at the inference layer before they can trigger unpredictable behavior.
7 Getting Hands‑On
The repository contains everything needed: detailed per-model reports, the one-liner to diagnose new models, and a registry for known tokenizer quirks. Clone it and run the diagnostics:
poetry install && poetry shell
python -m magikarp.fishing mistralai/Mixtral-8x7BThe output results/ folder provides the raw materials for deeper analysis: embedding plots, indicator histograms, and a final CSV of confirmed glitches.
8 Looking Forward
Tokenization is far from a solved problem. These diagnostics are a necessary stopgap, but the real trajectory is towards fundamentally better architectures. The areas I find most promising are:
- Byte‑level & adaptive tokenisers that dynamically prune unused entries.
- Weight‑decay strategies that gently pull dead embeddings toward a neutral vector instead of wasting capacity.
- Guardrail integration – automatically down‑weight or map glitch tokens at runtime to stop jailbreak chains before they start.
Conclusion
Under-trained tokens are the LLM equivalent of dark matter: invisible during training, but exerting a real, often disruptive, influence at inference time. They are a hidden source of model instability and a vector for exploits.
Magikarp provides the tools to drag this problem out of the realm of obscure curiosities and into the light of rigorous engineering. It makes the invisible visible, the unquantifiable measurable, and the problem fixable. This isn’t about chasing perfection; it’s about applying basic discipline to the construction of these complex systems.
Run the diagnostics on your own models. You might be surprised what lurks beneath the surface.