Key Takeaways
- Fine-tuning a 70-billion-parameter model like Llama 3.1 70B on a pair of 24GB consumer GPUs is no longer a theoretical exercise. It’s a reality, liberating us from the tyranny of expensive A/H-series accelerators.
- PyTorch Fully Sharded Data Parallel (FSDP) is the linchpin. It intelligently shatters all tensors-model parameters, gradients, and optimizer states-across available GPUs, killing the need for each device to hold a full model replica.
- QLoRA provides the second critical breakthrough. It puts the frozen base model into a 4-bit deep freeze, while small, surgically-inserted LoRA adapters are trained in full or mixed precision. Memory consumption plummets.
- With the right Hugging Face
accelerateconfiguration, the complexity of distributed training melts away. A single command ignites the training process, and another saves the consolidated results.
Core Techniques: FSDP and QLoRA Explained
To wrestle the immense memory requirements into submission, I relied on a two-pronged attack: FSDP to distribute the load, and QLoRA to shrink the model’s footprint.
1. Fully Sharded Data Parallel (FSDP)
FSDP is a sophisticated form of data parallelism native to PyTorch. Unlike traditional methods where each GPU holds a complete copy of the model, FSDP shards everything-parameters, gradients, and optimizer states-across your p GPUs. A full layer’s parameters are materialized only for the brief moment they are needed for computation, then immediately discarded.
It’s a clever piece of distributed systems engineering that works something like this:
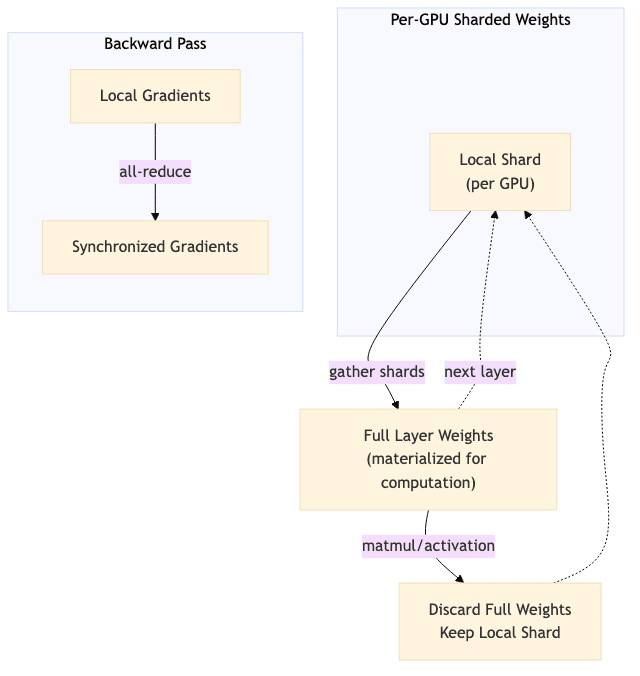
Diagram: The FSDP workflow. Each GPU holds only a fraction of the model. Shards are gathered to form a full layer for computation, then discarded. Gradients are synchronized via an all-reduce operation, keeping all GPUs in lockstep.
This approach decimates the memory burden on each device to a far more manageable equation:
Crucially for a consumer setup, FSDP also allows for offloading parameters to CPU RAM (fsdp_offload_params: true), turning your system memory into a VRAM extension.
2. QLoRA (Quantized Low-Rank Adaptation)
QLoRA is an elegant hack for memory-efficient fine-tuning. The core idea is to freeze the vast, pre-trained base model and quantize its weights to a mere 4-bits. You then inject small, trainable Low-Rank Adaptation (LoRA) adapters into the model’s architecture. These adapters are trained in a higher precision (like bfloat16), capturing the task-specific knowledge without touching the massive base model. The BitsAndBytes library handles the complex 4-bit quantization and de-quantization on the fly. This massively reduces the static memory footprint, allowing us to fit the 70B titan into our limited VRAM.
My Hardware & Software Setup
Here is the battle-tested configuration.
| Component | Minimum Specification | My Notes |
|---|---|---|
| GPUs | 2 × 24 GB (e.g., RTX 3090/4090) | I used two RTX 3090s. Mixed precision is the workhorse; NVLink is a luxury, not a necessity. |
| CPU RAM | 200 GB | Non-negotiable. This is where the magic of CPU offloading lives. Don’t skimp. |
| Storage | 500 GB NVMe SSD | Fast storage is critical for loading the model checkpoint and dataset without bottlenecks. |
| Software | PyTorch ≥ 2.2, Transformers ≥ 4.46, Accelerate ≥ 0.28, PEFT ≥ 0.10, BitsAndBytes ≥ 0.43 | FlashAttention-2 auto-installs if your GPUs speak BF16. Let it. |
Step-by-Step: Fine-Tuning Llama 3.1 70B
Let’s get to the code. Here are the practical steps to replicate this setup.
1. Install Dependencies
First, get the core libraries on board.
pip install --upgrade bitsandbytes transformers peft accelerate datasets trl2. Configure accelerate for FSDP
The accelerate library is the orchestration layer. You can generate a config file interactively with accelerate config, or create one manually. This file, config_fsdp.yaml, is the instruction manual for your distributed setup.
# config_fsdp.yaml
compute_environment: LOCAL_MACHINE
distributed_type: FSDP
num_processes: 2 # The number of GPUs in your coven
mixed_precision: 'no' # We'll control dtype manually in the script for precision
fsdp_config:
fsdp_auto_wrap_policy: TRANSFORMER_BASED_WRAP # A smart policy for wrapping transformer blocks
fsdp_sharding_strategy: FULL_SHARD # Shard everything: params, grads, and optimizer states
fsdp_offload_params: true # The secret sauce: offload shards to CPU RAM
fsdp_state_dict_type: SHARDED_STATE_DICT # Save sharded checkpoints to avoid OOM during saves
fsdp_cpu_ram_efficient_loading: true # Be gentle with CPU RAM on model load3. The Fine-Tuning Script Explained
Below are the key segments from my Python script, fsdp_qlora.py. One piece of hard-won tribal knowledge: the Accelerator object must be initialized at the absolute top of your script. Before you import torch, before you do anything else. This is critical for FSDP to hook into the process correctly.
# fsdp_qlora.py
from accelerate import Accelerator
# This must be the first thing you do. No exceptions.
accelerator = Accelerator()
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig, TrainingArguments
from peft import LoraConfig, get_peft_model, prepare_model_for_kbit_training
from trl import SFTTrainer, SFTConfig
from datasets import load_dataset
from peft.utils.other import fsdp_auto_wrap_policy
# Determine the right compute dtype and attention mechanism.
# BF16 is the native tongue of modern training; use it if your hardware speaks it.
compute_dtype = (
torch.bfloat16 if torch.cuda.is_bf16_supported() else torch.float16
)
attn_impl = 'flash_attention_2' if compute_dtype == torch.bfloat16 and torch.cuda.is_bf16_supported() else 'sdpa'
# BitsAndBytes configuration for QLoRA. This is where we define the quantization strategy.
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4", # NormalFloat4 is a solid choice for quantization.
bnb_4bit_use_double_quant=True, # Minor precision gains, but why not?
bnb_4bit_compute_dtype=compute_dtype,
bnb_4bit_quant_storage=torch.uint8, # Using uint8 for storage seems to play nicer with FSDP.
)
# Load the model.
# Authenticate with Hugging Face if you haven't already.
model_id = "meta-llama/Meta-Llama-3.1-70B"
model = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config=bnb_config,
torch_dtype=compute_dtype,
attn_implementation=attn_impl,
use_cache=False, # Mandatory for training with gradient checkpointing.
device_map={"": accelerator.device} # Maps model parts to the correct FSDP device.
)
# Load the tokenizer.
tokenizer = AutoTokenizer.from_pretrained(model_id)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token # A common fix: use EOS as PAD.
# --- Prepare model for k-bit training and LoRA ---
model.gradient_checkpointing_enable(gradient_checkpointing_kwargs={'use_reentrant': True})
# PEFT LoRA configuration. Define the surgical attachments.
peft_cfg = LoraConfig(
r=16, # Rank of the LoRA matrices. 16 is a reasonable starting point.
lora_alpha=16, # Alpha scaling. Conventionally same as r.
lora_dropout=0.05, # Dropout for LoRA layers to prevent overfitting.
bias='none',
target_modules=[ # Standard target modules for Llama models.
'q_proj', 'k_proj', 'v_proj', 'o_proj',
'gate_proj', 'down_proj', 'up_proj'
],
task_type="CAUSAL_LM"
)
# No dataset? No excuse. Here's a dummy to get the machinery turning.
from datasets import Dataset
dummy_data = {"text": ["This is a sample sentence for fine-tuning Llama."] * 100}
ds = Dataset.from_dict(dummy_data)
ds = ds.train_test_split(test_size=0.1)
# In a real scenario, you'd load your actual dataset here.
# e.g., ds = load_dataset("argilla/ultrafeedback-binarized-preferences-cleaned", split="train_sft")
# SFTConfig / TrainingArguments: Tune the metabolism of your training run.
training_args = SFTConfig(
output_dir="./llama3-70b-qlora-results",
per_device_train_batch_size=1,
gradient_accumulation_steps=8, # Effective batch size = 1 * 8 * 2 (gpus) = 16
learning_rate=1e-4,
max_steps=100, # A smoke test. Increase for a real run.
logging_steps=10,
bf16=(compute_dtype == torch.bfloat16),
fp16=(compute_dtype == torch.float16),
dataset_text_field="text",
)
trainer = SFTTrainer(
model=model,
train_dataset=ds['train'],
eval_dataset=ds['test'],
peft_config=peft_cfg,
tokenizer=tokenizer,
args=training_args,
max_seq_length=1024, # Adjust based on your data and VRAM.
)
# The SFTTrainer, working with accelerate, should handle FSDP wrapping automatically.
# Explicit wrapping is a fallback for complex or stubborn cases.
# Start training.
trainer.train()
# Save the final LoRA adapter model.
# The trainer's save_model method is FSDP-aware and handles consolidation.
output_dir = "./llama3-70b-qlora-adapters"
trainer.save_model(output_dir)
accelerator.print(f"Training complete. LoRA adapters saved to {output_dir}")To ignite the training process, run this command from your terminal:
accelerate launch --config_file config_fsdp.yaml fsdp_qlora.pyObserved Training Performance
So what does this intricate dance of sharding and quantization actually cost in time and resources? I ran a 100-step smoke test on my dual RTX 3090 system to find out.
| Metric | Value (2 × RTX 3090, 200 GB RAM) |
|---|---|
| Wall-clock time (100 steps, batch 16) | ≈ 15 hours |
| Peak Host RAM Usage | ≈ 180 GB |
| Peak GPU VRAM Usage (per GPU) | ~22.8 GB |
These figures aren’t just data points; they are proof. The FSDP + QLoRA combination successfully contained the Llama 3.1 70B model within the strict memory confines of my consumer hardware, while delivering stable, if not blistering, training throughput.
Troubleshooting Common Issues
The path to success is paved with errors. Here are a few I encountered, and how to pave over them.
| Symptom | Likely Cause | Suggested Fix |
|---|---|---|
| The dreaded OOM before step 1 | Something isn’t correctly quantized or offloaded. Often a conflict between BitsAndBytes and FSDP. |
Double-check BitsAndBytesConfig. Ensure fsdp_offload_params: true is active. Your best bet is often setting bnb_4bit_quant_storage=torch.uint8. |
| Model loads twice, then OOMs | Accelerator() was initialized too late. A classic mistake. |
Move accelerator = Accelerator() to the very top of your script. It must be first. |
| 8-bit Adam optimizer explodes | 8-bit optimizer states can still be memory hogs, even when sharded. CPU offloading for optimizers can be finicky. | Retreat to the safety of a 32-bit Adam variant like adamw_torch. It’s more memory-intensive but far more stable. |
| Your machine is gasping for air (RAM) | Host RAM is insufficient for the offloaded shards and optimizer states. The system is thrashing. | Add more physical RAM. It’s the cleanest solution. Adding swap is a slow, painful last resort. A third GPU would also spread the load further. |
| NCCL errors or training hangs | A breakdown in inter-GPU communication. The usual suspects are drivers or environment variables. | Ensure your CUDA, PyTorch, and NCCL versions are a happy family. Use NCCL_DEBUG=INFO for clues. Sometimes, a simple reboot is the most effective fix. |
Final Thoughts
The notion of wrangling a 70-billion parameter model on hardware you could buy from a consumer electronics store felt, until recently, like pure fantasy. As demonstrated, the powerful combination of FSDP and QLoRA, brilliantly orchestrated by the Hugging Face ecosystem, has made it a concrete reality.
No, the training process is not a coffee-break affair. You’re looking at overnight runs, not rapid iterations. But the ability to customize state-of-the-art LLMs without a data center’s budget is a profound shift in the balance of power. This unlocks incredible potential for personal projects, academic research, and smaller enterprises to compete on a more level playing field. If you can afford a third GPU, or leverage cloud spot instances, a production-grade fine-tuning pipeline is now within your grasp at a fraction of its historical cost.
I hope this guide gives you the confidence to start experimenting. The gates are open.
Happy fine-tuning.