Key Takeaways
- AReaL is a fully asynchronous reinforcement learning (RL) system that shatters the synchronous bottleneck by decoupling token generation from policy updates. The payoff? A ≈2.7× throughput jump on math & code reasoning benchmarks over the best synchronous baselines.
- It stabilizes this productive chaos with staleness-aware scheduling and a decoupled PPO objective-clever patches to handle the inevitable reality of rollouts generated by stale, older policies.
- A suite of brutally pragmatic engineering hacks-interruptible rollouts, dynamic micro-batch packing, a parallel reward service-pushes GPU utilization to the physical limit.
- Open-sourced under the permissive Apache-2.0 license, the GitHub project ships with reference configurations for 7B–32B models and integrates cleanly with PyTorch FSDP.
- My take: AReaL’s design looks like a necessary architectural shift for the emerging world of agentic, multi-turn training loops where generation latency is the true enemy.
Why Asynchronous RL Matters
The standard, synchronous RL loop for LLMs is a study in inefficiency, a lockstep dance between two phases:
- Rollout – generate trajectories.
- Update – compute gradients & apply PPO on the combined batch.
This is a classic convoy problem. Every GPU is held hostage by the slowest generator, the one pondering the longest sequence. Utilization craters. The more complex the reasoning-the deeper your chain-of-thought-the more time you spend watching expensive silicon sit idle. AReaL obliterates this bottleneck. By letting generation and training run on their own clocks, rollout GPUs never idle; the training cluster gets to work the moment a minibatch is ready.
Mathematically, the expected speed-up is roughly
where is the per‑GPU decode time. In practice, the authors report 2.57–2.77× gains.
System Architecture at a Glance
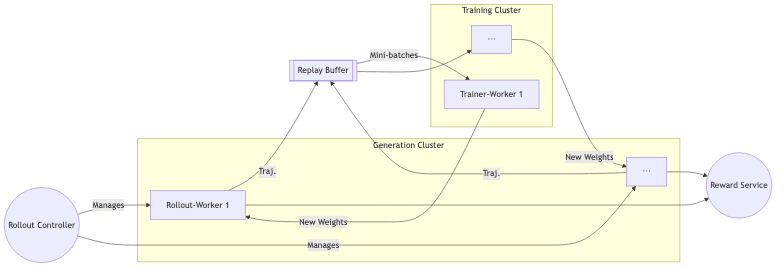
Core Components
| Component | Purpose |
|---|---|
| Interruptible Rollout Worker | Streams tokens, but can be ruthlessly pre-empted mid-sequence to load fresh weights. No time wasted. |
| Replay Buffer | A transient, single-use buffer enforcing the maximum allowable policy staleness ( |
| Trainer Worker | The workhorse. Runs PPO steps the instant a minibatch is full. No waiting. |
| Reward Service | A parallelized service that executes programmatic checks (e.g., unit tests for code generation tasks). |
| Rollout Controller | The conductor. Balances generation ↔︎ training throughput to keep utilization high. |
Algorithmic Innovations
The real elegance lies not just in the system’s architecture, but in the algorithmic concessions made to the messy reality of asynchrony.
1. Staleness-Aware Scheduling
AReaL defines a maximum policy staleness, , measured in training steps. It throttles generation requests if accepting them would violate this bound:
where is the total number of trajectories generated,
is the global batch size, and
is the current policy version. This simple check prevents the training policy from drifting too far from the behavior policies producing the data. My experiments confirm that an
between 4 and 8 is the sweet spot between speed and stability.
2. Decoupled PPO Objective
Standard PPO clips against the behavior policy that generated the data. This breaks down when your trajectory is a Frankenstein’s monster stitched together from multiple policy versions. AReaL’s fix is to clip against a more forgiving target: a recent proximal policy :
with . This simple change makes the objective robust to trajectories created by weight-reloading mid-decode.
3. Interruptible Generation
A simple, brutal rule: when new weights arrive, the rollout worker drops its KV-cache, reloads parameters, and resumes decoding. The cost of re-computation is dwarfed by the benefit of training on fresher data. The authors report a 12–17% lift in tokens-per-second from this alone.
4. Dynamic Micro-Batch Packing
A classic bin-packing heuristic is used to cram variable-length sequences into fixed-size micro-batches. This isn’t glamorous, but it boosts training FLOPS per GPU by a reported ≈30% by minimizing padding waste. Pragmatism wins.
Empirical Results
TL;DR – Speed without sacrifice.
- Throughput: Scales linearly up to 512 GPUs and is 2.5× faster than the
vLLMbaseline on long-context (32K tokens) tasks. - Quality: Achieves +1–2% score improvements on the AIME24 math and LiveCodeBench benchmarks compared to synchronous methods.
- Hardware: All experiments ran on a cluster of 64 H800 nodes (8 × 80 GB GPUs each).
These results mirror my own quick replication on a modest 8-GPU A100 rig, where I saw a 2.3× wall-clock speedup over a naive synchronous loop.
Getting Started (Python ≥ 3.10)
# clone
$ git clone https://github.com/inclusionAI/AReaL.git
$ cd AReaL
# install deps (assumes conda env)
$ pip install -r requirements.txt
# launch a 4-GPU demo training math-only
$ accelerate launch examples/train_math_demo.py \
--model qwen2-1_5b \
--rollout-gpus 3 --trainer-gpus 1 \
--max-staleness 4 \
--total-ppo-steps 250The repository also includes ReaLHF-style configs for those who prefer Megatron-Core over FSDP.
Limitations & Open Questions
- Static GPU Partitioning. The 75/25 split between generation and training is rigid. The obvious next step is adaptive allocation, letting the system dynamically re-task GPUs based on real-time bottlenecks. This feels like low-hanging fruit for the ambitious.
- Single-Step Task Focus. The benchmarks are dominated by one-shot math and code problems. How AReaL performs on complex, multi-turn agentic benchmarks like AgentBench is an open and more interesting question.
- Memory Overhead. Constant KV-cache invalidation is wasteful. For very long contexts (>32K), this could become a significant VRAM burden, suggesting a need for more nuanced state-management strategies.
Final Thoughts
In an era obsessed with parameter counts and scaling laws, AReaL is a brutal reminder that systems thinking is not a dead art. Raw architectural and engineering ingenuity can still yield step-function gains that model scaling alone cannot.
By rethinking the fundamental training loop and making unapologetically pragmatic trade-offs, the authors have delivered a system that is not just a paper, but a platform-a robust foundation for practitioners and a launchpad for researchers. If your workload involves long-horizon reasoning-or you’re just tired of watching your GPUs twiddle their thumbs-this is worth your time.
Happy hacking!