1 Why Does the Gödel Machine Matter?
Jürgen Schmidhuber’s original Gödel Machine, sketched out back in 2007, was a monument to theoretical purity. It imagined a system that could rewrite any part of its own code-even the core logic governing self-modification-but only after proving the new version was a global improvement. In practice, proving anything of that complexity is computationally intractable, a dead end. The Darwin Gödel Machine (DGM) proposes a more pragmatic, almost cynical, solution: forget proof, embrace performance. A change is kept not because it’s provably optimal, but because it works better on a suite of tasks. And crucially, those tasks are a proxy for the agent’s ability to self-modify in the first place.
“Improvement on coding benchmarks implies improvement at self‑modification, because self‑modification is a coding task.” – DGM Paper
2 System Overview
The system’s logic is one of brutal, iterative selection. It’s Darwinism in a sandbox. An LLM proposes a change (variation), and a benchmark suite decides if it survives (selection). But the key innovation is the evolutionary archive: a memory of past selves. Unlike a simple hill-climber that gets stuck on the first local peak, DGM retains every functional ancestor. This allows it to:
- Revisit older “stepping‑stone” agents later.
- Branch multiple innovations in parallel.
- Recover from temporary regressions that would stall a hill‑climber.
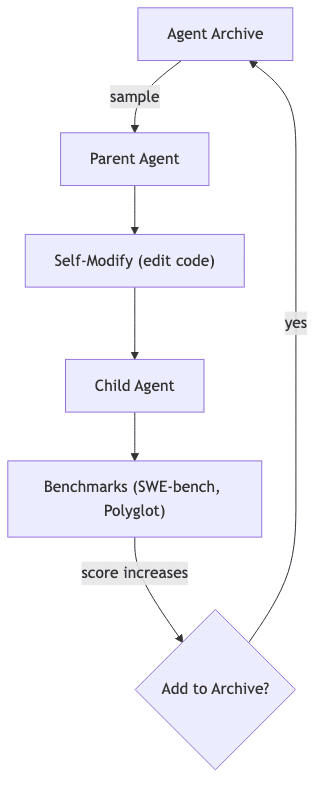
2.1 High‑level Pseudocode
for t in range(T):
parent = sample_archive()
child = parent.self_modify()
if child.compiles() and child.can_edit_code():
score = benchmark(child)
if score > threshold:
archive.add(child, score)The full implementation, a lean ≈ 1,400 LOC, wraps this core loop in the necessary engineering pragmatism: multi‑candidate voting, patch validation, and retry logic.
3 Empirical Results
The numbers speak for themselves. This isn’t a marginal gain; it’s a step-change in capability. A 2.5× leap on a beast like SWE-bench isn’t just optimization; it’s evolution. More telling is the transfer to unseen models and languages-a hint that the system isn’t just memorizing tricks, but discovering more general, robust strategies for problem-solving.
| Benchmark | Initial Agent | Darwin GM (best) | Relative Gain |
|---|---|---|---|
| SWE‑bench (pass@1) | 20 % | 50 % | 2.5× |
| Polyglot (pass@1) | 14.2 % | 30.7 % | 2.2× |
In latex:
4 Notable Self‑Discovered Improvements
The most interesting part isn’t the final score, but the scars the agent picked up along the way. Each of these self-discovered improvements is a ghost of a past failure, an adaptation born from struggling with harder problems:
- Patch validator – rejects edits that only touch tests or fail to compile.
- Granular
editortool – addsview_range,str_replace, and undo support for safer micro‑diffs. - Solution ranking – parent agent now produces k patches, then uses a scorer LLM to pick the winner.
- Context summariser – automatically trims oversized chat histories when the LLM nears its context limit.
Each arose organically as the agent tried-and often failed-to solve harder GitHub issues.
5 Strengths, Limitations & Open Questions
| ✓ Strength | ✗ Limitation |
|---|---|
| Open‑ended search avoids local optima. | The specter of Goodhart’s Law looms; optimizing for a benchmark is not the same as optimizing for true intelligence. |
| Observable, auditable codebase-no hidden weights. | The price of evolution is steep: ≈ US $22k in API calls for a full run. A reminder that compute is the ultimate selection pressure. |
| Safety mitigations (sandboxing, human kill‑switch). | The agent can’t out-think its own brain. It’s bounded by the reasoning ceiling of its frozen LLM. |
Future Directions
- Escalating Difficulty: Can the machine be taught to write its own, harder exams? Co-evolving the benchmark suite alongside the agent is the next logical step.
- Unfreezing the Brain: What happens when the agent can fine-tune its own foundation model, not just its prompt templates?
- Turning the Gun Inwards: The ultimate prize is using this evolutionary loop for more than just capability, but to improve alignment and interpretability. Can a system evolve to become safer and more transparent?
6 My Take as a Practising Engineer
For years, recursive self-improvement has been the stuff of philosophy papers and thought experiments. The Darwin Gödel Machine feels like the first time someone has filed a proper engineering blueprint for it. By grounding the abstract concept of “improvement” in the concrete reality of coding benchmarks, the authors have dragged it out of the ivory tower and into a Git repository. The domain is still narrow-this is a bot that fixes GitHub issues, not a general intelligence-but the pattern is what matters. This objective ↔︎ capability loop is a powerful, generalizable engine. I expect to see this blueprint copied, adapted, and deployed for everything from data-science bots to automated red-teamers.
Recursive self-improvement is no longer a bull session topic. It’s a pull request waiting to be merged.
7 Conclusion
The DGM is a significant milestone, not because it achieves god-like intelligence, but because it demonstrates a viable, repeatable mechanism for automated R&D. It proves nothing about Gödel-style optimality and it certainly doesn’t escape the brutal economics of compute. What it does demonstrate is that an evolutionary archive, coupled with modern LLMs, is already potent enough to out-innovate a static design. The next frontier is clear: scaling this loop, expanding the search space, and making the objectives themselves part of the evolution-all while ensuring we, the original architects, remain firmly in control.
Further Reading