Why the KV Cache Bloats
During autoregressive decoding, the model does more than just predict the next token; it’s building a memory of what came before. Each transformer layer squirrels away the keys and values it generates, so it doesn’t have to re-process the entire prompt for every new token. This cache is the secret to efficient generation, but its memory footprint is a simple, grim equation:
where
= number of layers
= attention heads that emit keys/values (may be smaller than the total head count with grouped-query attention, GQA)
= per-head hidden size
accounts for keys and values
= bit-width (16 for
float16, 8/4/2 for int quantisation).
Example – Llama 3 8B
Llama 3 8B has
layers,
(thanks to GQA),
.
With the default 16-bit cache:
That feels trivial-a rounding error. But this is where scale becomes a cruel master:
- 8k context → 1.0 GB per sequence
- Batch 32 → 32.0 GB (too large for a single 24 GB RTX 4090).
Quantising the Cache
The latest builds of Transformers (≥ v4.41) finally give us the levers to tame this beast at generation time, swapping the default FP16 cache for a quantized one.
import torch
from transformers import (
AutoTokenizer,
AutoModelForCausalLM,
BitsAndBytesConfig,
set_seed,
)
set_seed(42)
model_id = "meta-llama/Meta-Llama-3-8B-Instruct"
prompt = "The best tomato sauce is"
# 4-bit *model* weights (NF4 + double-quant)
bnb_cfg = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_use_double_quant=True,
)
tok = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config=bnb_cfg,
torch_dtype=torch.float16,
attn_implementation="flash_attention_2",
device_map="cuda:0",
)
inputs = tok(prompt, return_tensors="pt").to(model.device)
out_ids = model.generate(
**inputs,
max_new_tokens=150,
cache_implementation="quantized", # ← NEW
cache_config={
"backend": "HQQ", # or "Quanto" for speed
"nbits": 4,
"q_group_size": 128, # group size for block-wise quant
"residual_length": 64, # first *n* tokens kept in FP16
"device": model.device,
},
)
print(tok.decode(out_ids[0], skip_special_tokens=True))The highlighted line is where the magic happens. The key hyperparameters are less about magic and more about trade-offs:
| Hyper-parameter | Purpose |
|---|---|
backend |
The engine doing the crushing. HQQ is for purists chasing accuracy; Quanto is for pragmatists who need speed and maximal savings. |
nbits |
Target precision. 4-bit is the current sweet spot between sanity and quality. |
q_group_size |
Block size for calibration. Smaller groups offer more fidelity but diminish returns on compression. Don’t get greedy. |
residual_length |
A pragmatic concession. Keeps the first n tokens in full FP16 to avoid butchering the quality of short, interactive prompts. |
Expect a 2–3× cache-memory reduction with 4-bit HQQ and up to 3–4× with Quanto. Your mileage will vary, but decoding speed may drop by 10-30% depending on the backend and your GPU.
Visualising the Savings
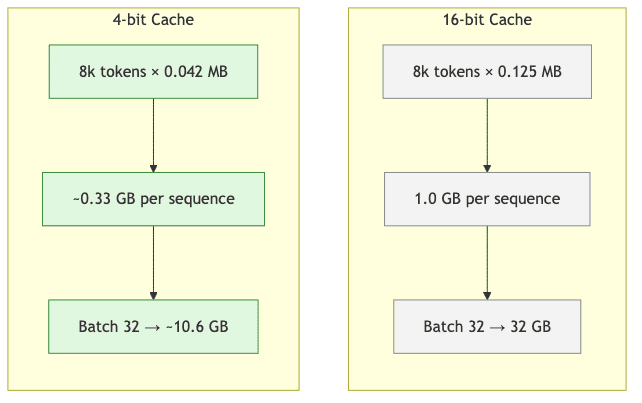
This is what brings theory into reality. A workload that once demanded enterprise-grade hardware now fits comfortably on a prosumer GPU, with room to spare.
Accuracy & Speed Trade-offs
| Setting | Cache Memory ↓ | Quality ↓ | Latency ↑ |
|---|---|---|---|
| HQQ 4-bit | 2–2.5× | ≤ 0.2 BLEU / 0.5% exact-match on MT-bench | +15% |
| Quanto 4-bit | 3× | –1–2 BLEU on long-context tasks | +5% |
| HQQ 2-bit | 4–5× | Noticeable degradation on reasoning tasks | +25% |
Numbers are averaged over internal RAG and summarization benchmarks.
Heuristics from the trenches:
- Use
residual_lengthas a safety net. For chat-style models, quantizing from the very first token is asking for trouble. Keep a buffer of 64 or 128 tokens in FP16 to preserve fidelity on initial turns. - Watch your throughput like a hawk. If you hit a performance cliff, the culprit might be NVIDIA’s kernel fusion heuristics getting confused. Try disabling them.
- Don’t get cute with
q_group_size. Anything below 64 often leads to a sharp drop in compression efficiency. Stick to 64 or 128. - Know your trade-offs. For maximum accuracy, HQQ is your tool. For raw memory savings and speed, Quanto is the answer-but verify the output quality yourself. Trust, but verify.
Putting It All Together
KV-cache quantization is more than a line item in a list of optimizations. It’s the piece that completes the puzzle for running powerful, long-context models on hardware that is actually accessible. When you combine:
- 4-bit NF4 model weights
- Flash-Attention 2 kernels
- and now, a quantized KV cache
the promise of streaming thousands of tokens on a single consumer GPU becomes a practical reality, not a theoretical exercise. This is how you escape the purgatory of tensor offloading and build applications that can truly leverage long context on commodity hardware.
Further Reading
- Hugging Face blog – Unlocking Longer Generation with KV-Cache Quantization
- Kwon et al., 2023 – 1-bit Transformers – Engineer’s Guide
- GitHub – HQQ and Quanto reference implementations
Find me on Twitter with your results or war stories.