1. Introduction
Language agents are the current frontier. We’ve moved past simply getting machines to spit out plausible text; now we’re trying to get them to do things. They’re poking at web browsers, juggling APIs, manipulating interfaces, even driving robots. These aren’t just glorified Markov chains anymore; they aspire to observe, reason, plan, and actually interact with the world in a meaningful way.
But let’s be honest. Under the hood, how do these things actually work? As capabilities balloon, the uncomfortable questions multiply:
- How does an agent organize the firehose of information it encounters? Where does knowledge live?
- What governs its choices? Is it just sophisticated pattern-matching, or is there something like deliberate decision-making?
- How does it tackle anything complex, anything requiring memory beyond a fleeting context window, anything resembling a plan?
The paper Cognitive Architectures for Language Agents (CoALA) steps into this fray. It doesn’t claim to have invented AGI, but it offers something arguably more useful right now: a framework. It proposes a way to structure these agents, drawing not just on the latest LLM magic, but on decades of hard-earned wisdom from cognitive science and the often-maligned field of symbolic AI. CoALA offers a modular, potentially extensible blueprint for building agents that are less like inscrutable black boxes and more like engineered systems.
In this piece, we’ll dig into how CoALA attempts to bridge the gap between classical AI thinking and the brute force power of modern LLMs. It’s about imposing some architectural discipline on the generative wild west, offering a path towards agents that might be more capable, reliable, and maybe, just maybe, a little more understandable.
2. The Evolution from Symbolic AI to Modern Language Agents
To really grasp what CoALA is trying to achieve, we need a quick detour through AI history. It didn’t all start with Transformers.
2.1 The Era of Production Systems
Way back, before neural networks were cool (the first time), AI researchers were wrestling with fundamental computation. Production systems were one early model: simple rules for rewriting strings.
LHS → RHSThink IF condition THEN action. The left-hand side (LHS) spots a pattern; the right-hand side (RHS) dictates the change. Pioneers like Post and Turing used these ideas to explore the very limits of computation.
AI researchers quickly co-opted this. Instead of just text, the LHS could match environmental states, and the RHS could trigger actions. Systems like STRIPS and OPS5 showed you could build surprisingly intelligent-seeming behavior from these simple rule engines. They were brittle, yes, but they were structured.
2.2 The Rise of Cognitive Architectures
By the 70s and 80s, folks like Newell, Simon, and Anderson started thinking bigger. How does human intelligence work? How do we juggle immediate tasks with vast stores of knowledge? How do perception, reasoning, and action intertwine?
Their answers manifested as cognitive architectures. They were comprehensive blueprints for intelligence, specifying how different knowledge types should be organized and how decisions unfold over time. They introduced crucial distinctions that we often take for granted:
- Working memory: The cognitive scratchpad, holding what’s active right now.
- Long-term memory: The stable repository of facts, experiences, skills.
- Procedural knowledge: The “how-to” knowledge, ingrained skills.
Landmark systems like Soar and ACT-R embodied these principles. They were theories of cognition made computational, forming the bedrock for a generation of AI research.
2.3 Language Models as Probabilistic Production Systems
Fast forward to today. LLMs look radically different, built on neural networks and trained on internet-scale data. Yet, at a conceptual level, they echo those old production systems. Given an input (prompt), they produce an output (continuation) – rewriting one string into another.
The key differences are staggering, of course:
- Implicit vs. Explicit: LLMs learn billions of implicit rules from data, rather than relying on hand-crafted logic.
- Probabilistic vs. Deterministic: They generate a distribution over possibilities, not a single deterministic output.
- Steering vs. Programming: We guide them with prompts, nudging them towards desired patterns rather than explicitly coding rules.
Recognizing LLMs as powerful, probabilistic pattern-matchers helps explain both their uncanny abilities and their frustrating limitations (like their lack of inherent memory or common sense).
2.4 The Emergence of Language Agents
An LLM alone is just a text machine. To make it an agent – something that acts in a world – you need more plumbing:
- Perception: Ways to translate the state of the world (a webpage, sensor data) into text the LLM can understand.
- Action: Ways to parse the LLM’s text output into commands the environment understands (API calls, mouse clicks).
- Memory: Systems to hold context, history, and knowledge beyond the LLM’s fixed parameters and limited context window.
This creates the feedback loop: observe -> reason (via LLM text generation) -> act -> observe new state. Most current agent work involves variations on this loop, often cobbled together.
CoALA enters here, aiming to replace ad-hoc structures with principles borrowed from those cognitive architectures, providing a more robust framework for organizing these essential components.
2.5 Historical Evolution of AI Approaches
Here’s the lineage in one glance:
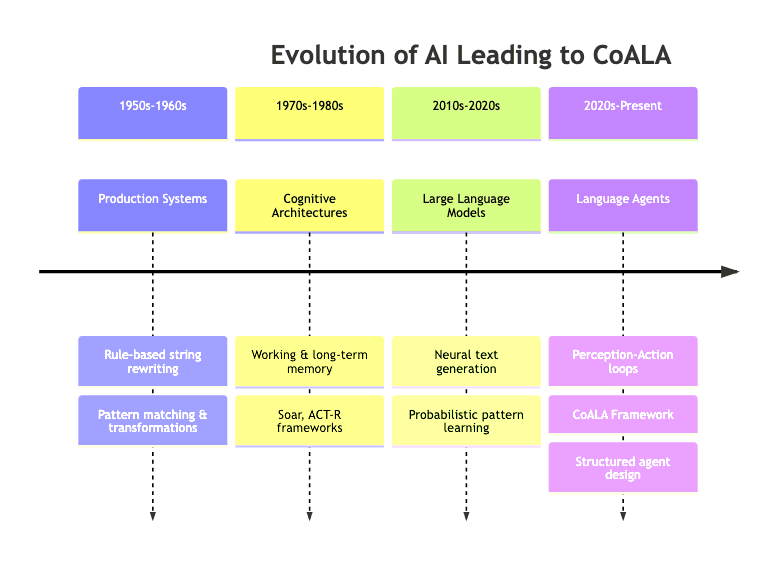
CoALA isn’t starting from scratch; it stands on the shoulders of giants, attempting to synthesize decades of AI thought with the raw power of modern models.
3. The CoALA Framework: A Modular Blueprint
So, what is CoALA? At its heart, it proposes a three-part structure for language agents, aiming to bring some order to the potential chaos:
- Memory Systems: Giving the agent a structured past and knowledge base.
- Action Space: Defining what the agent can do, both internally and externally.
- Decision-Making Procedure: Specifying how the agent chooses its next move.
This tripartite division isn’t arbitrary; it reflects fundamental aspects of cognition and provides a principled way to design and reason about complex agent behavior.
3.1 Memory Modules: Beyond Context Windows
Raw LLMs are fundamentally amnesiac. Each interaction is fresh, save for the limited text stuffed into the context window. This is a critical failure point for complex tasks. CoALA directly tackles this by proposing distinct memory systems, inspired by cognitive science:
Working Memory
The agent’s immediate focus, its cognitive scratchpad. This holds:
- The current task or query.
- Chains of thought, intermediate reasoning steps.
- Partially formed plans or solutions.
- Active goals and subgoals. Working memory is ephemeral, constantly updated as the agent thinks and acts.
Episodic Memory
The agent’s diary, storing sequences of past events:
- Previous user interactions.
- Records of environmental actions and their outcomes.
- Successfully completed tasks (and failures).
- Errors encountered and perhaps corrections made. This allows the agent to recall past specifics, learn from mistakes, and maintain continuity over time.
Semantic Memory
The agent’s stable knowledge base:
- Facts about the world (domain-specific or general).
- Conceptual relationships (ontologies).
- Potentially, procedural knowledge distilled into facts (“how-to” guides). Semantic memory grounds the agent, providing access to information beyond the LLM’s parametric knowledge (which might be outdated or hallucinated).
Procedural Memory
The agent’s repertoire of skills and capabilities:
- The LLM itself (its learned language patterns are a form of procedural knowledge).
- The agent’s own codebase and execution logic.
- Libraries of pre-defined functions or skills it can call.
- Learned strategies for tackling specific problem types. Sophisticated agents might even update this memory, effectively learning new skills – a powerful but potentially risky capability.
Memory System Organization
![WM[Working Memory]](https://n-shot.com/wp-content/uploads/research-5-CoALA_diagram_flowchart_2_WM_Working_Memory.png)
This structured approach means knowledge isn’t just dumped into a single vector store. Rather it’s organized functionally, mirroring cognitive principles to (hopefully) enable more effective recall and use.
3.2 Action Space: Internal Cognition and External Effects
CoALA makes a vital distinction: not all actions are created equal. Some affect the outside world, while others are purely internal “thoughts.”
External Actions (Grounding)
These are the actions that bridge the agent’s internal world to external reality:
- Clicking buttons, filling forms on a website.
- Calling APIs.
- Sending commands to a robot’s motors.
- Speaking or typing responses to a human. These actions have consequences, change the environment, and are usually how the agent achieves its goals.
Internal Actions
These modify the agent’s own cognitive state, part of its deliberation process:
Reasoning Actions:
- Generating intermediate “thoughts” (like chain-of-thought).
- Evaluating different possible plans or strategies.
- Breaking down complex goals into smaller, manageable steps.
- Self-critique or verification of potential solutions.
Retrieval Actions:
- Querying episodic memory (“Have I seen this before?”).
- Accessing semantic memory (“What are the facts about X?”).
- Searching procedural memory (“Do I have a skill for this?”).
- Focusing attention on specific parts of working memory.
Learning Actions:
- Summarizing recent experiences to store in episodic memory.
- Generalizing knowledge from specific events for semantic memory.
- Updating beliefs based on new observations.
- Refining skills in procedural memory based on success or failure.
Explicitly defining these internal actions elevates the agent beyond a simple reactive system, allowing for structured deliberation and learning.
Action Space Categorization
![IA[Internal Actions]](https://n-shot.com/wp-content/uploads/research-5-CoALA_diagram_flowchart_3_IA_Internal_Actions.png)
This taxonomy helps designers consider the balance between “thinking” (internal actions) and “doing” (external actions).
3.3 Decision-Making: The Cognitive Cycle
The engine driving a CoALA agent is its decision cycle – a structured loop governing how it behaves over time:
1. Planning Phase
Before acting, the agent engages in internal deliberation:
- It retrieves relevant information from its memory systems.
- It reasons to generate potential actions or plans.
- It evaluates these options, perhaps simulating outcomes.
- It develops a coherent plan, from simple next steps to complex multi-stage strategies.
2. Execution Phase
Having deliberated, the agent commits:
- It selects the action deemed most promising.
- It executes that action – either an external one affecting the world, or an internal learning action modifying its own knowledge.
- It observes the result (new environmental state or internal change).
3. Cycle Repetition
This loop – Plan, Execute, Observe – repeats. The agent continually perceives, thinks, acts, and learns until the task is done, interrupted, or deemed impossible. This structured cycle encourages systematic problem-solving rather than purely reactive responses.
Visual Representation of the Cognitive Cycle

This cognitive cycle provides the rhythm for the agent’s operation, integrating perception, memory, reasoning, action, and learning into a continuous flow.
3.4 CoALA Architecture: Visual Overview
Putting it all together, the CoALA framework looks something like this:
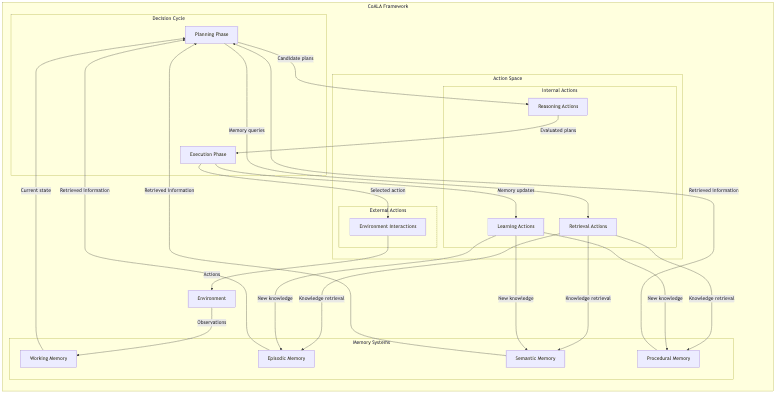
This diagram shows the blueprint: distinct memory modules feeding into a decision cycle that orchestrates internal and external actions based on observations from the environment. It’s a map for building agents with more internal structure.
4. CoALA in Practice: Exemplar Systems
Many existing language agent systems, consciously or not, instantiate parts of CoALA framework. Looking at them through the CoALA lens is instructive:
ReAct: Reasoning + Acting
A widely cited approach, ReAct, clearly demonstrates interleaving internal reasoning and external action.
- The LLM generates both a “thought” (internal reasoning) and an “action” (external command).
- The action changes the environment, producing a new observation.
- Observation + previous thought/action feed the next cycle. ReAct is essentially a simple CoALA cycle with limited memory (mostly just the prompt context). It shows the power of even basic structured deliberation.
Voyager: Minecraft Agent with Skill Acquisition
Voyager tackles the complex, open-ended world of Minecraft, showcasing a more fleshed-out CoALA implementation:
- Memory: Explicit procedural memory (Python skill library), episodic memory (task attempts), semantic memory (game knowledge).
- Decision Cycle: Retrieves skills, reasons about combining them, learns new code-based skills via LLM prompting when stuck, executes in the game. Voyager is a compelling example of how CoALA’s components enable cumulative learning and adaptation in a complex domain.
Tree-of-Thoughts: Deep Deliberative Reasoning
While often used for single-shot problem solving rather than continuous interaction, Tree-of-Thoughts (ToT) exemplifies sophisticated internal reasoning actions within a CoALA-like structure:
- It explicitly generates and explores multiple reasoning paths (branches of the tree).
- It evaluates candidates (nodes) and prunes unpromising avenues.
- It focuses computational effort on the most likely paths. ToT demonstrates how structured internal deliberation (planning/reasoning actions) can dramatically improve problem-solving robustness over simple chain-of-thought.
Generative Agents: Social Simulation
The Generative Agents work created simulated individuals with complex social lives, heavily relying on CoALA principles:
- Memory: Rich episodic memory (tracking interactions), semantic memory (summarized reflections), procedural rules (social behaviors).
- Decision Process: Retrieval based on context, reasoning about social norms/goals, planning daily activities, executing actions in the simulation. This shows CoALA’s applicability to modeling complex, long-term, socially-grounded behavior.
These examples illustrate that the components CoALA formalizes – structured memory, distinct internal/external actions, a deliberate decision cycle – are proving crucial for building more capable agents across diverse domains.
5. Implementing CoALA: A Practical Example
Let’s strip CoALA down to a bare-bones Python sketch to make the concepts tangible. This is a toy model, not production code, highlighting the core loop and components.
import random
from typing import List, Dict, Any
# Mock LLM call (replace with real LLM in practice)
def mock_llm(prompt: str) -> str:
"""Simulate LLM responses for demonstration purposes.
In a real implementation, this would call an actual language model API."""
# Crude simulation of LLM behavior based on prompt keywords
if "RETRIEVE" in prompt and "chess" in prompt:
return "Relevant memory: Solved chess puzzle involving queen sacrifice."
elif "RETRIEVE" in prompt:
return "Relevant memory: None found for this topic."
if "THOUGHT" in prompt:
# Simulate suggesting an action based on observation
observation_detail = prompt.split(":")[-1].strip()
if "puzzle" in observation_detail:
return "Next best action: analyze_puzzle"
else:
return "Next best action: observe_environment"
if "LEARN" in prompt:
experience_detail = prompt.split(":")[-1].strip()
return f"Stored new memory: Experience related to '{experience_detail[:30]}...'."
return "Default LLM output: Unsure how to proceed."
# CoALA-like memory structures (simplified)
working_memory: Dict[str, Any] = {
"observation": None,
"retrieved_context": [], # Store retrieved memories here
"current_plan": None, # Store reasoning output / next action
}
episodic_memory: List[str] = ["Initial memory: Agent started."] # Store summaries
semantic_memory: Dict[str, str] = {"chess": "Game of strategy with pieces like King, Queen, Knight."} # Simple key-value facts
def retrieve_from_memory(query: str) -> str:
"""Simplified retrieval: Check semantic then episodic. Needs real search for scale."""
# Basic keyword matching for demo
relevant_semantic = [v for k, v in semantic_memory.items() if k in query]
relevant_episodic = [mem for mem in episodic_memory if query.split()[-1] in mem] # Crude check
# Combine relevant memories (in real system, use LLM or better logic)
combined_context = ". ".join(relevant_semantic + relevant_episodic)
if not combined_context:
combined_context = "No specific relevant memories found."
# Optionally use LLM to summarize or select best memory
# prompt = f"RETRIEVE: Based on query '{query}', what's most relevant from: {combined_context}"
# retrieved = mock_llm(prompt) # Using LLM for retrieval step itself
# return retrieved
return combined_context # Returning combined raw context for simplicity here
def reason_about_state(observation: str, context: str) -> str:
"""Generate reasoning (plan/next action) based on current state and context."""
prompt = f"CONTEXT: {context}\nOBSERVATION: {observation}\nTHOUGHT: What is the next logical action?"
reasoning_output = mock_llm(prompt) # LLM generates the plan/action
return reasoning_output
def learn_something(experience: str) -> None:
"""Update memory based on new experiences. Needs sophisticated logic in reality."""
# Use LLM to summarize the experience for episodic memory
prompt = f"LEARN: Summarize this experience concisely: {experience}"
summary = mock_llm(prompt)
if "Stored new memory" in summary: # Basic check if LLM produced a summary
episodic_memory.append(summary)
print(f" Learned: {summary}")
else:
print(" Learning step did not produce a storable summary.")
def external_action(action_name: str) -> str:
"""Execute an action in the external environment. Returns outcome."""
print(f"[Agent External Action] Executing: {action_name}")
# Simulate action outcome
if "analyze_puzzle" in action_name:
return "Outcome: Puzzle solved successfully."
else:
return "Outcome: Environment observed, no significant changes."
### Main decision loop
def main_cognitive_cycle(steps: int = 3) -> None:
"""Execute the main CoALA cognitive cycle for a specified number of steps."""
# Initial observation
working_memory["observation"] = "Environment state: Idle, chess puzzle available."
for step in range(steps):
print(f"\n--- Step {step+1} ---")
current_observation = working_memory["observation"]
print(f" Observation: {current_observation}")
# 1. Retrieve relevant knowledge from memory
retrieved_context = retrieve_from_memory(current_observation)
working_memory["retrieved_context"] = retrieved_context
print(f" Memory Retrieval: {retrieved_context}")
# 2. Reason about observations and memory (Planning Phase)
next_action = reason_about_state(current_observation, retrieved_context)
working_memory["current_plan"] = next_action # This is the selected action
print(f" Reasoning/Planning Output (Selected Action): {next_action}")
# 3. Execute the selected action (Execution Phase)
action_outcome = external_action(next_action)
print(f" Action Outcome: {action_outcome}")
# 4. Learn from this experience (Execution Phase - internal learning action)
experience = f"Observed '{current_observation}', Retrieved '{retrieved_context}', Did '{next_action}', Outcome '{action_outcome}'"
learn_something(experience)
# 5. Update observation for next cycle (Simulates environment feedback)
working_memory["observation"] = f"Environment state after action: {action_outcome}"
# Execute the cognitive cycle
if __name__ == "__main__":
main_cognitive_cycle(3)
print(f"\nFinal Episodic Memory: {episodic_memory}")Building this out for real? You’d need serious engineering:
- Real Memory: Swap lists/dicts for vector databases (Pinecone, Chroma, etc.) with robust indexing and retrieval (semantic search, filtering). Implement summarization, relevance scoring, and maybe forgetting mechanisms.
- Smarter Planning: Move beyond single-step reasoning. Implement techniques like ToT, Monte Carlo Tree Search, or allow the LLM to generate multi-step plans that are then executed sequentially. Handle plan failures and replanning.
- Prompt Engineering & LLM Guardrails: Design prompts meticulously to feed context effectively and elicit structured outputs (e.g., JSON). Validate LLM outputs rigorously – don’t trust, verify. Handle hallucinations and refusal modes.
- Actual Learning: Develop sophisticated methods for when and what to learn. How to update procedural skills safely? How to verify generalized knowledge before adding it to semantic memory? This is where things get tricky (and potentially dangerous if done poorly).
This simple sketch shows the flow, but the gap between this and a production system capable of complex, reliable, long-term operation is substantial. CoALA provides the map, but the territory requires careful navigation.
6. The Significance of CoALA and Future Directions
CoALA is more than just another framework paper; it represents a necessary step towards maturity in language agent design. Its real significance lies in:
Current Impact
Bringing Structure to Chaos: In a field often driven by scaling laws and empirical hacks, CoALA offers a principled architecture. It gives developers a way to think systematically about agent components and their interactions, moving beyond ad-hoc prompt engineering.
Modularity: Separating memory, action, and decision loops makes agents easier to design, debug, test, and improve incrementally. You can swap out a memory retrieval strategy without rewriting the whole agent.
Bridging Eras: It explicitly connects the insights of cognitive science and symbolic AI (memory types, decision cycles) with the power of modern LLMs, leveraging the strengths of both.
Unlocking Capabilities: Systems inspired by CoALA principles tend to be better at tasks demanding:
- Long-term memory and context retention.
- Complex, multi-step planning and reasoning.
- Adaptation based on experience.
- Learning new skills or knowledge over time.
A Path Towards Safety: The explicit distinction between internal deliberation (planning) and external action provides natural control points. Safety checks, human oversight, or ethical reasoning modules can be inserted before an agent affects the real world.
Open Research Challenges
CoALA also throws hard problems into sharp relief:
Memory Scalability & Relevance:
- How do you prevent memory systems from becoming swamped with irrelevant details?
- What are the best strategies for compressing, summarizing, and retrieving knowledge efficiently and accurately at scale?
- When and how should an agent forget or archive information?
Safe Learning:
- How can agents learn new procedures (code, skills) without introducing bugs or harmful behaviors?
- How do you verify learned knowledge or skills before deploying them?
- Resolving conflicts between learned behaviors and original programming remains a major hurdle.
Meta-Cognition:
- How does an agent decide how much to think before acting? (The deliberation vs. reaction trade-off).
- How does it know when its current plan is failing and needs revision?
- How can agents reliably monitor their own performance and limitations?
Multimodality:
- How do you coherently integrate information from text, vision, audio, etc., into these cognitive structures?
- What do memory and reasoning look like when dealing with non-linguistic data?
Future Directions
Building on the CoALA foundation, promising avenues include:
Hierarchical Architectures: Nested CoALA loops, where high-level strategic agents guide lower-level tactical agents.
Multi-Agent Systems: Extending CoALA principles to teams of collaborating agents sharing memory and coordinating actions.
Deep Personalization: Memory systems tailored to individual users, tracking preferences, history, and context for truly personalized assistants.
Explainability: Using the structured components of CoALA to generate more transparent explanations for agent decisions.
Knowledge Transfer: Developing mechanisms for agents to generalize knowledge and skills learned in one domain for use in others, leveraging structured memory.
7. Conclusion: Toward More Capable and Responsible AI Systems
The Cognitive Architectures for Language Agents (CoALA) framework isn’t a magic bullet, but it’s a vital contribution. It pushes back against the notion that larger models alone will solve all problems, reminding us that structure matters. By weaving together insights from cognitive science with the generative power of LLMs, CoALA provides both a theoretical grounding and a practical toolkit for building agents that are more than just clever parrots.
As we stumble towards AI systems that can genuinely assist us with complex, long-running tasks, the challenges highlighted by CoALA – memory, planning, learning, grounding – become paramount. Frameworks like this offer a way to tackle these challenges systematically.
For researchers, CoALA clarifies the lineage of current work and points to critical open questions. For engineers, it provides design patterns for building less brittle, more understandable systems. For everyone navigating the AI hype cycle, it suggests that true progress may lie not just in bigger models, but in smarter architectures – ones that combine the fluency of LLMs with the deliberate, structured reasoning that defined earlier eras of AI.
The road ahead is long, and building truly capable and reliable agents remains a formidable challenge. But imposing cognitive structure, as CoALA advocates, seems like a necessary, if not sufficient, step in the right direction. It’s about building machines that don’t just react, but perhaps begin to genuinely think.
Now, go build something interesting – and maybe give it a decent memory.