Key Takeaways
- Novelty is in the eye of the LLM – In a controlled experiment, a research ideation agent produced project ideas that 100+ NLP researchers rated as statistically more novel than their own. A victory for combinatorial creativity, perhaps.
- A predictable trade-off – The machine’s ‘novelty’ comes at the cost of practicality. Reviewers found the AI’s ideas less feasible, revealing the chasm between interesting and possible.
- The illusion of objectivity – Human experts barely agree on what makes a “good” idea. A ~56% inter-reviewer agreement suggests we’re measuring subjective taste more than objective quality.
- LLM-as-a-judge remains a fiction – Predictably, using an LLM to evaluate its own kind of output fails, barely matching the coin-flip agreement rate of human reviewers. Human supervision remains non-negotiable.
- Commendable transparency – The authors made the full ideation agent, data, and prompts publicly available, a nod to reproducibility that is, for now, all too rare.
1. Why This Paper Matters
The narrative that large language models can generate code, poetry, and passable prose is now firmly established. But scientific ideation-the initial, nebulous spark of inquiry-was presumed to be a uniquely human domain. Si et al. challenge this assumption with a rigorous head-to-head experiment, one with enough statistical power (≈ 300 blinded reviews) to move beyond anecdote.
Their headline finding-that LLM-generated ideas scored higher on perceived novelty-is provocative. But the paper’s lasting contribution may be less about the splashy result and more about establishing a reusable evaluation blueprint. It provides a structured methodology against which future, more ambitious claims of an “AI Scientist” can be measured.
2. Experimental Design at a Glance
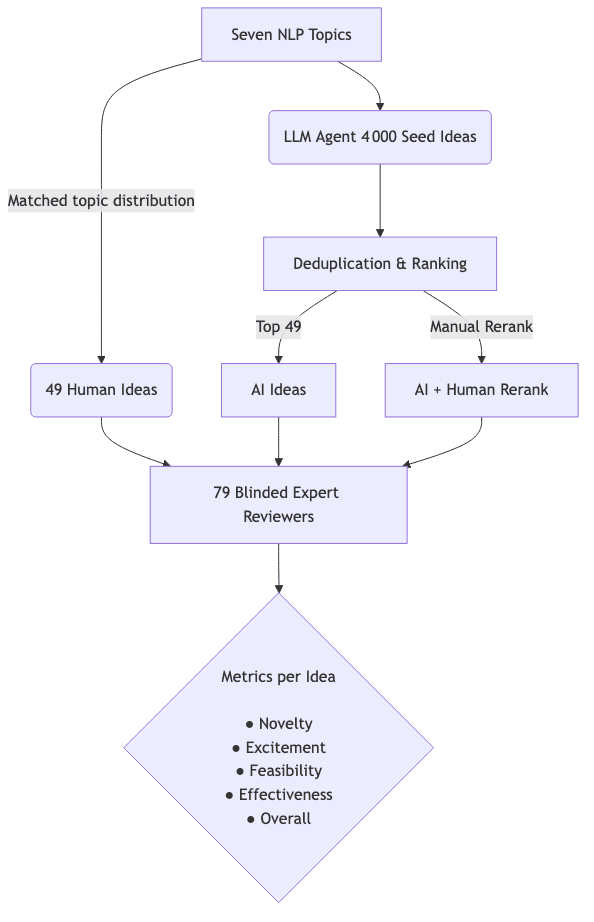
The design attempts to neutralize common confounders through a few key mechanisms:
- Topic Balancing – Each human-submitted idea is methodically paired with an AI-generated idea on the identical sub-topic (bias, coding, safety, etc.).
- Stylistic Anonymization – A secondary LLM is used to rewrite all ideas into a uniform template, a brute-force attempt to blind reviewers to the source.
- Multi-faceted Analysis – The authors deploy three different statistical tests alongside a mixed-effects model. Unsurprisingly, they all concur.
The core of their statistical claim rests on a familiar tool, the Welch t-test, applied with a Bonferroni correction:
where and
represent the mean and variance of the novelty scores. It’s a standard approach, but one that risks lending a veneer of mathematical certainty to what is, at its heart, a deeply subjective measurement.
3. Inside the Ideation Agent
The open-source pipeline is a study in mechanistic brute force:
- RAG Grounding – Relevant papers are pulled via Semantic Scholar and fed into the prompt as context.
- Mass Generation – With the temperature cranked up, Claude 3.5 Sonnet generates 4,000 “seed ideas” for each topic. This is less about ideation and more about carpet-bombing the possibility space.
- Semantic Deduplication – Sentence-transformer embeddings are used to prune near-duplicates, defined as having > 0.8 cosine similarity.
- Pairwise Ranking – A Swiss-system tournament produces a quality score for each surviving proposal, sorting the signal from the noise.
A reality check: The process started with 4,000 generated ideas, but only ~200 distinct concepts survived deduplication. This is some evidence of a possible diversity ceiling. But it’s mainly a confirmation that at this scale, the model is mostly producing redundant, low-entropy variations on a theme. (Although ~200 is better than nothing.)
4. Results in Four Numbers
| Metric | Human | AI | Δ AI–Human |
|---|---|---|---|
| Novelty (1‑10) | 4.84 ± 1.79 | 5.64 ± 1.76 | +0.80* |
| Excitement | 4.55 | 5.19 | +0.64* |
| Feasibility | 6.61 | 6.34 | –0.27 |
| Overall | 4.68 | 4.85 | +0.17 (n.s.) |
* Significant at p < 0.05; data aggregated at the review level.
The take-home: The numbers tell a familiar story. LLMs can generate superficially exciting proposals that impress on novelty, but they begin to lag when subjected to the hard constraints of real-world feasibility.
5. Limitations & Open Questions
The study’s constraints are not minor footnotes; they are fundamental challenges to its conclusions.
- A Questionable Baseline – The human-submitted ideas were self-rated by participants at the 43rd percentile of their personal idea quality. The LLM wasn’t competing against experts at their best; it was competing against their average, perhaps even uninspired, thoughts. Would it still win against their best work? Unlikely.
- An Incestuous Domain – All topics were confined to the NLP-prompting ecosystem, a domain the LLM is more than familiar with. It’s unclear if these results would transfer to fields with less linguistic ambiguity, like computer vision or, more critically, wet-lab biology.
- The Subjectivity Trap – Even the experts struggled to agree. With agreement barely above chance, what is “novelty” really measuring? It seems less like an objective criterion and more like a proxy for “unfamiliar combination of familiar terms.”
- Novelty vs. Impact – The most crucial question remains unanswered. Does this machine-generated novelty translate into actual scientific progress, or is it just intellectual churn? Phase II of the project aims to execute these ideas, which will be the only test that truly matters.
6. Reproducing / Extending the Study
For those inclined to stress-test the findings, the public agent can be spun up with minimal overhead:
# clone the repo
!git clone https://github.com/NoviScl/AI-Researcher.git
from agent.generate import IdeationAgent
agent = IdeationAgent(
model="claude-3.5-sonnet",
topic="Prompting methods to reduce LLM hallucination"
)
ideas = agent.generate(num_seeds=100)
ranked = agent.rank(ideas, rounds=3)
print(ranked[:3]) # top 3 proposalsOne could swap in a different model, like GPT-4o or Llama-3-70B-Instruct, to see if idea diversity and quality shift, though the fundamental limitations would likely persist.
7. My Verdict
The LLM as a Generator of Interesting Noise.
Si et al. provide the clearest evidence to date that an LLM can outperform domain experts in generating ideas rated as novel. Yet, the study also reveals the vacuity of that term. The LLM isn’t “innovating” in a human sense; it’s performing a massive combinatorial search, identifying statistically plausible but less-trodden paths in a well-defined conceptual space. Humans perceive this as novelty because it’s different from our own, more constrained cognitive search patterns.
The critical disconnect is the feasibility gap. It’s a symptom of a deeper lack of grounded understanding. The model doesn’t know why an idea might be good, only that its components have appeared together in its training data.
In short, LLMs are becoming powerful brainstorming partners, capable of injecting unexpected mutations into a stale intellectual gene pool. But they are not yet ready to run the lab. The “AI scientist” remains, for now, a capable but ungrounded intern: excellent at brainstorming, but one you wouldn’t trust with the keys.