Key Takeaways
- BoT transforms ephemeral “chain-of-thought” traces into a durable knowledge base of high-level thought-templates, stored in a central meta-buffer.
- A lightweight Problem Distiller first strips a new query down to its canonical essence, eliminating noise before reasoning begins.
- Template retrieval is a single, efficient embedding search, not a costly tree or graph exploration. This slashes inference cost to ~12% of multi-query methods like Tree-of-Thoughts.
- An intelligent Buffer Manager incrementally distills and admits only novel reasoning patterns, allowing the system to learn and compound its intelligence over time.
- Across ten reasoning-intensive benchmarks, BoT outclasses prior state-of-the-art methods by up to 51% and allows an 8B parameter model to eclipse its 70B sibling.
- The Long View: BoT is a pragmatic architectural win today. But viewed through the lens of Sutton’s Bitter Lesson, it’s also a compelling prototype for a future where models learn to cache and retrieve their own thought-patterns, internalizing the scaffold.
Introduction
The landscape of large language model prompting is a frantic churn of techniques-chain-of-thought, least-to-most, tree-of-thoughts. Each offers a marginal gain, a clever way to coax better reasoning from the model. But they all share a fundamental flaw: they suffer from amnesia. Every new problem is a cold start. The brilliant reasoning path forged for one task evaporates, leaving no trace, no muscle memory for the next. It’s an architecture of endless, wasteful reinvention.
When I came across “Buffer of Thoughts (BoT)” by Yang et al., it felt less like another clever hack and more like a necessary architectural evolution. The core insight is devastatingly simple: stop throwing away the reasoning. Instead of just solving the problem, capture the pattern of the solution. Cache the strategy, not the answer.
This resonates with a deeper principle in AI, most famously articulated in Rich Sutton’s The Bitter Lesson: the most profound gains come not from intricate human-designed heuristics, but from creating frameworks that allow learning and search to dominate. BoT walks this line perfectly. It introduces an external scaffold that works today, but it also provides a tantalizing glimpse of a tomorrow where that scaffold might dissolve, becoming an intrinsic capability of the model itself.
Here, I’ll unpack the BoT framework, using code from the official GitHub repo to ground the concepts, and explore why its true significance might be as a prototype for the self-organizing minds of the future.
The Amnesia of Modern Prompting
| Approach | Strengths | Pain Points |
|---|---|---|
| Single-query (CoT, few-shot) | Fast, cheap | Brittle; demands manual, bespoke exemplars for each domain. |
| Multi-query (ToT, GoT) | Higher accuracy | Explodes in latency & token cost; computationally ruinous. |
| Meta-prompting | Task-agnostic | Wastes vast context windows on boilerplate scaffolding. |
None of these methods build institutional knowledge. They learn nothing from yesterday’s successes. BoT is designed to fix this.
The Buffer of Thoughts Framework
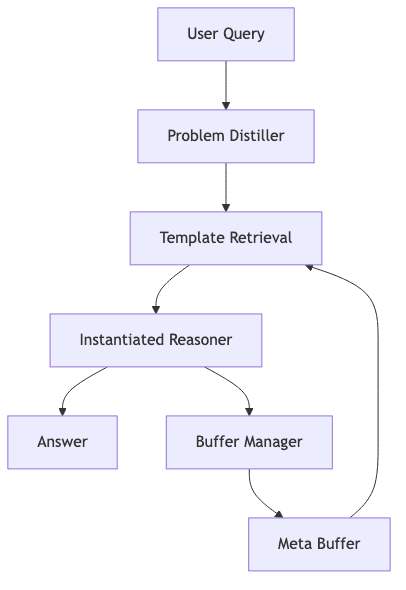
1. Problem Distiller
Before any complex reasoning, a compact meta-prompt forces a preliminary LLM call to act as a ruthless summarizer. It extracts:
- Key variables
- Constraints and objectives
- A canonical task description
This is about noise reduction. But also about translating a messy, natural-language query into a clean, canonical representation. This standardization is crucial for making the subsequent retrieval step both fast and reliable.
2. Meta-Buffer & Thought-Templates
The meta-buffer is the system’s long-term memory. It doesn’t store facts; it stores strategies. These strategies are encoded as thought-templates-high-level, domain-agnostic plans. Think of them as the pseudocode of cognition.
The paper organizes these templates into six families, covering the core competencies of modern LLMs:
- Text comprehension
- Creative language generation
- Common-sense reasoning
- Mathematical reasoning
- Code programming
- Application scheduling
The underlying data structure, shown in meta_buffer.py, is elegantly simple:
@dataclass
class ThoughtTemplate:
uid: str
category: str
description: str # natural-language steps
skeleton: str # code or prompt stubThis is the “DNA” of a reusable reasoning pattern.
3. Template Retrieval & Instantiation
This is where BoT’s efficiency shines. Instead of a sprawling, multi-step search, retrieval is a single vector database query.
emb_task = encoder(x_distilled)
t_id = meta_buffer.nearest(emb_task, thresh=0.6)
plan = instantiate(meta_buffer[t_id], x_distilled)
answer = llm.run(plan)The system finds the most relevant thought-template and then “hydrates” it with the specific variables from the distilled problem. Depending on the template’s category, this instantiated plan takes one of three forms:
- Prompt-based: A lightweight structure, ideal for straightforward Q&A.
- Procedure-based: A narrative or list-style plan for creative and multi-step tasks.
- Programming-based: A code skeleton for logic, math, and puzzles, offloading execution to an interpreter.
4. Buffer Manager
After a new problem is solved, BoT doesn’t just blindly add the new reasoning trace to the buffer. It acts as an intellectual curator. The full trace is compressed into a candidate template, and it’s only admitted if it’s sufficiently novel, governed by a similarity threshold δ:
This prevents the buffer from bloating with redundant strategies. It’s an immune system against cognitive clutter, ensuring the library remains compact and potent.
How Well Does It Work?
The results represent a step-change in efficiency and accuracy.
| Task | GPT-4 | CoT | Meta Prompting | BoT |
|---|---|---|---|---|
| Game of 24 | 3.0 | 11.0 | 67.0 | 82.4 |
| Geometric Shapes | 52.6 | 69.2 | 78.2 | 93.6 |
| Checkmate-in-One | 36.4 | 32.8 | 57.2 | 86.4 |
BoT achieves these scores while maintaining brutal efficiency. It issues just two LLM calls per query (distill → reason), a token cost reduction of nearly 90% compared to the expensive search paths of methods like Tree-of-Thoughts.
Hands-On Example
The following snippet, adapted from the official implementation, demonstrates the framework’s power. It tasks a Llama-3 8B model with a Game of 24 puzzle-a task that typically challenges much larger models.
from bot_pipeline import solve
numbers = [3, 3, 8, 8] # target = 24
print(solve(numbers))The model correctly solves it:
(8 / (3 - (8 / 3))) = 24The elegance lies not in brute-force reasoning, but in targeted retrieval. The solve() function internally identifies the query as mathematical, fetches the corresponding programming-based template, injects the numbers [3, 3, 8, 8], and hands the completed Python script to the model for execution. It retrieves a known strategy instead of rediscovering it from scratch.
Why the Gains?
- Reusability > Memorization: BoT internalizes strategy, not just facts. This is a far more generalizable form of knowledge.
- Architectural Efficiency: It replaces an exponential search problem with a constant-time lookup. This is a clean, decisive win.
- Continual Learning: The system grows stronger and more comprehensive with use, echoing the homeostatic, adaptive nature of biological learning.
- Alignment with the Bitter Lesson: The external buffer is a scaffold. It perfectly mirrors the kind of self-organizing cognitive cache we hope will one day emerge inside the model weights themselves.
Limitations & Future Work
- Unstructured Creativity: Truly novel tasks like writing a joke or a story benefit less. You can’t template genuine surprise.
- Teacher Dependence: The quality of the distilled templates is bounded by the intelligence of the base model used for distillation. Garbage in, mediocre templates out.
- Retrieval Sophistication: The current implementation uses vanilla cosine similarity. Exploring more structured, graph-based, or even differentiable buffers is a clear path for future gains.
- The Self-Caching Frontier: The ultimate goal is to make the scaffold redundant. The long-term vision is to use techniques like reinforcement learning to reward the LLM for building and reusing its own latent reasoning fragments, baking the buffer directly into the model’s architecture.
Conclusion
Buffer of Thoughts feels like a missing abstraction layer in the architecture of LLM reasoning. It addresses the glaring, almost embarrassing, inefficiency of solving the same type of problem again and again from a blank slate.
Yet, its greatest contribution may be philosophical. In accordance with the Bitter Lesson, the ultimate solution isn’t a more elaborate external scaffold, but a model that learns to build its own. BoT, therefore, is both a powerful, pragmatic tool for today and a compelling blueprint for the self-organizing, computationally efficient intelligences of tomorrow. It’s a glimpse into how a machine might learn to think, remember its thoughts, and get smarter every time it does.