Key Takeaways
- Agent S2 splits the problem. A generalist LLM plays strategist, while a squad of specialist models handles the grunt work of perceiving and clicking. This is composition over brute force.
- It nails the last mile with a “Mixture-of-Grounding”. It uses a Visual, Textual, and Structural expert to translate fuzzy language into hard
(x, y)coordinates, fixing the “lost cursor” problem that plagues screenshot-only agents. - The plan is a living thing. The agent continuously replans after each sub-goal is met, rather than waiting for something to break. This anticipates change instead of just reacting to it.
- The numbers are hard to ignore. It pushes the state-of-the-art on three public benchmarks (OSWorld, WindowsAgentArena, AndroidWorld) by up to 53%.
- It’s open source. You can grab the code from GitHub and run it on your own hardware, right now.
Why GUI Agents Matter
Most real work doesn’t happen in neat, well-documented APIs. It happens in the messy, unpredictable expanse of a graphical user interface (GUI)-the spreadsheets, the design tools, the IDEs, the web browsers. APIs are a convenient fiction; the pixels are the ground truth. Autonomously controlling that ground truth is the last mile for any AI promising to augment human productivity. I’ve spent the past few months in the trenches with the new wave of computer-use agents. The early monolithic approaches, like CogAgent or UI-TARS, looked impressive in canned demos but reliably fell apart on a real, cluttered desktop.
Agent S2 takes a different, decisively modular path. And in my experience, that architectural choice makes all the difference.
Monoliths vs. Modularity
The conventional approach to this problem has been, to put it mildly, a category error. The baseline architecture looks like this:
- A single, monolithic model (usually GPT-4-o or its equivalent) is fed a screenshot and a scrollback of text history.
- It is then expected to decide both what to do strategically and where, precisely, to move the cursor and click.
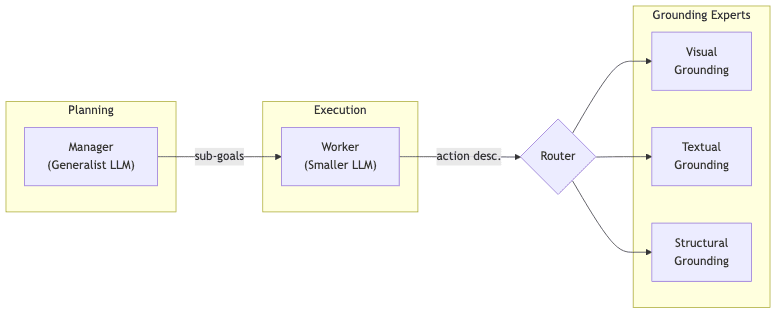
The trade-off here is stark and, frankly, naive. You’re asking a model to be a brilliant strategist and a pixel-sniping vision system in the same breath-two profoundly different cognitive skills. It’s like asking a CEO to also be a master watchmaker. Agent S2 decomposes the problem into a sane division of labor:
- Manager M (a large, general-purpose multimodal LLM) acts as the strategist, breaking the high-level goal into a sequence of concrete sub-goals.
- Worker W (a lighter, faster LLM) takes each sub-goal and emits low-level actions, including a natural-language pointer like “click the Send button in the Thunderbird toolbar”.
- Grounding Experts (a team of specialists) take that pointer and translate it into the only thing the computer actually understands:
(x, y)coordinates.
Formalising the Task
Under the hood, Agent S2 still frames the problem as a Partially Observable Markov Decision Process (POMDP). Nothing revolutionary there. The key difference is that the observation
is just a PNG and a text history. There is no fragile dependency on platform-specific accessibility trees or DOM inspection. It sees what you see.
Architecture at a Glance
Mixture-of-Grounding
This is where the system’s elegance becomes apparent. A team of experts, each with a specific perceptual talent, is managed by a lightweight router. The Visual expert uses a fine-tuned vision-language model to spot generic icons and buttons. The Textual expert uses OCR to find and highlight exact character spans. The Structural expert can even manipulate spreadsheet cells programmatically via a UNO bridge.
The Worker effectively acts as a gating network, selecting the right tool for the job at each step. If it asks the Visual expert to find a button and gets ambiguous feedback, it can instantly pivot and ask the Textual expert to find the button’s label instead.
# Simplified Python pseudo‑code
def route_action(action_desc: str):
"""Delegate grounding to the right expert."""
if any(k in action_desc.lower() for k in ("cell", "column", "row")):
return structural_expert(action_desc)
if "paragraph" in action_desc or "word" in action_desc:
return textual_expert(action_desc)
return visual_expert(action_desc)Proactive Hierarchical Planning
Most reactive agents only replan after a spectacular failure. Agent S2 replans after every successful sub-goal. It’s about maintaining a fresh, accurate model of the world. A pop-up appears, a theme changes, a modal dialog demands attention-the agent sees it and adapts the next step accordingly. This is the difference between a pilot who constantly checks their instruments and one who waits for the stall alarm to blare. In practice, I found the agent often improvises, adding small safety clicks or corrective scrolls that a rigid, static plan would have missed entirely.
Benchmark Results
Benchmarks are often just games, but a win is a win, and these numbers are hard to ignore.
| Benchmark | Metric | Previous Best | Agent S2 | Relative Gain |
|---|---|---|---|---|
| OSWorld (15-step) | Success % | OpenAI CUA 19.7 | 27.0 | +37% |
| OSWorld (50-step) | Success % | OpenAI CUA 32.6 | 34.5 | +6% |
| WindowsAgentArena | Success % | NAVI 19.5 | 29.8 | +53% |
| AndroidWorld | Success % | UI-TARS 46.6 | 54.3 | +16% |
The most significant gains are on Windows, where accessibility metadata is notoriously sparse. This is a direct testament to the robustness of the screenshot-only design.
Inside the Action Space
Agent S2 exposes a clean, function-calling API. It’s a legible grammar that allows the worker model to reason explicitly about the semantics of an interface instead of just guessing pixel coordinates.
| Action | Typical Arguments |
|---|---|
click |
locator, clicks, button, modifiers |
type |
locator, text, overwrite, submit |
scroll |
locator, ticks, shift |
set_cell_values |
dict of {cell: value}, sheet name |
highlight_span |
start_phrase, end_phrase |
done / fail |
– |
This structure simplifies prompting and, more importantly, makes the agent’s behavior auditable and debuggable.
Strengths, Limitations & Roadmap
| 👍 What I love | ⚠️ Where I see gaps |
|---|---|
| Screenshot-only input is robust; it kills fragile tree scraping. | Still leans heavily on large proprietary LLMs (Claude 3.x) for the top-level planning. |
| The modular design lets you swap in tiny open models (UI-TARS-7B) for the worker without much score loss. | Grounding experts can still be fooled by latent UI elements, like tooltips that only appear on hover. |
| Proactive planning handles the chaos of real GUIs (pop-ups, lag) with grace. | Lacks a built-in privacy boundary. Sending raw screenshots to a third-party API is a non-starter for many. |
| The team provides extensive open benchmarks and ablation studies. | Native macOS support is missing at the time of writing. |
The team is hinting at agentic memory and hot-swappable skill libraries as the next major milestones. Both would represent significant steps toward closing the gap between human and machine performance on these tasks.
Getting Started in 30 Seconds
Enough theory. Here’s how you run it.
# install prerequisites
pip install agent-s2[cpu] # GPU optional but recommended
# launch an Ubuntu VM and start the agent
agent-s2 demo --model=claude-3.7-sonnet --steps=50For the full details, see the official documentation.
Final Thoughts
Agent S2 is a powerful demonstration that composition beats brute-force scaling for complex, embodied tasks like desktop automation. By embracing a hierarchy of specialized talents-much like any well-run human team-the framework provides a clear blueprint for building agents that are not only capable but also reliable and interpretable.
I’m already integrating Agent S2 into my own workflows to automate things like batch image editing and reconciling spreadsheets. If you care about building AI that can controllably and reliably operate real-world software, this is a project you need to take a serious look at.