Key Takeaways
- Quantizing both weights and activations to 8-bit (W8A8) is the real game-changer. For a 7B-parameter model, weights drop from ≈14 GB (FP16) to ≈7 GB (INT8). Halving activation memory further slashes the runtime footprint, crushing a peak of ≈28 GB in FP16 down to ≈14 GB in W8A8, often with no meaningful loss in quality.
- Stop reinventing the wheel.
llm-compressorautomates the entire flow (SmoothQuant + GPTQ for INT8, or an FP8 path) and produces models ready forvLLM. - Don’t be lazy with calibration. It matters far more for activations than for weights. A small, domain-specific sample (≈512 prompts) beats random text every time.
- Know your hardware. Modern GPUs (Ada, Hopper, Blackwell) eat FP8 for breakfast; older cards (Turing ≥ 7.5) are still INT8 workhorses.
- The prize is more than just kernel speed; it’s throughput. A smaller memory footprint lets
vLLMpack more requests, delivering real-world ~1.3-× speed-ups.
Why Go Beyond Weight Quantisation?
Weight-only quantization is a good start, but it only solves half the problem. It slashes the static memory footprint, the space your model occupies at rest. But the moment you start feeding it long sequences or big batches, the runtime activation memory balloons, and your VRAM budget evaporates. This is the hidden bottleneck.
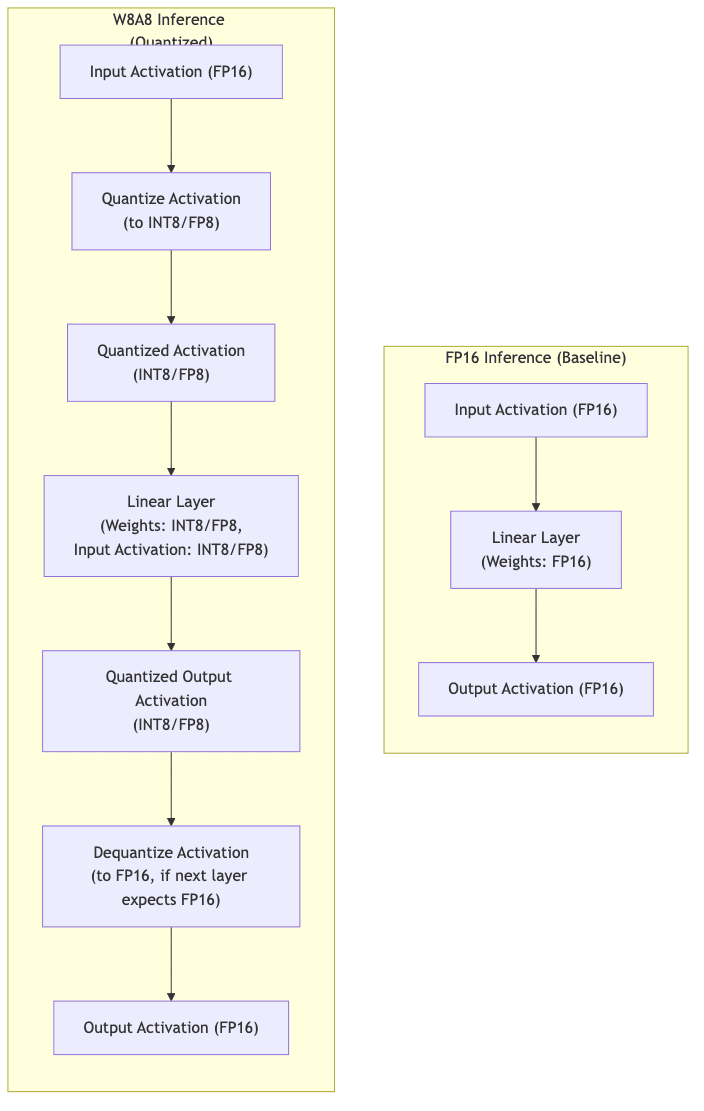
For a decoder-only model, the peak activation memory is proportional to
where
= sequence length,
= hidden size (or sum of relevant dimensions like model dimension, feed-forward dimension),
= bytes per scalar (e.g., 2 for FP16, 1 for INT8/FP8).
Quantizing activations therefore halves (FP16→INT8) or quarters (FP16→FP8, if applicable) that dominant term, unlocking larger batches, longer contexts, or smaller GPUs.
Hardware Checklist
| Architecture | Compute capability | INT8 tensor-cores | FP8 support |
|---|---|---|---|
| Turing (RTX 20/Quadro) | ≥ 7.5 | ✅ | ❌ |
| Ampere (A10/A40/A100) | 8.x | ✅ | ❌ |
| Ada Lovelace (L4/RTX 40) | 8.9 | ✅ | ✅ |
| Hopper (H100) | 9.0 | ✅ | ✅ |
| Blackwell (B100) | 9.2 (expected) | ✅ | ✅ |
Not sure what you’re running? A quick check in Python will tell you:
import torch
if torch.cuda.is_available():
print(torch.cuda.get_device_capability(0)) # returns (major, minor)
else:
print("CUDA not available.")The W8A8 INT8 Workflow
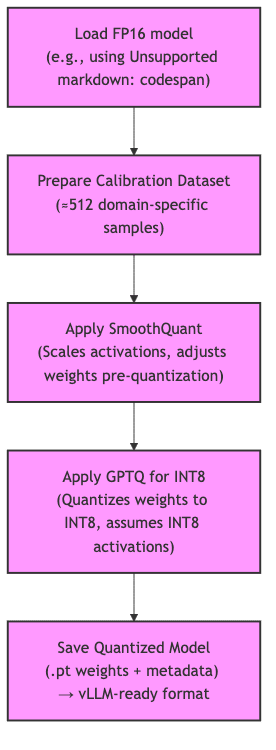
This is the battle-tested playbook for INT8. We use SmoothQuant to ‘massage’ the activation distributions-a clever trick to make them play nice with 8-bit precision-and then apply GPTQ to quantize the weights in a way that’s aware of these newly quantized activations. It’s a two-step dance that works.
1. Installation
First, assemble your toolkit. llmcompressor from NeuralMagic is the star of the show here.
pip install --upgrade transformers llmcompressor datasets vllm>=0.8.0 \
lm-eval langdetect immutabledict torch accelerate2. Load the Base Model
Nothing fancy. Just load your starting FP16 model into memory.
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
MODEL_ID = "Qwen/Qwen2.5-7B-Instruct" # Example model
tokenizer = AutoTokenizer.from_pretrained(MODEL_ID)
model = AutoModelForCausalLM.from_pretrained(
MODEL_ID,
device_map="auto", # Loads model across available GPUs, or CPU if none
torch_dtype=torch.float16 # Explicitly load in FP16
)3. Build a Calibration Dataset
This is where people get lazy, and it shows. A small, high-quality calibration dataset is non-negotiable for good results. Garbage in, garbage out. Use data that mirrors your actual use case, not just random text from the internet.
from datasets import load_dataset
NUM_CALIBRATION_SAMPLES = 512
CALIBRATION_DATASET_ID = "HuggingFaceH4/ultrachat_200k"
CALIBRATION_SPLIT = "train_sft"
# Load and preprocess the dataset
raw_dataset = load_dataset(CALIBRATION_DATASET_ID, split=CALIBRATION_SPLIT)
shuffled_dataset = raw_dataset.shuffle(seed=42)
calibration_dataset_raw = shuffled_dataset.select(range(NUM_CALIBRATION_SAMPLES))
def format_example_for_calibration(example):
# Assuming 'messages' is a list of turns like in ultrachat
# Apply chat template and tokenize
# You might need to adjust this based on your dataset structure
formatted_text = tokenizer.apply_chat_template(
example["messages"],
tokenize=False,
add_generation_prompt=False # Or True, depending on model/task
)
# Tokenize the formatted text
# `max_length` should ideally match `max_seq_length` in `oneshot`
tokenized_input = tokenizer(
formatted_text,
add_special_tokens=False, # Template usually handles this
truncation=True,
max_length=2048 # Example, align with oneshot's max_seq_length
)["input_ids"]
return {"input_ids": tokenized_input}
calibration_dataset = calibration_dataset_raw.map(
format_example_for_calibration,
remove_columns=raw_dataset.column_names
)
# Filter out empty samples if any occurred during processing
calibration_dataset = calibration_dataset.filter(lambda x: len(x['input_ids']) > 0)4. Quantise Weights & Activations
Here’s the core logic. We define a recipe that first applies SmoothQuant, then GPTQ.
from llmcompressor import oneshot
from llmcompressor.modifiers import SmoothQuantModifier, GPTQModifier
# Define the quantization recipe
# SmoothQuant scales activations and weights before quantization
# GPTQ quantizes weights to INT8, considering INT8 activations
quantization_recipe = [
SmoothQuantModifier(smoothing_strength=0.5), # Adjust strength as needed
GPTQModifier(
targets=["Linear"], # Apply to all Linear layers
scheme="W8A8", # Specify 8-bit weights and 8-bit activations
ignore=["lm_head"] # Keep the language model head in higher precision
),
]
# Perform one-shot quantization
oneshot(
model=model,
dataset=calibration_dataset, # Pass the tokenized dataset
recipe=quantization_recipe,
max_seq_length=2048, # Max sequence length for calibration
num_calibration_samples=NUM_CALIBRATION_SAMPLES # Number of samples to use from dataset
)5. Save and Serve
With the model quantized, save it and fire it up with vLLM.
SAVE_DIR = f"{MODEL_ID.split('/')[-1]}-W8A8-Static" # Example save directory
model.save_pretrained(SAVE_DIR, save_compressed=True) # save_compressed might be specific to llmcompressor
tokenizer.save_pretrained(SAVE_DIR)Note on vLLM Compatibility for W8A8 INT8 Evaluation: This space moves fast and breaks things. While vLLM >= 0.8.0 is a good general recommendation, evaluating W8A8 INT8 models (like those from this SmoothQuant+GPTQ recipe) with tools like lm_eval sometimes requires an older version, such as vLLM 0.7.0, for full compatibility at the time of writing. For general inference serving (like the command below), newer versions might work, but this is a field report, not gospel. Always test your exact stack.
Launch the quantized model with vLLM:
python -m vllm.entrypoints.openai.api_server \
--model ./path/to/your/saved_model_directory # Update with your SAVE_DIR
# Add other vLLM options as needed, e.g., --tensor-parallel-sizeThe FP8 Shortcut (Ada Lovelace, Hopper, Blackwell GPUs)
If you’re running on modern silicon (Ada, Hopper, Blackwell), you get to take a shortcut. FP8 support is native, and the process is simpler, often sidestepping the need for a calibration dataset entirely. This is the easy button, if you have the hardware for it.
from llmcompressor import oneshot
from llmcompressor.modifiers import QuantizationModifier
# Assuming 'model' and 'tokenizer' are already loaded (e.g., FP16 model)
# Define the FP8 quantization recipe
fp8_recipe = QuantizationModifier(
targets=["Linear"], # Apply to Linear layers
scheme="FP8_DYNAMIC", # Use dynamic FP8 quantization
ignore=["lm_head"] # Keep LM head in FP16
)
# Perform one-shot quantization (no calibration dataset needed for dynamic)
oneshot(
model=model,
recipe=fp8_recipe
# `dataset` argument is typically not required for dynamic quantization schemes
)
FP8_SAVE_DIR = f"{MODEL_ID.split('/')[-1]}-FP8-Dynamic"
model.save_pretrained(FP8_SAVE_DIR) # Again, `save_compressed` behavior might vary
tokenizer.save_pretrained(FP8_SAVE_DIR)Recent versions of vLLM0 (e.g., ≥ 0.8.0) generally support FP8 models out of the box if the format is compatible.
Benchmarks
Benchmarks are always illustrative, never gospel. Your mileage will vary depending on the model, hardware, and workload. But the pattern is consistent.
| Model Variant | Precision | IFEval Acc. ↑ (inst_level_strict_acc) | Throughput (req/s) (Illustrative) | Δ Speed (Illustrative) |
|---|---|---|---|---|
| Baseline | FP16 | 79.1 | 1.0 × (reference) | – |
| W8A8 INT8 | INT8 (W8A8) | 79.6 | 1.3 × | +30 % |
| FP8 Dynamic | FP8 (W8A8) | 78.7 | 1.45 × | +45 % |
IFEval scores based on vLLM1 for Qwen2.5-7B-Instruct, tested on a single NVIDIA L4 (24 GB) with vLLM2 batch auto-tuning. Throughput and speed illustrative.
The accuracy hit is often within the noise margin of the FP16 baseline. You’re not trading quality for efficiency in a meaningful way. The real prize is the throughput gain, which comes directly from the smaller memory footprint allowing vLLM3 to do its job better.
Caveats & Pro Tips
- Don’t be a hero: keep the LM head in FP16. This final layer is tiny but sensitive. Quantizing it is a fool’s errand that saves kilobytes at the cost of accuracy. Just don’t.
- Beware the siren song of mixed precision. Schemes like W4A8 sound great on paper, but the overhead of constantly switching between precisions can kill your performance. Sometimes a clean, simple W8A8 is faster than a complex, lower-bit franken-model.
- Slay the other memory dragon: the KV-cache. For long-context work, the KV-cache will eat your VRAM alive. W8A8 targets weights and activations, but quantizing the KV-cache is the next frontier for serious memory savings.
vLLM4 has options for this; use them. - Trust the empirical results, not the logs.
vLLM5’s memory reporting can sometimes be misleading for quantized models due to packed data formats. If the logs say you’re using more memory than expected but you’re fitting larger batches and seeing higher throughput, trust what you see.
What’s Next?
- The march to lower bits is inevitable. Blackwell is already pushing FP4/FP6. By 2026, these ultra-low precisions won’t just be research toys; they’ll be table stakes for efficient deployment.
- Smarter compilers, not just smaller bits. The other half of the story is the compiler. Tools like Triton, TVM, and Candle are getting frighteningly good at kernel fusion, which will make the overhead of these quantization schemes disappear into the noise.
Conclusion
W8A8 quantization has officially left the lab. It’s no longer a niche research topic but a mandatory, practical tool for any engineer serious about deploying large language models. The combination of clever algorithms like SmoothQuant and powerful tools like vLLM6 and vLLM7 makes it an accessible, high-leverage strategy. Whether you’re trying to cram a 7B model onto a 4090 or max out your A100’s throughput, the path forward is clear: shrink the bits to grow the performance.
Happy compressing!