Key Takeaways
- A Unified Objective: A single ℓ² loss jointly optimizes a drafting policy (π) and a revision policy (π†), collapsing a complex dynamic into a single supervised target.
- Inference-Time Self-Correction: The same model weights, post-deployment, can iteratively refine their own outputs, sharpening performance without further training.
- Out-of-Distribution Tenacity: SRPO maintains its edge on unfamiliar prompts where simpler preference methods degrade, because its optimal state is decoupled from the policy that generated the training data.
- No RL Games: The entire process is architected as a standard supervised fine-tuning task, sidestepping the volatility and complexity of reinforcement learning loops.
- Open for Business: The method is being integrated into standard libraries like
huggingface/trl, signaling its readiness for production.
Introduction
The alignment of Large Language Models (LLMs) via Reinforcement Learning from Human Feedback (RLHF) was a necessary, if somewhat crude, step forward. It taught machines to mimic our preferences. Yet, it left a gaping architectural flaw: the models possess no capacity for introspection. An RLHF-tuned model is a one-shot generator. It cannot review its own work, question its own premises, or correct a flawed line of reasoning. A single hallucination can, and often does, trigger a cascade of confident sophistry. The ghost in the machine remains stubbornly inert.
The fundamental question then becomes:
“Why can’t the model look at its own answer and just improve it?”
Cohere’s Self-Improving Robust Preference Optimization (SRPO) provides a surprisingly elegant answer. This article unpacks the theory, offers a minimal PyTorch implementation, and examines the empirical results that suggest a new, more robust baseline for alignment.
1 Where Vanilla RLHF Falls Short
Vanilla RLHF operates by bolting an external reward model onto a generator. During inference, the generator gets one shot to produce an answer. If that answer is suboptimal-marred by error or a lack of nuance-the system has no native mechanism for self-correction. Techniques like chain-of-thought are mere scaffolding; they encourage better reasoning paths but provide no guarantee of improvement and do not grant the model the ability to revise a completed output. The fundamental architecture remains brittle.
2 From Direct Preference Optimisation to SRPO
Direct Preference Optimisation (DPO) offered a cleaner path, reformulating the RL objective into a simple classification loss on pairs of human-preferred and dispreferred responses . It pushes the model to increase the log-odds of the winning completion. SRPO builds on this insight, generalizing the concept from a simple preference to a mechanism for self-improvement:
- A Self-Improvement policy
is trained to transform a weak draft into a superior one.
- A Generative policy
is simultaneously trained to produce drafts that require minimal editing from
The architectural elegance of SRPO is that both policies are learned by the same model, with a single, unified supervised objective. It is almost as simple to implement as DPO, yet far more powerful.
3 The SRPO Workflow
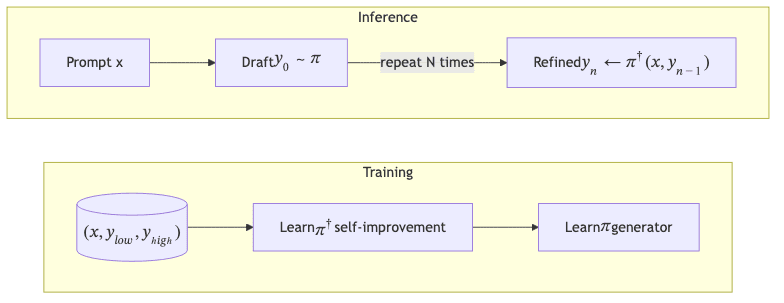
3.1 Mathematics in a Nutshell
For a single pair, the human preference label is defined as:
Self-Improvement Objective
The revision policy learns to prefer the higher-quality completion.
Generative Objective
The drafting policy learns to generate outputs that align with the better preference.
Joint SRPO Loss
The two objectives are combined into a single mean-squared error loss, where all gradients flow back through the same model weights.
(σ denotes the logistic sigmoid; β is the temperature hyper-parameter.)
3.2 The Deceptive Simplicity of Implementation
This entire process can be implemented in a standard supervised learning framework, as shown in this PyTorch skeleton.
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch, torch.nn.functional as F
model = AutoModelForCausalLM.from_pretrained("meta-llama/Meta-Llama-3-8B")
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Meta-Llama-3-8B")
optimizer = torch.optim.AdamW(model.parameters(), lr=2e-6)
def srpo_loss(batch, alpha=0.8, beta=0.01):
# batch: dict with keys x, y_hi, y_lo, labels (1/0)
def logp(text):
ids = tokenizer(text, return_tensors="pt").input_ids.to(model.device)
return model(ids, labels=ids).loss.detach().neg() # negative NLL
logp_hi, logp_lo = map(logp, [batch["y_hi"], batch["y_lo"]])
delta = beta * (logp_hi - logp_lo)
target = batch["labels"].float().to(model.device)
l = F.mse_loss(torch.sigmoid(delta), target)
return (1 - alpha) * l + alpha * l.detach() # second term approximates L†
for batch in dataloader:
loss = srpo_loss(batch)
loss.backward(); optimizer.step(); optimizer.zero_grad()Note the absence of a separate reward model, PPO, or a KL controller. It is pure, unadulterated gradient descent.
4 Empirical Results
The true test of an alignment method is its performance on out-of-distribution (OOD) data-tasks the model wasn’t explicitly trained on. This is where SRPO’s robustness becomes apparent.
| Dataset | Metric (GPT‑4 judge) | DPO (0 rev) | SRPO (0 rev) | SRPO (5 rev) |
|---|---|---|---|---|
| TL;DR (in‑dist.) | win‑rate ↑ | 0.82 | 0.84 | 0.86 |
| XSum (OOD) | win‑rate ↑ | 0.73 | 0.78 | 0.90 |
A mere five self-revision steps at inference time deliver a +15 percentage point gain on an OOD summarisation benchmark, demonstrating a remarkable ability to generalize and self-correct.
5 Notes from the Engineering Front
Early pull requests against huggingface/trl provide a glimpse into the practical implementation details:
- LoRA Configuration: A rank of
16and alpha of32are sufficient, with no need for gradient checkpointing, keeping the memory footprint manageable. - Temperature Tuning (β): A value of
0.01is recommended for SRPO, lower than DPO’s typical0.1, to maintain comparable variance between the methods. - Trade-off Parameter (α): Sweeping values around
0.8appears to yield the best balance between performance on in-distribution and OOD tasks.
I will update this article with a link to the official implementation once the pull request is merged.
6 Why SRPO Matters
- Industrial Scalability: As a pure supervised learning method, SRPO integrates seamlessly into existing large-scale fine-tuning infrastructure (FSDP, DeepSpeed, TPUs).
- Architectural Stability: By avoiding adversarial reinforcement learning dynamics, it sidesteps common failure modes like reward hacking and training oscillations.
- Emergent Interpretability: Because the same model generates and critiques, it externalizes rich signals about its own confidence and reasoning, creating new opportunities for tool-augmented pipelines.
7 Limitations & Future Frontiers
The current formulation is not a panacea. It opens up new engineering challenges and research questions.
| Limitation | Possible Remedy |
|---|---|
| Extra latency per revision | Speculative decoding & batch caching |
| Hyper‑parameter β is brittle | Entropy‑regularised schedule |
| Text‑only formulation | Extend derivation to multi‑modal LLMs |
Conclusion
SRPO equips an LLM with an internal critic, enabling it to refine its own work long after training concludes. The method preserves the architectural simplicity of direct preference optimisation while delivering robustness gains that challenge far more complex RLHF pipelines. It is a meaningful step toward models that don’t just answer, but reason about their answers-grafting a flicker of introspection onto the silicon.
Further Reading
- Direct Preference Optimisation – Rafailov, R. et al. (2023).
- Cohere For AI Blog – “Command-R & SRPO internals”.
- Reinforcement Learning from Human Feedback (Wikipedia).
- GitHub discussion on the
huggingface/trlimplementation: https://github.com/huggingface/trl/issues/1714.