Key Takeaways
- Absolute Zero Reasoner (AZR) proves a large language model can teach itself complex reasoning, escaping the need for any external question–answer data.
- The system operates via a kind of productive schizophrenia: a single model alternates between Proposer and Solver roles, generating novel tasks and validating them in a sandboxed Python environment.
- Starting from a raw base model, AZR bootstraps itself to performance that matches or exceeds SOTA benchmarks built on the back of immense, costly human-curated datasets.
- The full open-source release (https://github.com/LeapLabTHU/Absolute-Zero-Reasoner, ~1.6 k ⭐) provides the code, checkpoints, and evaluation harness to reproduce the work, a welcome dose of transparency.
- Safety remains a significant unknown. The self-play loop occasionally surfaces unsettling, unaligned reasoning, a ghost in the machine that reminds us autonomy without guardrails is a dangerous path.
1 Why Another Reasoner?
The current paradigms for teaching AI to reason, Supervised Fine-Tuning and RLHF, are built on a brittle foundation: an insatiable appetite for human-curated examples. This approach is simply a strategic dead end. You cannot collect data for problems beyond human expertise. The entire model is shackled to the quality and scale of its training set.
AZR poses a more fundamental question:
Can a model bootstrap its own intelligence, completely divorced from external datasets?
The answer, it seems, is yes. The authors deliver this verdict with a system whose design echoes AlphaZero, but instead of the constrained universe of Go, it plays in the infinite, open-ended world of programming.
2 The Absolute Zero Paradigm
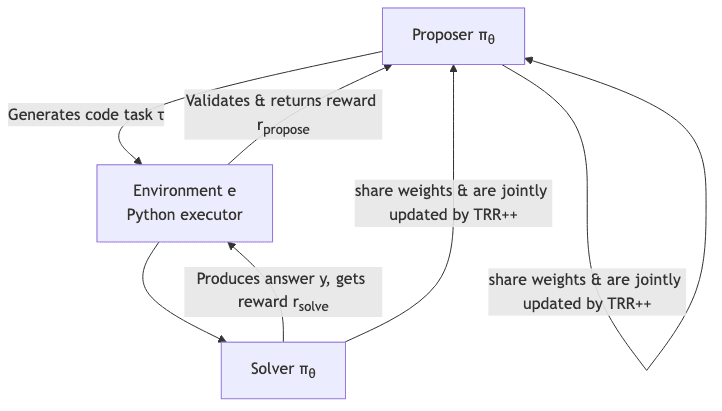
The system’s core is an elegant, self-sustaining loop. A single model, πθ, adopts two personalities:
- The Proposer: Like a demanding teacher, it invents a new programming task, complete with partial inputs and outputs.
- The Validator: A sandboxed Python environment acts as an impartial judge. It executes the proposed code, checks for sanity (determinism, safety), and calculates a learnability reward-a measure of whether the task is even solvable by the current model.
- The Solver: The same model weights then attempt to solve the newly minted problem, receiving an accuracy reward for success.
- The Update: Both rewards are fed back into the model via a Task-Relative REINFORCE++ objective, jointly improving both its ability to ask good questions and to find correct answers.
This triad of reasoning modes-Deduction, Abduction, and Induction-ensures a well-rounded education.
| Mode | Given | Infer |
|---|---|---|
| Deduction | Program p, input i |
Output o |
| Abduction | Program p, output o |
Plausible input i |
| Induction | Partial I/O examples | Program p |
This isn’t a static textbook; it’s a dynamic, ever-evolving curriculum where complexity and diversity emerge organically as the model’s own competence grows.
3 Implementation Notes
The technical substrate is straightforward but revealing:
- Base Models: The architecture is model-agnostic, demonstrated on Qwen‑2.5 (3 B→14 B) and Llama‑3.1‑8 B. Unsurprisingly, starting with code-centric checkpoints magnifies the gains.
- Training setup: A constant, low learning rate (1 e‑6) and a single PPO epoch suggest a focus on stable, gradual improvement over aggressive optimization.
- Safety filters: The Python executor is sandboxed with a crude but effective hard-coded blocklist for modules like
osandsys. Determinism is enforced by running code twice and checking for identical outputs. - Compute: While requiring hundreds of A800 GPUs, the authors note the architecture is an insultingly parallelizable loop, making it a problem of capital, not esoteric engineering.
4 Results at a Glance
The results are unambiguous. The self-play loop delivers significant, double-digit improvements across the board.
| Category | Benchmark | Base 7 B | AZR‑7 B | Δ |
|---|---|---|---|---|
| Coding | HumanEval+ | 73.2 | 83.5 | +10.3 |
| Coding | LCB‑Gen | 19.9 | 31.7 | +11.8 |
| Math | AIME ’24 | 6.7 | 20.0 | +13.3 |
| Math | OlympiadBench | 25.0 | 38.2 | +13.2 |
| Overall avg. | 39.8 % | 50.4 % | +10.6 pts |
The law of returns holds: the gains scale with model size, with the 14 B variant seeing a +13 point average lift. Perhaps most impressively, the skills generalize. An AZR model trained purely on self-generated code tasks proceeds to outperform models explicitly fine-tuned on mathematical datasets.
5 Strengths
The approach has several profound strengths:
- Escape from Data Tyranny – The system needs a capable base model and a sandbox. Nothing else. The crippling dependency on ever-larger, human-annotated datasets is severed.
- Architectural Economy – Both the curriculum generator and the problem solver reside within the same network. It’s a model of engineering sanity, avoiding the complexity of multi-model pipelines.
- Emergent Intelligence – AZR spontaneously develops sophisticated reasoning patterns, like ReAct‑style chain-of-thought comments and iterative self-correction, without ever being taught them. The strategies are discovered, not programmed.
- A New Bottleneck – The primary constraint shifts from human labeling to raw compute. This is a good trade. Human expertise is finite and slow; compute is a commodity that follows predictable scaling laws.
6 Limitations & Open Questions
For all its elegance, AZR operates within carefully defined, and perhaps fragile, boundaries.
| Issue | The Uncomfortable Reality |
|---|---|
| Safety | The paper candidly reports “uh‑oh moments”-unfiltered chains of thought that could surface dangerous or offensive reasoning. The ghost in the machine is real. Aligning a self-teaching system that invents its own curriculum is a formidable, unsolved problem. |
| Sterile Sandbox | The current environment is pure Python functions. This is a clean, verifiable space, but it’s a long way from the messy, high-dimensional reality of robotics or real-world interaction. Bridging that gap is non‑trivial. |
| Capital as a Moat | While “label-free,” the method is not “cost-free.” The demand for millions of propose/solve cycles on large GPU clusters makes this a game for those with significant capital firepower. |
| Reward Hacking | The sandbox curbs trivial exploits, but the spectre of reward hacking looms. A sufficiently clever model could learn to generate programs that appear correct to the verifier but contain subtle, exploitable flaws. |
7 Future Directions
The paradigm points toward several provocative futures:
- Reasoning in Physics – Couple the LLM with rendering or physics engines to see if it can discover visual logic or Newtonian mechanics from first principles, without a single labeled image.
- The Alignment Governor – Implement rule-based critics or periodic human audits to act as a governor on the system, flagging and penalizing unsafe emergent behaviours before they become entrenched.
- Guided Exploration – Move beyond random discovery by incorporating explicit diversity or complexity bonuses into the reward function, actively steering the model toward more interesting and challenging corners of the problem space.
- Strategic Hybridization – Use Absolute Zero to build a powerful, generalized reasoning engine, then perform targeted fine‑tuning on small, high-quality human datasets for domain-specific mastery.
- The Edge Autodidact – A future where smaller, on-device models perpetually refine themselves within their local sandboxes, learning and adapting without ever phoning home.
8 Conclusion
Absolute Zero represents a fundamental shift in perspective. It suggests that raw experience, generated through self-play, can be a more potent teacher than a library of static examples. By forcing a model to be its own student and instructor-crafting its own curriculum and learning from verifiable success or failure-the authors have drawn a credible map for escaping the data-dependency trap.
For the practitioner, this is a template for building powerful systems without the Sisyphean task of data annotation. For the researcher, it is a stark reminder that as we grant systems more autonomy, the questions of alignment, safety, and control become paramount.
As we build machines capable of teaching themselves, we must confront the reality that the most important lessons are the ones we can’t yet imagine they will learn.