Key Takeaways
- The Three-Act Play of Instruction Tuning: Strong instruction models aren’t born; they’re forged. The process follows a disciplined, three-stage ritual: Supervised Fine-Tuning (SFT), Direct Preference Optimisation (DPO), and Reinforcement Learning with Verifiable Rewards (RLVR).
- Taming the Hardware Beast: The brutal physics of VRAM requirements can be tamed. Intelligent batching, cached reference logits, and the surgical precision of parameter-efficient fine-tuning (LoRA/QLoRA) slash memory demands, bringing powerful models within reach of non-hyperscale infrastructure.
- Elegance Trumps Brute Force: In the contest of alignment methods, length-normalised DPO consistently proves its mettle, delivering superior results while maintaining the stability and economic sanity that heavier-handed alternatives often sacrifice.
- Injecting Verifiable Truth: RLVR provides the final, crucial dose of discipline. By swapping a squishy, learned reward model for a hard, deterministic verifier, PPO is forced to chase provably correct completions, yielding tangible gains in reasoning and instruction-following.
- No Secret Sauce, Just Open Engineering: The entire recipe is laid bare-datasets, checkpoints, and training code are fully open on Hugging Face and GitHub. The advantage lies not in proprietary data, but in disciplined execution.
Why Post‑Train at All?
A pre-trained model is a vessel of raw statistical fluency. It has learned the grammar of human language, the patterns of text on the internet, but it possesses no inherent desire to be helpful. It knows how to speak, but not how to listen.
Post-training is the crucible where this raw potential is forged into a tractable tool. By systematically injecting supervised signals, preference comparisons, and verifiable rewards, we take a base model like Llama 3.1 and sculpt it into an agent that understands and follows instructions. We are teaching it the shape of our intent.
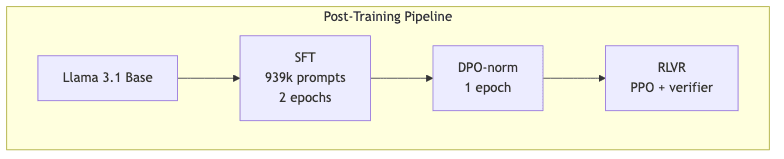
A Snapshot of the Training Setup
| Stage | Dataset size | Epochs | Effective batch | Sequence length |
|---|---|---|---|---|
| SFT | ~939k | 2 | 128 | 4,096 tokens |
| DPO-norm | 4M ranked pairs (synthetic) | 1 | 64 | 1,024 tokens |
| RLVR (Math + Instr.) | 160k prompts | variable PPO steps | – | 512 tokens |
The original campaign was run on a formidable 128 H100 GPUs (16 × 8), commanding roughly 10 TB of VRAM. I’ll demonstrate how to replicate the essence of each stage on a single multi-GPU system using the familiar toolkit of Hugging Face Transformers and the TRL library.
Step 1 – Supervised Fine‑Tuning (SFT)
SFT is the foundational schooling, the initial indoctrination into the grammar of human requests. Here, the model learns the basic format of a helpful response. The critical insight from the trenches was a subtle but powerful change in the loss calculation: summing the per-batch loss instead of averaging by sequence length. This corrects a sneaky gradient accumulation bug that otherwise dilutes the learning signal.
from datasets import load_dataset
from transformers import AutoTokenizer, AutoModelForCausalLM, TrainingArguments, Trainer
model_id = "meta-llama/Meta-Llama-3-8B"
new_model = "llama3-8b-sft"
# 1️⃣ Data
mix = load_dataset("allenai/tulu-3-sft-mixture", split="train")
# 2️⃣ Tokenizer / model
tok = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype="auto")
# 3️⃣ A loss function that SUMS, not averages. Crucial.
from torch.nn import CrossEntropyLoss
class SumLoss(torch.nn.Module):
def __init__(self):
super().__init__()
self.ce = CrossEntropyLoss(reduction="sum")
def forward(self, logits, labels):
return self.ce(logits.view(-1, logits.size(-1)), labels.view(-1))
model.loss_fn = SumLoss()
args = TrainingArguments(
output_dir=new_model,
per_device_train_batch_size=1, # True micro-batch
gradient_accumulation_steps=128, # Effective batch size of 128
num_train_epochs=2,
lr_scheduler_type="cosine",
learning_rate=5e-5,
fp16=True,
)
trainer = Trainer(model, args, train_dataset=mix)
trainer.train()Tip 💡 For larger models like the 70B variant, switching to QLoRA is a pragmatic necessity. It slashes VRAM usage by a factor of ~4x with almost no degradation in quality.
Step 2 – Direct Preference Optimisation (DPO‑norm)
DPO offers a more elegant, capital-efficient path to alignment, sidestepping the need to train a separate, cumbersome reward model. Among four tested variants-standard DPO, length-normalised DPO, SimPO, and PPO-the length-normalised version (dpo_n) emerged as the clear winner.
The Memory-Friendly Gambit 👉 Cached Reference Logits
A naive DPO implementation is a memory hog, loading two full copies of the model (policy + reference). For a 70B model, this is a >140 GB VRAM nightmare. AI2’s solution was to cache the reference logits once and reuse them. My preferred alternative achieves a similar end: using LoRA adapters, which allows a single base model to host both policy and reference states as lightweight, swappable adapter sets.
from trl import DPOTrainer
from peft import LoraConfig, get_peft_model
policy = AutoModelForCausalLM.from_pretrained(new_model, torch_dtype="auto")
reference = policy.clone() # Weights are frozen
# Attach lightweight adapters to the policy model
peft_cfg = LoraConfig(target_modules=["q_proj", "k_proj", "v_proj"], r=8, alpha=32)
policy = get_peft_model(policy, peft_cfg)
trainer = DPOTrainer(
model=policy,
ref_model=reference,
beta=0.1,
max_length=1024,
per_device_train_batch_size=4,
learning_rate=1e-5,
num_train_epochs=1,
dataset="allenai/tulu-3-dpo-mixture", # Synthetic GPT-4o labels
tokenizer=tok,
loss_type="dpo_n", # The length-normalized winner
)
trainer.train()A note on stochasticity: Be warned that something as trivial as the RNG seed can swing average benchmark scores by a non-trivial ±2 points. Reproducibility demands rigor.
Step 3 – Reinforcement Learning with Verifiable Rewards (RLVR)
This is where the model earns its stripes. RLVR dispenses with the squishy, probabilistic reward model of traditional RLHF and substitutes it with something unforgiving: a deterministic verifier. If a generated answer passes the checker, it gets a reward of 1. If it fails, it gets 0. The underlying PPO algorithm now chases a binary signal that is always correct, forcing it towards provable accuracy.
from trl import PPOTrainer, PPOConfig
# A simple, deterministic verifier for GSM8K-style math problems 👇
import re, math
def verifier(prompt, answer):
try:
extracted = re.search(r"([\-\d\.,]+)", answer).group(1)
# Check if the extracted number is close to the true answer
return abs(float(extracted) - eval(prompt.split("=")[1])) < 1e-3
except Exception:
return False
ppo_cfg = PPOConfig(model_name=new_model, learning_rate=1e-6, batch_size=4)
agent = PPOTrainer(config=ppo_cfg, model=model, tokenizer=tok, verifier=verifier)
# The PPO loop runs for many steps, chasing the verifier's signal
for step in range(50_000):
batch = agent.sample_prompts("gsm8k_prompts.jsonl")
agent.step(batch)In the full-scale experiment, AI2 ran for millions of PPO episodes. Even on a smaller scale, this method demonstrably lifts GSM8K accuracy by a noticeable point or more.
The Cost-Cutting Playbook
| Tweak | Why it helps | Typical win |
|---|---|---|
| LoRA/QLoRA | Swaps monolithic weight matrices for lean, low-rank adapters. | ↓ VRAM 4–8× |
| Flash‑Attention 3 | Fuses attention kernels, unlocking throughput on long sequences. | ↑ tokens/s 1.4–2× |
| Gradient-checkpointing | Trades compute for memory by recomputing activations on the fly. | ↓ VRAM ≈40% |
| Mixed‑precision (bf16) | Keeps matrix math inside high-speed tensor cores without quality loss. | ↔︎ quality, ↓ memory |
Final Thoughts
With a toolkit no more exotic than Transformers + TRL, we can reproduce the core logic of a state-of-the-art model like TÜLU 3 and, more importantly, adapt the recipe to our own domains. The TÜLU project demonstrates that the path to powerful instruction-following models is less about some secret hoard of data and more about the disciplined, principled application of open techniques. The recipe is out there.
Go build. – RK