The Gist
- Coconut frees Large Language Models from the tyranny of tokens. By looping the hidden state back as the next input, the model reasons in a continuous latent space instead of plodding through natural language.
- Latent reasoning is brutally efficient. On math and logic benchmarks, Coconut matches or beats traditional Chain-of-Thought while generating vastly fewer tokens. It’s the difference between thinking and just talking to yourself.
- Breadth-First Search emerges without being told. Continuous thoughts simultaneously encode multiple next-step hypotheses, allowing the model to prune bad paths on the fly-no explicit tree-search code required.
- A curriculum is non-negotiable. Naïvely dropping a model into latent reasoning stalls it. It must be taught to swim by gradually replacing language steps with continuous thoughts.
- The implementation is open-source at facebookresearch/coconut.
1. Why Language is a Prison for Thought
The biological wetware offers a clue. Neuro-imaging consistently shows our linguistic cortex sitting idle during symbolic reasoning. We don’t think in words when we’re deep in a problem; we think in concepts, relationships, abstractions.
Yet we chain our silicon minds to the same token-by-token chatter we use. Every micro-step of an LLM’s reasoning must be decoded into a word, incurring an equal compute budget whether that token is a breakthrough ("\(x²−4\)=0") or mere filler (“, therefore”).
“Most tokens are for narrative fluency, not for solving the problem.” - Original Coconut paper
This glaring inefficiency screams for an alternative: keep the heavy lifting in a continuous vector space and surface the language only when you have something to say.
2. From Chain-of-Thought to Chain-of-Continuous-Thought
The architectural change is disarmingly simple. One mode talks, the other thinks.
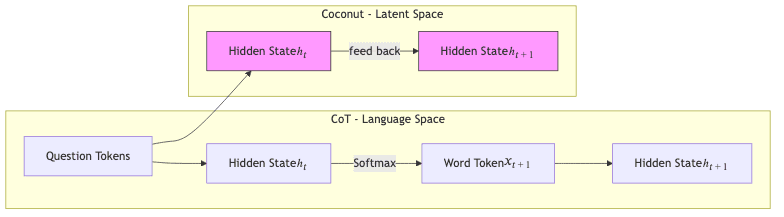
Two special tokens act as the gatekeepers for this new mode:
<bot> # begin-of-thought – enter latent mode
<eot> # end-of-thought – revert to language modeBetween <bot> and <eot>, the decoder doesn’t bother with the LM head. It simply pipes the previous hidden vector back into the embedding table. No chit-chat, just pure computation.
3. Inside the Coconut Engine
3.1. Language vs. Latent Mode
In pseudocode, the logic is trivial:
# x_embed is normal token embeddings E_t
h_t, _ = transformer_block(x_embed)
if latent_mode:
# No softmax, no sampling. Just feed the thought back.
next_input = h_t.detach()
else:
# Business as usual.
probs = lm_head(h_t)
next_token = sample(probs)
next_input = embedding(next_token)The elegance is in the economy. Zero new parameters are added.
3.2. The Multi-Stage Curriculum
A model thrown into the deep end of latent space doesn’t learn to swim; it drowns. Training must proceed in stages. At stage k, the first k natural-language reasoning steps are replaced by k·c continuous thoughts. Loss is only ever applied to the final, downstream text, forcing the model to make its latent steps meaningful.
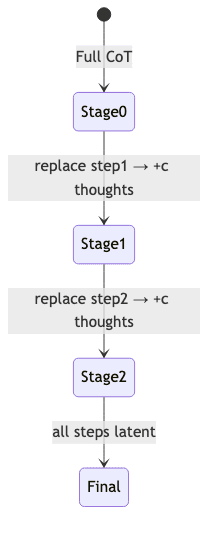
Without this graduated curriculum, the model simply fails to converge. It has to be shown the path.
4. Empirical Highlights
The numbers speak for themselves.
| Dataset | CoT Acc. | Coconut Acc. | Tokens ↑ (% more) |
|---|---|---|---|
| GSM8k (math) | 42.9 % | 34.1 % | –67 % |
| ProntoQA (logic) | 98.8 % | 99.8 % | –90 % |
| ProsQA (hard logic) | 77.5 % | 97.0 % | –71 % |
Lower token count means higher efficiency. While accuracy on GSM8k dips, the real slaughter is on planning-heavy tasks like ProsQA, where Coconut delivers a beatdown to standard CoT.
4.1. Latency
This isn’t just a theoretical token-counting exercise; it’s metal-on-the-table reality. ProsQA inference on an A100 GPU: 0.15s vs. 0.47s. Faster thinking, faster answers.
5. Emergent Breadth-First Search
This is where things get interesting. Coconut’s hidden vector isn’t a single, committed thought. It’s a superposition of possibilities, effectively expanding the frontier of a search tree in parallel.
5.1. A Toy Search Trace
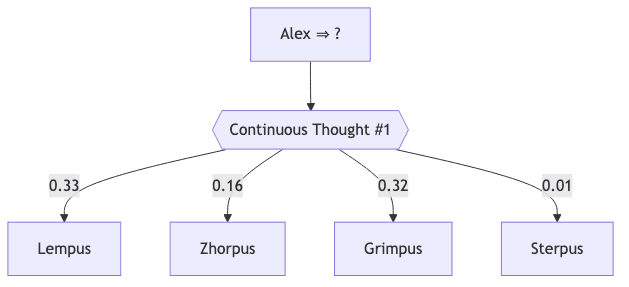
After another latent step, the distribution sharpens, pruning the dead-ends without a single line of explicit search code. The authors call this an implicit value function; I call it emergent, efficient reasoning.
5.2. Why Planning Gets Easier
Let denote the height of a node
(its shortest distance to a solution). The paper shows a monotonic relationship between a path’s viability and this height:
The model instinctively learns to deprioritize nodes near dead ends (low ) and keep exploring deeper paths. It’s precisely what a good heuristic search should do, but without the algorithmic overhead.
6. Getting Your Hands Dirty 📦
# Clone the repository
$ git clone https://github.com/facebookresearch/coconut
$ cd coconut
# Install dependencies (use a virtual environment)
$ pip install -r requirements.txt
# Run a math demo
time python demo/gsm8k_infer.py \
--model gpt2 \
--num_latent 3 \
--question "A pen costs $2..."A word of warning: Don’t expect to see plain-text reasoning steps spill out. The thoughts are latent for a reason. You’ll need their probing scripts to translate the machine’s inner monologue back into something a human can read.
7. The Reasoning Zoo
Where does this fit?
| Method | Latent? | Extra Params | Strength | Weakness |
|---|---|---|---|---|
| Pause Tokens (Goyal 2023) | ✗ (discrete filler) | 0 | Cheap speed-up | Limited expressivity |
| iCoT (Deng 2024) | Implicit | 0 | Removes chain | Still token-level |
| Coconut | ✓ | 0 | Parallel BFS, efficiency | Curriculum training cost |
8. Limitations & Open Questions
- The curriculum, while necessary, creates a serial bottleneck during training that impedes clean data-parallelism.
- The decision of when to cut over from language to latent thought remains more art than science.
- The real test is scale. Does this elegance hold up at 70B+ parameters, or does the approach fracture under the weight of a truly massive model? The early signs are good, but the data is thin.
9. What’s Next
Latent reasoning feels like a small tweak with an outsized impact-much like how attention once looked like just another layer. This is a primitive worth watching. I’m keen to see:
- Models pre-trained with continuous thought baked in, not just fine-tuned.
- Hybrid pipelines where language provides a sparse outline and Coconut’s latent engine fills the computational gaps.
- Integration with tool-use: can latent thoughts steer external API calls without polluting the context window with conversational fluff?
The repository is on my watchlist. This is a space worth observing.
References
Wei, J., et al. (2022). Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. arXiv:2201.11903.
Deng, Z., et al. (2024). Eliminating the Chain of Thought: A New Approach to In-Context Learning. arXiv:2405.14838.
“Breadth-first search” on Wikipedia.