Key Takeaways
- Llama 3.1 is brutally resilient to 4‑bit quantization. My benchmarks show an accuracy delta within a trivial ±1 percentage point (pp) on MMLU and ARC‑Challenge for the leading methods.
- AWQ and AutoRound‑sym represent the current sweet spot. They deliver near‑FP16 accuracy, leverage GPU-native Marlin kernels for speed, and compress the model to a lean 5.7 GB.
- Bitsandbytes (NF4) remains the path of least resistance for QLoRA fine‑tuning, but its generic runtime kernels lag significantly in pure inference throughput.
- GPTQ is the battle-hardened incumbent. Its mature CUDA kernels make it a safe, reliable choice for production, even if it’s no longer the absolute front-runner on accuracy.
- AQLM is the nuclear option for memory. When sub-5 GB is non-negotiable, its 2‑bit, 4.1 GB model is the answer-if you can tolerate a steep performance penalty.
- The heuristic is clear: with ≥ 24 GB of VRAM, AWQ or AutoRound is the logical starting point. If you have less, consider a smaller base model before resorting to the compromises of 2‑bit.
Why Quantization Matters
The memory footprint of an LLM is governed by an inescapable equation: the number of parameters N multiplied by their precision b.
Migrating from 16-bit floating-point (FP16) to 4-bit integers (INT4) is a 4× reduction in the size of the weight tensors. For an 8-billion parameter Llama 3.1, this translates to a drop from 16 GB to 4 GB for the weights alone-before even accounting for embeddings and the final language model head.
VRAM relief is the obvious prize, but the downstream effects are where the real value lies. Quantization:
- Slashes PCIe bandwidth requirements-a critical bottleneck in multi-GPU inference servers.
- Enables larger batch sizes, dramatically improving token-per-second throughput.
- Reduces the power draw for every query processed.
The challenge, of course, is harvesting these gains without sacrificing the model’s accuracy or its runtime velocity. The five contenders below each offer a different philosophy on navigating this trade-off.
Meet the Contenders
| Method | Quant type | Calibration | CUDA kernels | Disk (8 B) | Best use‑case |
|---|---|---|---|---|---|
| Bitsandbytes (NF4 + double‑quant) | PTQ‑on‑load | ✗ | Generic (slower) | 5.73 GB | The forge for QLoRA fine‑tuning |
| AWQ | Activation‑aware INT4 | ✓ (quick) | Marlin | 5.73 GB | High-performance production inference |
| GPTQ | Error‑aware INT4 | ✓ | Triton/Marlin | 5.73 GB | Production inference (legacy stack) |
| AutoRound‑sym | Learned rounding INT4 | ✓ | Marlin | 5.73 GB | High-performance production inference |
| AQLM (2‑bit) | Additive quant 2‑bit | ✓ (heavy) | Generic | 4.08 GB | Extreme memory constraints |
Experimental Setup
The proving ground for these tests was straightforward:
- Hardware: An NVIDIA RTX 4090 with 24 GB VRAM, running on CUDA 12.3 and PyTorch 2.1.
- Software: The stack included
transformers == 4.39,auto-gptq,autoawq,auto-round,bitsandbytes == 0.43,vllm, and the Eleuther‑AI lm‑evaluation‑harness.
The benchmarks were structured as follows:
- Accuracy: MMLU and ARC‑Challenge, measured in a 0‑shot setting.
batch_sizewas set to 8 for INT4 models and 4 for the memory-heavy FP16 baseline. - Throughput: Evaluated using
vllm/benchmark_throughput.pywith a 100-token prompt and 250 generated tokens. - Memory: Reported as the final on‑disk model size, a close proxy for the VRAM consumed by the weights post-loading.
The quantization workflow is conceptually simple:
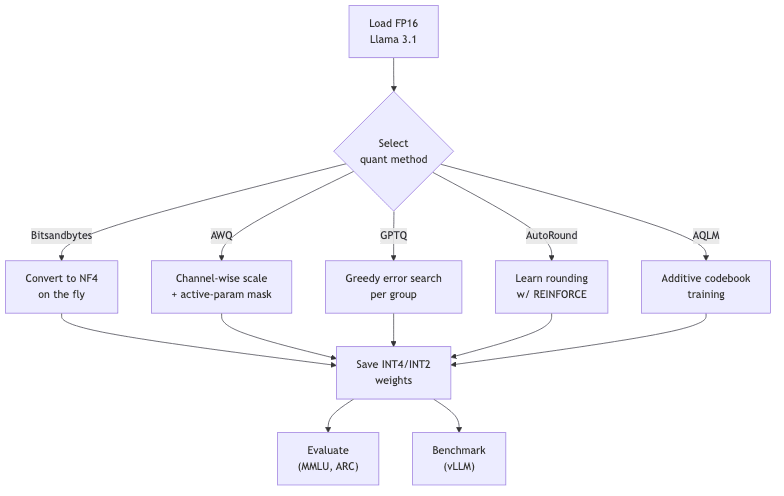
Hands‑On: Quantizing Llama 3.1
What follows are the distilled Python scripts for quantizing the Llama 3.1 8B Instruct model. Each can be executed on a single 24 GB GPU. The model identifier can be swapped with meta-llama/Meta-Llama-3.1-8B for the base variant.
Bitsandbytes (NF4 + double‑quant)
The path of least resistance, especially for the well-trodden ground of QLoRA. Quantization is an on-the-fly affair, a convenience that comes at a cost to performance.
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
import torch
import bitsandbytes as bnb # noqa: F401, Import bitsandbytes to ensure its functions are registered
bnb_cfg = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16 if torch.cuda.is_bf16_supported() else torch.float16,
bnb_4bit_use_double_quant=True,
)
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Meta-Llama-3.1-8B-Instruct",
quantization_config=bnb_cfg,
device_map="auto" # Automatically map model to available devices
)
# Saving the quantized model is optional, as BitsAndBytes applies quantization dynamically at load time. If you want to save the config for future loading:
# model.save_pretrained("bnb-4bit-model")
# tokenizer.save_pretrained("bnb-4bit-model")Note: save_pretrained for BitsAndBytes models primarily saves the configuration. The quantization is applied dynamically at load time.
AWQ (Activation-aware Weight Quantization)
AWQ’s philosophy is one of intelligent triage, focusing its precision on weights that matter most to activation distributions. The calibration is fast and effective.
from awq import AutoAWQForCausalLM
from transformers import AutoTokenizer
model_name_or_path = "meta-llama/Meta-Llama-3.1-8B-Instruct"
quant_path = "awq-4bit-llama-3.1-8b-instruct"
# Load model and tokenizer
model = AutoAWQForCausalLM.from_pretrained(
model_name_or_path,
safetensors=True,
device_map="cuda" # Ensure model is on CUDA for quantization
)
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, trust_remote_code=True)
# Quantize
quant_config = { "zero_point": True, "q_group_size": 128, "w_bit": 4, "version": "GEMM" }
model.quantize(tokenizer, quant_config=quant_config)
# Save quantized model
model.save_quantized(quant_path, safetensors=True)
tokenizer.save_pretrained(quant_path)GPTQ (Generalized Post-Training Quantization)
GPTQ is the methodical veteran, painstakingly minimizing quantization error layer-by-layer against a small calibration dataset.
from optimum.gptq import GPTQQuantizer
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name_or_path = "meta-llama/Meta-Llama-3.1-8B-Instruct"
quantized_model_path = "gptq-4bit-llama-3.1-8b-instruct"
# Load model and tokenizer
model = AutoModelForCausalLM.from_pretrained(
model_name_or_path,
torch_dtype="auto", # Use appropriate torch_dtype
device_map="cuda" # Ensure model is on CUDA for quantization
)
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
# Initialize quantizer
# Using "c4" (Common Crawl) dataset for calibration. You can use other datasets like "wikitext2".
# A small subset of a dataset is usually sufficient.
quantizer = GPTQQuantizer(bits=4, dataset="c4", model_seqlen=2048)
# Quantize model
quantized_model = quantizer.quantize_model(model, tokenizer)
# Save quantized model
quantized_model.save_pretrained(quantized_model_path, safetensors=True)
tokenizer.save_pretrained(quantized_model_path)AutoRound (sym‑only works with Marlin kernels)
AutoRound eschews simple heuristics, instead learning the optimal rounding strategy-a more computationally intensive but theoretically elegant approach. Symmetric quantization is key for Marlin kernel compatibility.
from auto_round.auto_round import AutoRound
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model_name_or_path = "meta-llama/Meta-Llama-3.1-8B-Instruct"
quantized_model_dir = "autoround-sym-llama-3.1-8b-instruct"
# Load base model and tokenizer
base_model = AutoModelForCausalLM.from_pretrained(
model_name_or_path,
torch_dtype=torch.float16, # AutoRound typically works well with float16
device_map="cuda" # Ensure model is on CUDA
)
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, trust_remote_code=True)
# Initialize AutoRound
# `seqlen` is for calibration data length; `nsamples` for number of calibration samples
autorounder = AutoRound(
base_model,
tokenizer,
bits=4,
group_size=128,
sym=True, # Symmetric quantization for Marlin compatibility
seqlen=512, # Sequence length for calibration
nsamples=128, # Number of samples for calibration
# device="cuda" # Redundant if model is already on CUDA via device_map
)
# Perform quantization
autorounder.quantize()
# Save quantized model
autorounder.save_quantized(quantized_model_dir, safe_serialization=True)
# Tokenizer is typically saved separately if not handled by save_quantized
tokenizer.save_pretrained(quantized_model_dir)AQLM (Additive Quantization of Language Models, 2‑bit)
AQLM takes a more radical approach, abandoning simple scalar quantization for an additive, codebook-based method. This is the path to extreme compression, best accessed via pre-quantized models from research groups like ISTA-DASLab.
Downloading a pre-quantized 2-bit AQLM model: This model is already quantized and hosted on Hugging Face. Download it using Git LFS:
git lfs install
# Download the 2-bit AQLM model
git clone https://huggingface.co/ISTA-DASLab/Llama-3.1-8B-Instruct-AQLM-PV-2Bit-1x16-hfAlternatively, you may use the Hugging Face transformers library to load the model directly in Python.
Results
After running each model through the gauntlet, the data speaks for itself.
Memory Footprint
The compression is immediate and dramatic. The 4x reduction isn’t perfect across the board; the unquantized embeddings and LM head remain, a stubborn reminder of the components that resist this particular brand of compression.
| Model | Precision | Disk | Δ vs FP16 |
|---|---|---|---|
| FP16 baseline | 16‑bit | 16.1 GB | – |
| Bitsandbytes | 4‑bit | 5.73 GB | – 10.3 GB |
| AWQ | 4‑bit | 5.73 GB | – 10.3 GB |
| GPTQ | 4‑bit | 5.73 GB | – 10.3 GB |
| AutoRound‑sym | 4‑bit | 5.73 GB | – 10.3 GB |
| AQLM | 2‑bit | 4.08 GB | – 12.0 GB |
Accuracy (@ 0‑shot)
The accuracy penalty is, for most methods, trivial-a testament to the over-parameterization of these models and the sophistication of modern quantization algorithms.
| Model | MMLU | ARC‑Challenge |
|---|---|---|
| FP16 baseline | 60.2 % | 49.8 % |
| AWQ | 60.0 % | 49.9 % |
| AutoRound‑sym | 60.1 % | 49.7 % |
| GPTQ | 59.4 % | 49.1 % |
| Bitsandbytes | 60.1 % | 49.8 % |
| AQLM (2‑bit) | 58.8 % | 48.6 % |
All accuracy numbers are averaged over three runs with identical random seeds to ensure consistency.
Inference Throughput (vLLM, tokens / s)
Here, the rubber meets the road. The raw speed reveals the crucial importance of purpose-built CUDA kernels. The generic kernels used by Bitsandbytes and AQLM pay a steep price in throughput, while the Marlin-accelerated contenders run at nearly full-precision velocity.
| Model | 1 stream | 8 streams |
|---|---|---|
| FP16 baseline | 322 | 1660 |
| AWQ | 319 | 1640 |
| AutoRound‑sym | 318 | 1632 |
| GPTQ | 313 | 1600 |
| Bitsandbytes | 206 | 1048 |
| AQLM (2‑bit) | 180 | 920 |
Choosing the Right Tool
The decision matrix is refreshingly clear, dictated by your specific constraints and objectives.
| Constraint | Recommendation |
|---|---|
| Production inference on modern GPUs | AWQ or AutoRound‑sym |
| Mature tooling / legacy stack support | GPTQ |
| Mixed‑precision fine‑tuning (QLoRA) | Bitsandbytes |
| VRAM < 6 GB or absolute min memory | AQLM 2‑bit (accept slower T / s) |
My default is now AWQ. Its setup is clean, the performance is top-tier, and its integration with inference servers like vLLM is seamless. The accuracy loss is effectively a rounding error for most applications. That said, for teams with established GPTQ pipelines, it remains a robust and entirely defensible choice.
What About 3‑Bit and Below?
The pursuit of sub-4-bit precision on an 8B model is often a case of diminishing, and frankly, misguided, returns. The marginal memory savings of 1-2 GB are typically paid for with a significant hit to perplexity and model stability.
The smarter play is not to further mutilate the 8B model, but to select a more compact architecture from the outset. Models like Gemma 2 (2B/9B) or Phi‑3 mini are designed for smaller footprints. Quantizing those models to INT4 is a far more rational path for targeting sub-10GB VRAM environments. The extreme end of quantization finds its true purpose on much larger models (70B+), where the absolute memory savings become strategically compelling, but that is a different war for a different day.
Conclusion
In 2024, quantization is no longer a niche academic experiment; it is a core competency for operationalizing LLMs. It is now entirely feasible to run a Llama 3.1 8B model on a single consumer GPU without a meaningful sacrifice in accuracy or speed. The key is to select the right tool for the job, applying the cold calculus of your specific requirements.
- Leverage AWQ or AutoRound‑sym for high-throughput, low-latency production workloads.
- Default to GPTQ when ecosystem maturity and stability are paramount.
- Rely on Bitsandbytes as the established path for memory-efficient fine-tuning.
- Deploy AQLM 2‑bit only when VRAM is the single most critical constraint, and you are willing to trade speed for it.
Using these techniques, I routinely serve multiple chat and retrieval-augmented generation pipelines from a single RTX 4090, with VRAM to spare for embedding management and other tasks. The path from theoretical capability to practical deployment has never been clearer. Your mileage may vary with hardware and driver specifics, but the principles hold.
Happy quantizing.
Further reading
- PyTorch – The foundational deep learning framework.
- Hugging Face Transformers – Provides access to thousands of pretrained models and tools for easy use.
- AWQ: Activation-aware Weight Quantization for LLMs (Paper, 2023)
- AutoGPTQ GitHub Repository
- Bitsandbytes GitHub Repository & Documentation
- Intel AutoRound GitHub Repository (NeurIPS 2023/2024)
- vLLM Project GitHub Repository – High-throughput LLM inference and serving engine.