Why I Wanted a Lean, Reasoning‑Savvy Model
Large language models keep smashing benchmarks, but at a cost that liquefies GPUs-and bank accounts. My goal was simple: run an open‑weight model that genuinely reasons, on hardware that fits under my desk. DeepSeek-R1’s training recipe isn’t just another paper; it’s a practical blueprint for exactly that.
1 Reinforcement Learning with Verifiable Rewards
1.1 From RLHF to RL without a Learned Critic
The standard RLHF playbook calls for a trainable reward model that learns human preferences. This introduces a whole other large network you have to train, babysit, and pray doesn’t get gamed by the policy. DeepSeek-R1 sidesteps this mess entirely. It leans on hard, deterministic reward functions
:
- Math & Code: Does the numeric answer match ground truth? Do the unit tests pass?
- Formatting: Are chain‑of‑thought tags present? Is the answer in a single language?
- Safety filters: Does the output avoid flagged content?
The beauty of this is that the reward is verifiable at inference time. There’s no gap between the training signal and deployment reality. No reward hacking. No pathological behavior emerging from a misspecified reward model.
1.2 The Theory Behind GRPO
We normally write the policy‑gradient objective as
where is the advantage function. PPO estimates
with a learned critic
and enforces a clipped surrogate loss for stability. GRPO drops
entirely and replaces the advantage with a group‑relative baseline:
where is the rule‑based reward for the i‑th sample in a mini‑batch drawn from yesterday’s policy
. The gradient update then becomes
with a KL penalty ensuring the policy doesn’t stray too far, too fast.
Why it works:
- Unbiasedness. Subtracting the batch mean
acts as a control variate, slashing variance without introducing bias.
- Simplicity. No bootstrap targets
means no temporal‑difference error, which means no catastrophic spirals of over- or undervaluation.
- Scalability. The memory footprint is just the policy and a buffer of recent checkpoints. Training 100‑B‑parameter policies becomes tractable.
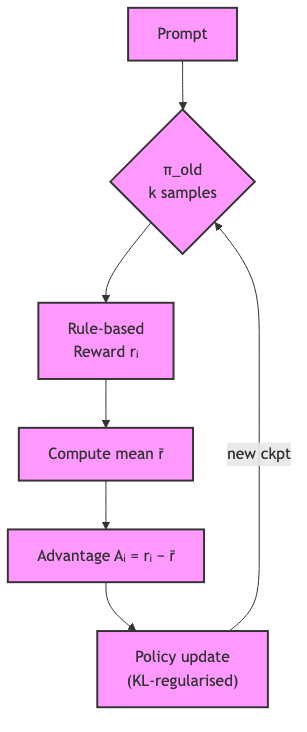
My read: GRPO is just REINFORCE with a clever twist. The baseline it subtracts is the average reward from the policy’s last checkpoint. This lag is crucial: it keeps the baseline fixed for the current batch, giving you an unbiased gradient estimate without the baggage of a full-blown critic network.
2 Cold‑Start SFT: Bridging the Gap Between Pre‑train and RL
Pure RL exploration, left to its own devices, tends to spew tangled half‑sentences in its early stages. A short cold‑start SFT-using just a few thousand curated chain‑of‑thought examples-serves two purposes:
- It anchors the first RL updates, keeping the policy tethered to coherent language instead of drifting into token soup.
- It juices the reward density. A model that already knows how to format an answer is far more likely to stumble into a correct one, giving the RL process a rich stream of positive signals from day one.
What’s fascinating, and something I’ve seen in playing with these models, is the emergence of an “aha moment.” After a certain point in training, often around a specific reward threshold, the model doesn’t just parrot reasoning steps. It appears to pause, self-correct, and genuinely find a better path. Sometimes it even writes “Aha, this is true…” as if discovering it for itself. Doesn’t it feel like a primitive spark of autonomous reasoning?
In information‑theoretic terms, the SFT is a form of intelligent constraint. It corrals the policy into a low‑entropy pocket of the vast parameter space, dramatically shrinking the search problem for the RL algorithm.
3 Distilling Genius: Teacher–Student Transfer Without RL
After the big model converges, the DeepSeek team generated ≈800k <(prompt, chain‑of‑thought, final answer)> triples. Training a smaller student on this data via plain supervised learning is just behaviour cloning-with a twist:
- Privileged information. The chain‑of‑thought is only visible during training. At inference, the student can still generate it, but it’s not a crutch.
- Compression ratio. A 685B‑parameter teacher distilling into a 7B student is a nearly 100× compression, yet reasoning accuracy climbs dramatically: +27% pass@1 on GSM‑8K for Qwen 2.5‑7B.
Theory digression: Distillation works because the teacher isn’t just giving answers; it’s providing a richer probability distribution over the solution space. This connects to the minimum description length principle. And the student isn’t just learning to match the final answer; it’s minimizing cross‑entropy to the entire reasoning chain, absorbing the intermediate states that the raw data hides.
| Student | Params | Training Steps | GSM‑8K |
HumanEval |
|---|---|---|---|---|
| Qwen 2.5‑7B | 7 B | 5 k | +27 % | +11 % |
| Llama 3.1‑8B | 8 B | 5 k | +23 % | +9 % |
| Qwen 2.5‑14B | 14 B | 5 k | +18 % | +16 % |
Metrics are relative gains over the respective base checkpoints.
4 The Final Hurdle: Taming the Model with 4‑Bit Quantisation
The basic idea of quantisation is simple: crush full-precision weights down to tiny integers
via
where is a scale factor. The trick is doing it without turning the model’s brain to mush. AutoRound is cleverer than naive quantisation. Instead of just rounding, it optimises
and the rounding decisions to minimise the Hessian‑weighted reconstruction error of each layer:
with the layer Hessian approximated from activations. This preserves the directions in weight space that are most critical for the model’s output.
- It uses a group size of 128, letting it isolate and handle outlier weights without needing to waste bits on the whole layer.
- Symmetric rounding keeps zero exactly representable, which simplifies fused kernels.
- It only needs calibration on 128 samples from the teacher to estimate the Hessian curvature.
The payoff is real. I’ve seen a performance drop of less than 0.3% on GSM-8K after quantising the Qwen‑7B‑R1 model. A trivial price for making it fit on a single consumer GPU.
# Minimal AutoRound script (4‑bit GPTQ)
from transformers import AutoModelForCausalLM, AutoTokenizer
from auto_round import AutoRound
import torch
BASE = "deepseek-ai/DeepSeek-R1-Distill-Qwen-7B"
model = AutoModelForCausalLM.from_pretrained(BASE, torch_dtype=torch.float16)
tokenizer = AutoTokenizer.from_pretrained(BASE)
quantizer = AutoRound(
model, tokenizer,
bits=4, group_size=128, sym=True,
nsamples=128, iters=256,
batch_size=4, gradient_accumulate_steps=2
)
quantizer.quantize()
quantizer.save_quantized("Qwen-7B-R1-gptq-4bit", format="auto_gptq", inplace=True)5 Hands‑On Reasoning Demo
Talk is cheap. Here’s a self-contained snippet that runs on a single RTX 4090, using about 10 GB of VRAM:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained(
"Qwen-7B-R1-gptq-4bit", device_map="auto")
# Qwen uses a bilingual tokenizer; add special tokens if missing.
tokenizer = AutoTokenizer.from_pretrained("Qwen-7B-R1-gptq-4bit")
def chat(prompt: str):
messages = [
{"role": "system", "content": "You are a precise mathematical assistant."},
{"role": "user", "content": prompt}
]
txt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inp = tokenizer([txt], return_tensors="pt").to(model.device)
out = model.generate(**inp, max_new_tokens=512)
return tokenizer.decode(out[0], skip_special_tokens=True)
print(chat(
"Three friends, Alice, Bob, and Carol, each have a favorite color: red, blue, or green. "
"1. Alice's favorite color is not red. "
"2. Bob's favorite color is not green. "
"3. Carol's favorite color is blue. "
"Deduce each person's favorite color. Show your reasoning."
))Expected abridged output
<think>
Let A, B, C be Alice, Bob, Carol.
Let R, Bl, G be Red, Blue, Green.
Given:
1. A != R (Alice's favorite color is not Red)
2. B != G (Bob's favorite color is not Green)
3. C = Bl (Carol's favorite color is Blue)
From (3), Carol's favorite color is Blue.
Since each person has a unique favorite color from {Red, Blue, Green}:
- Blue is taken by Carol.
- Remaining colors for Alice and Bob are Red and Green.
From (1), Alice's favorite color is not Red.
Since Blue is taken by Carol, and Alice's is not Red, Alice's favorite color must be Green.
Now, Green is taken by Alice.
The only remaining color for Bob is Red.
Let's check this against (2): Bob's favorite color is not Green. This is consistent, as Bob's favorite color is Red.
</think>
Alice's favorite color is Green.
Bob's favorite color is Red.
Carol's favorite color is Blue.6 Lessons & Outlook
- Deterministic rewards are criminally undervalued. When your task has verifiable right answers, using them as a reward signal is simpler, more stable, and gets rid of the pathological games that plague learned reward models.
- Show, Don’t Just Tell. Distilling from a teacher’s chain-of-thought is vastly more effective than training on raw data. You’re giving the student privileged access to the how, not just the what.
- Quantisation isn’t a dark art anymore. With Hessian-aware methods like AutoRound, shrinking models for commodity hardware is a solved problem. The “it’s too big to run” excuse is wearing thin.
The next moves on the board could involve mixing these verifiable rewards with semantic reward models to get the best of both worlds-transparent alignment and broad coverage. Or perhaps applying GRPO to multimodal tasks where rewards are still cheap to compute, like checking caption correctness with OCR. The blueprint is here; the interesting work is just getting started.