Key Take‑aways
| Why it matters | Details |
|---|---|
| Representations > Weights | Hidden states already encode rich semantics. Nudging them directly is more potent than adding new trainable weights to reroute them. |
| LoReFT Crushes PEFTs | On commonsense, instruction‑following, and GLUE, it uses 15× – 65× fewer parameters yet matches or surpasses LoRA, DoRA, and their ilk. |
| Training ≈ two lines of code | The open‑source stanfordnlp/pyreft wraps any Hugging Face model, keeping the base weights frozen. |
| Negligible Inference Overhead | Activations are edited at a handful of prefix/suffix positions. Generation latency barely budges. |
| Composable Sub‑spaces | Learn separate low‑rank edits for detox, domain style, or reasoning. Combine them on the fly. |
1 The Gilded Cage of Parameter Efficiency
For the past year, I’ve burned countless GPU-hours chasing diminishing returns in the world of parameter-efficient fine-tuning (PEFT). LoRA, DoRA, AdaLoRA… the list of clever tricks grows longer, but they all operate under the same dogma: they inject new weights into the model’s backbone. It’s an arms race of architectural bolt-ons, each promising a slightly cheaper way to teach an old model new tricks.
Stanford’s ReFT: Representation Finetuning for Language Models upends this dogma. It poses a question so fundamental it feels almost heretical: if a model’s residual stream already represents concepts, why not edit those representations directly, instead of painstakingly learning new weights to route information the long way around?
That single insight-change the message, not the messenger-unlocks brutal efficiency.
Analogy. Think of a city’s subway system. The dominant PEFT methods are like adding a handful of new, expensive tracks (weights) so trains can take a detour. ReFT keeps the tracks fixed but surgically tweaks the signal lights (activations) at key stations, guiding existing trains to the correct destination with minimal fuss.
2 The Lay of the Land: From PEFT to ReFT
| Aspect | Classical PEFT (LoRA/Adapters) | Representation Finetuning (ReFT) |
|---|---|---|
| What Learns? | A subset of weights (≈ 0.1% – 10%) | A function Φ that overwrites hidden activations |
| Scope | Every time-step & token | Selected (layer ℓ, position p) pairs only |
| Merge-ability | Can be merged for zero-overhead inference | Requires a light activation hook (≈ µ-seconds) |
| Interpretability | Indirect-weights ≠ semantics | Direct-edits live in the representation space |
The flagship variant is Low-rank Linear-Subspace ReFT (LoReFT). Let’s dissect it.
3 LoReFT Under the Hood
3.1 The Core Mathematics
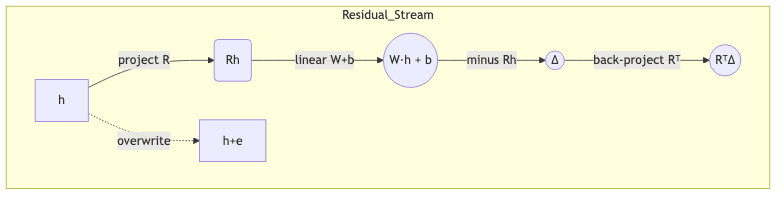
At a given layer ℓ, let the hidden vector for token p be . LoReFT injects an intervention of the form:
where
- INLINE_MATH_{1} has orthonormal rows defining an INLINE_MATH_{2}-dimensional sub-space (INLINE_MATH_{3}).
- INLINE_MATH_{4} and INLINE_MATH_{5} are the only learnable parameters.
Everything happens inside the subspace defined by INLINE_MATH_{6}; components orthogonal to it remain untouched. Consequently, LoReFT’s parameter count is a rounding error:
With (Llama-2 7B) and a rank
, this is ≈ 65 kB. That’s not a typo. It’s smaller than a single LoRA adapter layer.
3.2 Prefix/Suffix Positions
Rather than meddling with every token, LoReFT surgically intervenes on:
- a prefix of length
(usually 2 tokens) and
- a suffix of length
0 (also 2 tokens)
within each input sequence. These become the knobs the optimizer can twist. Empirically, this is enough for gradients to propagate useful signals throughout the network while keeping the computational cost trivial.
3.3 Choosing Where to Intervene
The paper reports a robust heuristic:
- Middle transformer layers (50% – 70% depth) give the best bang-for-buck. Early layers are too syntactic; late layers are too saturated with task-specific semantics.
- Positions 1 & 2 (prefix) exert global influence; suffix tokens help stabilize generation toward the end.
- Increasing rank
My Advice. Start with
layer = num_hidden_layers // 2andlow_rank_dimension = 4. Only tune up if your validation metrics show clear headroom.
4 Hands-On: The Bare-Metal Implementation
Below is a minimal training script. We keep the base Llama-2 weights frozen and optimize only the LoReFT parameters with plain AdamW.
import torch, transformers, datasets
from pyreft import ReftConfig, get_reft_model, LoreftIntervention
# 1️⃣ Load base model (bfloat16 saves VRAM)
base_model = "meta-llama/Llama-2-7b-hf"
model = transformers.AutoModelForCausalLM.from_pretrained(
base_model,
torch_dtype=torch.bfloat16,
device_map="auto",
attn_implementation="flash_attention_2",
)
# 2️⃣ Attach a rank-4 LoReFT intervention at layer 19
reft_config = ReftConfig(representations={
"layer": 19,
"component": "block_output", # residual stream after MLP
"intervention": LoreftIntervention(
embed_dim=model.config.hidden_size,
low_rank_dimension=4,
)
})
model = get_reft_model(model, reft_config)
print(model.trainable_parameters()) # ~65 kB
# 3️⃣ Dataset & Trainer
ultra_feedback = datasets.load_dataset("HuggingFaceH4/ultrachat_200k", split="train[:10%]")
trainer = transformers.Trainer(
model,
args=transformers.TrainingArguments(
output_dir="loreft-llama2-chat",
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
num_train_epochs=3,
learning_rate=2e-4,
fp16=False, bf16=True,
),
train_dataset=ultra_feedback.map(lambda x: {"input_ids": x["prompt_ids"]}),
)
trainer.train()Inference is a drop-in replacement. model.generate() just works because PyReFT registers the necessary activation hook during forward passes. No fuss.
5 Where the Rubber Meets the Road
5.1 Benchmarks & Metrics
| Category | Datasets | Metric |
|---|---|---|
| Commonsense | HellaSwag, PIQA, OpenBookQA, WinoGrande, StoryCloze | Accuracy |
| Arithmetic Reasoning | Add‑Sub, Multi‑Arith, SingleOp126 | Exact Match |
| Instruction Following | UltraFeedback, AlpacaEval | Win-rate vs GPT-4 |
| Natural Language Understanding | GLUE (all 9 tasks) | Aggregate Score |
Each experiment fine-tunes only 1% of the training data used for full-parameter baselines, mirroring LoRA’s standard practice.
5.2 Results Highlights
| Model | Params Finetuned | HellaSwag | UltraFeedback | GLUE (base) |
|---|---|---|---|---|
| LoReFT (Llama-2 7B) | 0.03% | 82.5 | +3.2 pp | 85.0 |
| LoRA (rank 8) | 0.14% | 81.0 | +0.1 pp | 84.5 |
| DoRA (adapter) | 0.26% | 80.9 | −0.5 pp | 84.6 |
| Full Fine-tune | 100% | 82.7 | +4.1 pp | 86.1 |
pp = percentage points; scores averaged over three random seeds.
The takeaway is stark. LoReFT nearly matches a full fine-tune while being less than 1/3000th its size in trainable parameters.
5.3 Runtime Analysis
- FLOPs Overhead. For Llama-2 7B, the extra matrix multiplies add < 0.15% FLOPs per token.
- Latency. On a single A100-40GB, median generation time increases by a mere 7 ms for a 256-token output.
- Memory. Only the
6 The Doctrine: When to Use ReFT
6.1 Where to Point this Cannon
- Edge Personalization. Ship a frozen backbone to phones or browsers; download user-specific LoReFT patches measured in kilobytes.
- Multi-skill Orchestration. Maintain separate edits for style, safety, and task-specialization. Toggle them at inference.
- Fine-grained Interpretability. Because edits live in vector space, you can probe them with causal tracing, à la Anthropic.
6.2 Where It Misfires
- Extremely Long Generations. The influence of prefix tokens may decay. Consider repeating interventions mid-sequence.
- Deployments Requiring Weight-Merging. If you must export a standalone model with zero hooks, LoRA-style merges are still simpler.
- Small-scale Tasks (< 10k examples). The additional hyperparameters (layer, p, s, r) can be brittle in tiny data regimes.
7 The Next Frontier
- Automated Sub-space Discovery. Use Bayesian optimization or RL to search the intervention space
- Cross-modal ReFT. Vision-language models like LLaVA share the same residual stream. Edit it once, and you could influence both image and text components.
- Hierarchical Interventions. Stack multiple LoReFTs with increasing ranks to approximate non-linear manifolds.
- Theoretical Guarantees. Can we bound representation drift outside
8 Practical Tips & Tricks
| Pain Point | Remedy |
|---|---|
| Validation loss flatlines | Increase prefix length to 4 or try a deeper layer (later residuals hold more global context). |
| Overfits quickly | Lower the rank to 2 or freeze the bias term |
| Generation diverges mid-sequence | Add a midfix intervention at token ≈ sequence_length // 2. |
Hugging Face Trainer complains about no params |
Ensure you pass the wrapped model from get_reft_model, not the base model. |
9 The Bottom Line
LoReFT convinces me that PEFT has entered its second era: we are moving from tweaking weights to tweaking representations. For hobbyists, this means larger, more powerful LLMs are back on the menu. For industry, it opens the door to on-device adaptation measured in kilobytes, not gigabytes.
Since adopting ReFT, I start every new fine-tuning task with it. Only if validation refuses to budge do I fall back to a higher-rank LoRA. So far, that hasn’t happened.
Drop me a line on Twitter (@ra_kalra) or LinkedIn (/rakkalra) if you build something cool.
Further reading
- Original paper: ReFT: Representation Finetuning for Language Models (arXiv 2024).
- PyReFT library: https://github.com/stanfordnlp/pyreft.
- Lin et al. LoRA: Low-Rank Adaptation of Large Language Models (ICLR 2021).
- Sato et al. DoRA: Weight-Decomposed Low-Rank Adaptation (NeurIPS 2023).
- Barsu et al. RED: Residual Decomposition for Parameter-Efficient Transfer (ACL 2024).